After posting the article “Choose link aggregation over Multi-NIC vMotion” I received a couple of similar questions. Pierre-Louis left a comment that covers most of the questions. Let me use this as an example and clarify how vMotion traffic flows through the stack of multiple load balancing algorithms and policies:
A question relating to Lee’s post. Is there any sense to you to use two uplinks bundled in an aggregate (LAG) with Multi-NIC vMotion to give on one hand more throughput to vMotion traffic and on the other hand dynamic protocol-driven mechanisms (either forced or LACP with stuff like Nexus1Kv or DVS 5.1)?
Most of the time, when I’m working on VMware environment, there is an EtherChannel (when vSphere < v5.1) with access datacenter switches that dynamically load balance traffic based on IP Hash. If i'm using LAG, the main point to me is that load balancing is done independently from the embedded mechanism of VMware (Active/Standby for instance).
Do you think that there is any issue on using LAG instead of using Active/Standby design with Multi-NIC vMotion? Do you feel that there is no interest on using LAG over Active/Standby (from VMware point of view and for hardware network point of view)?
Pierre-Louis takes a bottom-up approach when reviewing the stack of virtual and physical load-balancing policies and although he is correct when stating that network load balancing is done independently from VMware’s network stack, it does not have the impact he thinks it has. Lets look at the starting point of vMotion traffic and how that impacts both the flow of packets and utilization of links. Please read the articles “Choose link aggregation over Multi-NIC vMotion” and “Designing your vMotion network” to review some of the requirements of Multi-NIC vMotion configurations
Scenario configuration
Lets assume you have two uplinks in your host, i.e. two physical NICs per ESX host. Each vmnic used by the VMkernel NIC (vmknic) is configured as active and both links are aggregated in a Link Aggregation Group (LAG) (EtherChannel in Cisco terms).
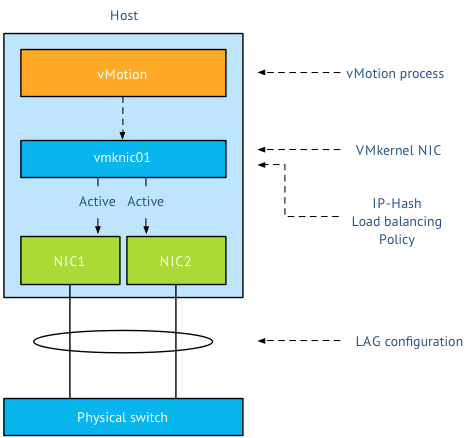
First thing I want to clarify that the active/standby state of a vmknic is static and is controlled by the user, not a Load-Balancing policy. When using a LAG, both vmknics need to be configured active, as the load balancing policy needs to be able to send traffic across both links. Duncan explains the impact when using Standby NICs in an IP-Hash configuration.
Load balancing stack
A vMotion is initiated on host-level; therefor the first load balancer that comes in to play is vMotion itself. Then the portgroup load balancing policy will make a decision followed by the physical switch. Load balancing done by the physical switch/LAG is the last element in this stack.
Step 1: vMotion load balancing, this is done on the application layer and it is vMotion process that selects which VMkernel NIC is used. As you are using a LAG and two NICs, only one vMotion VMkernel NIC should exist. The previous mentioned article explains why you should designate all vmnics as active in a LAG. By using one vmknic enabled for vMotion, vMotion is unable to load-balance at vmknic level and sends all the traffic to the single vmknic.
Step 2: Next step is the load-balancing policy; IP-Hash will select one NIC after it hashes both source and destination IP. That means that this vMotion operation will use the same NIC until the vMotion operation is complete. It does not use two links, as a vMotion operation connection is setup by two VMkernel NICs and thus two IP-addresses (source IP address and destination IP). As IP-Hash determines the vmknic, traffic will be send out across the physical link.
Step 3: is at the physical switch layer and determines which port to use to connect to a NIC of the destination host. Once the physical switch receives the packet, the load balancer of the LAG configuration comes into play. The physical switch determines which path to take to the destination host according to utilization or availability of a link. Each switch vendor has different types of load balancers, too many to describe, the article “Understanding EtherChannel Load Balancing and Redundancy on Catalyst Switches” describes the different load balancing operations within the Cisco Catalyst switch family.
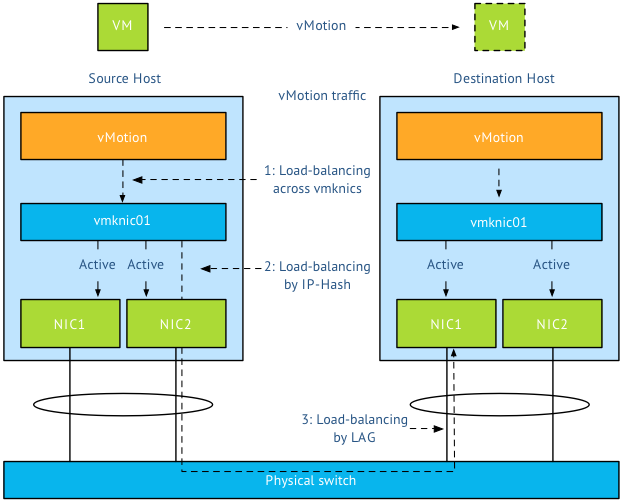
In short:
Step 1 Load balancing by vMotion: has no direct control over which physical NICs are used, it load balances across available multiple vmknics.
Step 2 Load balancing by IP-HASH: Outgoing connection is hashed based on its source and destination IP address; hash is used to select a physical NIC to use for network transmissions.
