This is part 3 of the memory deep dive. This is a series of articles that I wrote to share what I learned while documenting memory internals for large memory server configurations. This topic amongst others will be covered in the upcoming FVP book. The memory deep dive series:
Part 1: Memory Deep Dive Intro
Part 2: Memory subsystem Organisation
Part 3: Memory Subsystem Bandwidth
Part 4: Optimizing for Performance
Part 5: DDR4 Memory
Part 6: NUMA Architecture and Data Locality
Part 7: Memory Deep Dive Summary
Memory Subsystem Bandwidth
Unfortunately, there is a downside when aiming for high memory capacity configurations and that is the loss of bandwidth. As shown in Table 1, using more physical ranks per channel lowers the clock frequency of the memory banks. As more ranks per DIMM are used the electrical loading of the memory module increases. And as more ranks are used in a memory channel, memory speed drops restricting the use of additional memory. Therefore in certain configurations, DIMMs will run slower than their listed maximum speeds.
Let’s use an Intel Xeon E5 v2 (Ivy Bridge) as an example. The Intel Xeon E5 is one of the most popular CPUs used in server platforms. Although the E5 CPU supports 3 DIMMs per channel, most servers are equipped with a maximum of two DIMMs per channel as the memory speed decreases with the use of the third bank.
| Vendor | DIMM Type | 1 DPC | 2 DPC | 3 DPC |
| HP | 1R RDIMM | 1866 MHz | 1866 MHz | 1333 MHz |
| HP | 2R RDIMM | 1866 MHz | 1866 MHz | 1333 MHz |
| Dell | 4R RDIMM | 1333 MHz | 1066 MHz | N/A |
| HP | 4R LRDIMM | 1866 MHz | 1866 MHz | 1333 MHz |
Table 1: DDR3 Memory channel pairing impact on memory bandwidth
Source:
HP Smart Memory
Dell R720 12G Memory Performance Guide
Relation of bandwidth and frequency
As is often the case in competitive markets in and out of technology, memory vendors use a lot of different terminology. Sometimes we see MHz indicate bandwidth, other times transfer rate per second (MT/s). Typically, the metric that resonates the most is the bandwidth per second in Megabytes. Some examples of popular designations of DDR modules:
| DIMM Type | Memory Clock | I/O Bus Clock | Data Rate | Module Name | Peak Transfer Rate |
| DDR3-800 | 100 MHz | 400 MHz | 800 MT/s | PC-6400 | 6400 MB/s |
| DDR3-1066 | 133 MHz | 533 MHz | 1066 MT/s | PC-8500 | 8533 MB/s |
| DDR3-1333 | 166 MHz | 666 MHz | 1333 MT/s | PC-10600 | 10600 MB/s |
| DDR3-1600 | 200 MHz | 800 MHz | 1600 MT/s | PC-12800 | 12800 MB/s |
| DDR3-1866 | 233 MHz | 933 MHz | 1866 MT/s | PC-14900 | 14933 MB/s |
| DDR3-2133 | 266 MHz | 1066 MHz | 2133 MT/s | PC-17000 | 17066 MB/s |
DDR stands for double data rate which means data is transferred on both the rising and falling edges of the clock signal. Meaning that the transfer rate is roughly twice the speed of the I/O bus clock. For example, if the I/O bus clock runs at 800 MHz per second, then the effective rate is 1600 mega transfers per second (MT/s) because there are 800 million rising edges per second and 800 million falling edges per second of a clock signal running at 800 MHz.
The transfer rate refers to the number of operations transferring data that occur in each second in the data-transfer channel. Transfer rates are generally indicated by MT/s or gigatransfers per second (GT/s). 1 MT/s is 106 or one million transfers per second; similarly, 1 GT/s means 109, or one billion transfers per second.