Step 3 Load balancing by LAG: Physical switch connected to destination performs the hash to choose which physical NIC to send incoming connection to.
To LAG or not to LAG, that’s the question
By using a LAG configuration for vMotion traffic, you are limited to the available bandwidth of a single uplink per vMotion operation as only one uplink is used per vMotion operation. A Multi-NIC vMotion configuration balances vMotion traffic across both VMkernel NICs. It load balances traffic for a single vMotion operation as well as multiple concurrent vMotion operations across the links. Let me state that differently; It is able to use the bandwidth of two uplinks for both a single vMotion operation, as well as multiple vMotion operations. With Multi-NIC vMotion you will get a more equal load balance distribution than with any load-balancing policy operating at NIC level.
I would always select multi-NIC vMotion over LAG. A LAG requires strict configuration on both virtual level as physical level. It’s a complex configuration on both technical and political level. Multiple departments need to be involved and throughout my years as an architect I seen many infrastructures fail due to inter-department politics. Troubleshooting a LAG configuration is not an easy task in an environment where there are communication-challenges between the server and the network department. Therefor I strongly prefer not to use LAG in a virtual infrastructure
Multiple single uplinks can be used to provide more bandwidth to the vMotion process and other load-balancing policies available on the distributed switch keep track of link utilization (LBT). It’s less complex, and in most cases give you better performance.
I noticed in your diagrams that you only have a single vmknic per host used for vMotion. What is the difference if I take your configuration, but create TWO vmknics on each host for vMotion?
Do bad things happen?
Hi Frank,
Thanks for your answer.
I quite agree with the fact that LAG can drive many politics challenges between server and network departments, yes, maybe you’re right. But I’m always working on different client topologies, with different server and network environment (blade servers, rack severs, …) and believe me (or not), most of the time, VMware engineers don’t know that they have the opportunity to use a consistent access policy between hypervisor and hardware switches (LAG for example). Furthermore, you can’t imagine the amount of issues we are encountering in datacenters where A/S scenarios are deployed and not maintained… Especially in Blade chassis environment where you can’t have all the time consistent VM to Core Networking/Firewalling topologies.
The point that Doug is highlighting is exactly the first thing that raises me questions when I was reading your topic. What would be the load balancing behavior with and other vmknic declared as vMotion enabled (ie Multi-NIC vMotion)?
To be clear, I didn’t have the time those days to test it on our lab equipments, but I think Step 1 in your path would be changed, don’t you think? You should be able to load balance vMotion traffic to two different vmknics for one vMotion operation or two simultaneous operations, no? And in that way, one vMotion traffic could reach physical switch using pnic1 and the other through pnic2 (if we consider two different IP addresses for vmknics used by vMotion). And finally, you should utilize your two physical links on both sides of the network and on both hypervisors (both configured with 2 vmknics for vMotion).
What I totally agree with your conclusion is you can not be sure that you will get a good sharing on your links in the same LAG. But it deserve to be validated I think :-)…
I understand the question of Doug and I thought of that scenario when I was writing the article, but after reviewing the outcome I would never propose such as construct to the customer.
vMotion is not aware of the physical NIC structure during load balance decisions and assumes that one NIC backs the VMkernel NIC. If we use a LAG, both NICs should be configured as active. A second vmkernel NIC has a different IP address therefor the hashing could result in a different uplink selection. Now it’s imperative to understand the distinction between using a Multi-NIC vMotion backed by a LAG and Multi-NIC vMotion backed by two separate vNICs. The IP-HASH could use the same physical link for vMotion operations and saturate a link leaving the other link idle, while the Multi-NIC vMotion with separate links does not. The premise of vMotion to load balance at vMotion layer with a single link backing allows vMotion to understand the amount of bandwidth being send over a single vmknic and therefor can make adjustments accordingly. By using IP-hash and allowing an “external” load balance policy make decisions, is comparable to driving blindfolded relying on the instructions of a back seat passenger. It’s a nice scenario for academic purposes, but during my career as Architect I always chose for proven technology with a guaranteed outcome. I never went for options that could, should, maybe or eventually work as well. Multi-NIC Active Passive provides a predicable load balance, while Multi-NIC LAG does not, therefor I would go for a Multi-NIC vMotion configuration with two separate uplinks in an active / standby configuration.
I understand that sometimes your hands are tied. I’ve been to customer sites where they believed in LAG configurations, but by thoroughly explaining the way LAG works in a virtual infrastructure without a strict outcome of transmissions patterns (it’s a random stream originating from many virtual machine opposed to a physical box with one to many connections) almost every customer broke down LAG links.
After reading this and talking a bit to Frank, I think I understand how this can cause “interesting” things to happen: using LACP and balancing at the switch level rather than allowing the hypervisor to configure static binding of a vmknic to a specific pnic, you remove the determinism from the configuration. In my book, that’s the bad kind of “interesting.”
Ultimately, you *may* get the desired behavior: each vMotion-enabled vmknic hashes out and is bound to its own pnic — OR, the hashing could end up associating all vmknics with the same pnic. The problem is that you won’t know until it happens, and you just have to roll the dice again. I’m no network guy, but I am not aware of a way to pin a MAC address to a specific uplink in a LAG… not in a way that doesn’t degrade availability.
Thanks for the write-up and conversation, Frank!
…you remove the determinism from the configuration.
Doug that line hits the nail on the head, that was very well put!
Gonna steal that for presentations 🙂