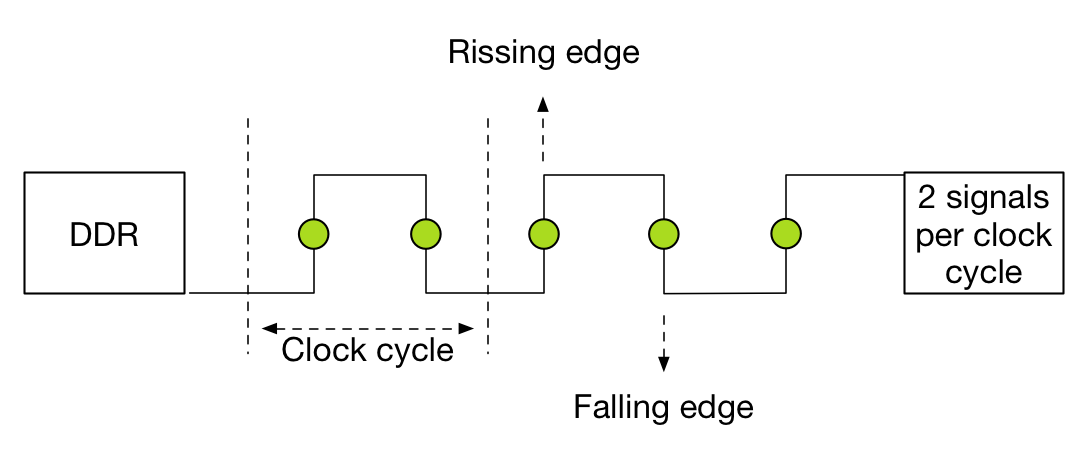
Please be aware that sometimes MT/s and MHz are used interchangeably. This is not correct! As mentioned above, the MT/s is normally twice of the I/O clock rate (MHz) due to the sampling, one transfer on the rising clock edge, and one transfer on the falling. Therefore it’s more interesting to calculate the theoretical bandwidth. The transfer rate itself does not specify the bit rate at which data is being transferred. To calculate the data transmission rate, one must multiply the transfer rate by the information channel width. The formula for a data transfer rate is:
Channel width (bits/transfer) × transfers/second = bits transferred/second
This means that a 64-bit wide DDR3-1600 DIMM can achieve a maximum transfer rate of 12800 MB/s. To arrive at 12800 MB/s multiply the memory clock rate (200) by the bus clock multiplier (4) x data rate (2) = 1600 x number of bits transferred (64) = 102400 bits / 8 = 12800 MB/s
Design considerations
The most popular DDR3 frequencies are DIMMs operating 1600 MHz, 1333 MHz, and 1066 MHz. Many tests published on the net show on average 13% decline in memory bandwidth when dropping down from 1600 MHz to 1333 MHz. When using 3 DPC configuration, bandwidth drops down 29% when comparing 1066 MHz with 1600 MHz. It’s recommended to leverage LRDIMMS when spec’ing servers with large-capacity memory configurations.
If you want to measure the memory bandwidth on your system, Intel released the tool Intel® VTune™ Performance Analyzer.
Low Voltage
Low Voltage RAM is gaining more popularity recently. DDR3 RDIMMs require 1.5 volts to operate, low voltage RDIMMS require 1.35 volts. While this doesn’t sound much, dealing with hundreds of servers each equipped with 20 or more DIMM modules this can become a tremendous power saver. Unfortunately using less power results in a lower memory clock cycle of the memory bus. This leads to reduced memory bandwidth. Table xyx shows the memory bandwidth of low voltage DDR3 DIMMs compared to 1.5V DIMM rated voltage.
| DIMM Type | Ranking | Speed | 1 DPC 1.35V | 1 DPC 1.5V | 2 DPC 1.35V | 2 DPC 1.5V | 3 DPC 1.35V | 3 DPC 1.5V |
| RDIMM | SR/DR | 1600 MHz | N/A | 1600 | N/A | 1600 | N/A | 1066 |
| RDIMM | SR/DR | 1333 MHz | 1333 | 1333 | 1333 | 1333 | N/A | 1066 |
| RDIMM | QR | 1333 MHz | 800 | 1066 | 800 | 800 | N/A | N/A |
| LRDIMM | QR | 1333 MHz | 1333 | 1333 | 1333 | 1333 | 1066 | 1066 |
Table 2: Rated voltage and impact on memory bandwidth
Low voltage RDIMMs cannot operate at the highest achievable speed as their 1.5V counterparts. Frequency fall-off is dramatic with Quad-ranked Low voltage operating at 800 MHz.
ECC Memory
Error Checking and Correction (ECC) memory is essential in enterprise architectures. With the increased capacity and the speed at which memory operates, memory reliability is an utmost concern.
DIMM Modules equipped with ECC contain an additional DRAM chip for every eight DRAM chips storing data. The memory controller to exploits is an extra DRAM chip to record parity or use it for error-correcting code. The error-correcting code provides single-bit error correction and double-bit error detection (SEC-DED). When a single bit goes bad, ECC can correct this by using the parity to reconstruct the data. When multiple bits are generating errors, ECC memory detects this but is not capable to correct this.
The trade-off for the protection of data loss is cost and performance reduction. ECC may lower memory performance by around 2–3 percent on some systems, depending on application and implementation, due to the additional time needed for ECC memory controllers to perform error checking.
Please note that ECC memory cannot be used in a system containing non-ECC memory.
Up next, part 4: Optimizing for Performance
The memory deep dive series:
Part 1: Memory Deep Dive Intro
Part 2: Memory subsystem Organisation
Part 3: Memory Subsystem Bandwidth
Part 4: Optimizing for Performance
Part 5: DDR4 Memory
Part 6: NUMA Architecture and Data Locality
Part 7: Memory Deep Dive Summary
Great article, Frank. The question I always received from my customers was how the different memory speeds translate into workload performance. My answer is the classic, “it depends,” which is generally true since a memory-heavy workload will be more impacted by speed of that resource than one which may be, for example, CPU- or IO-bound.
Still, if I take a memory-intensive workload and run it on one system with a memory clock speed of 1066 MHz, and then on another at 1333 MHz, what’s the expected performance benefit? Is it going to be worth the cost of running a greater number of systems with less, faster RAM, or can I take the hit and run fewer systems with greater RAM density?
Do you have any thoughts on that? I never have been able to quantify it myself.
This clarifies by queries regarding how 1066 MHz x8 mb/s can be transferred in a 64 bit width channel and so on. Great article …
Got to know about mt/s and get/s and rise and fall where data are transferred in both rising and falling edges and how memory channels allocates bandwidth for any transfer..
Overall great read and thank you