#47 – How VMware accelerates customers achieving their net zero carbon emissions goal
In episode 047, we spoke with Varghese Philipose about VMware’s sustainability efforts and how they help our customers meet...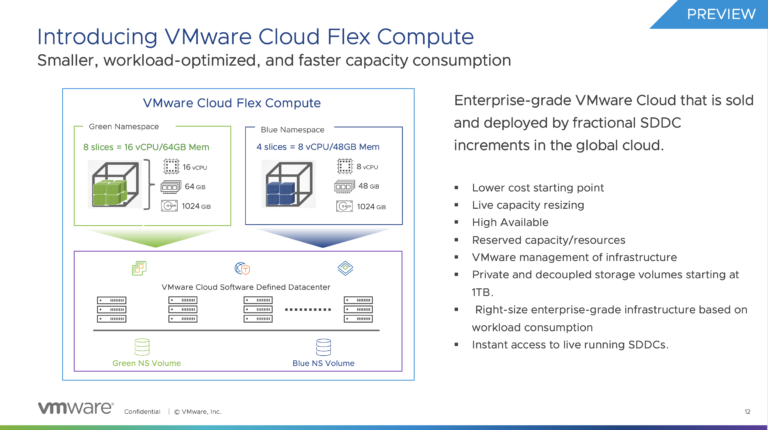
#46 – VMware Cloud Flex Compute Tech Preview
We’re extending the VMware Cloud Services overview series with a tech preview of the VMware Cloud Flex Compute service....
VMware Cloud Services Overview Podcast Series
Over the last year, we’ve interviewed many guests, and throughout the Unexplored Territory Podcast show, we wanted to provide...
Research and Innovation at VMware with Chris Wolf
In episode 042 of the Unexplored Territory podcast, we talk to Chris Wolf, Chief Research and Innovation Officer of...
Gen AI Sessions at Explore Barcelona 2023
I’m looking forward to next week’s VMware Explore conference in Barcelona. It’s going to be a busy week. Hopefully, I will...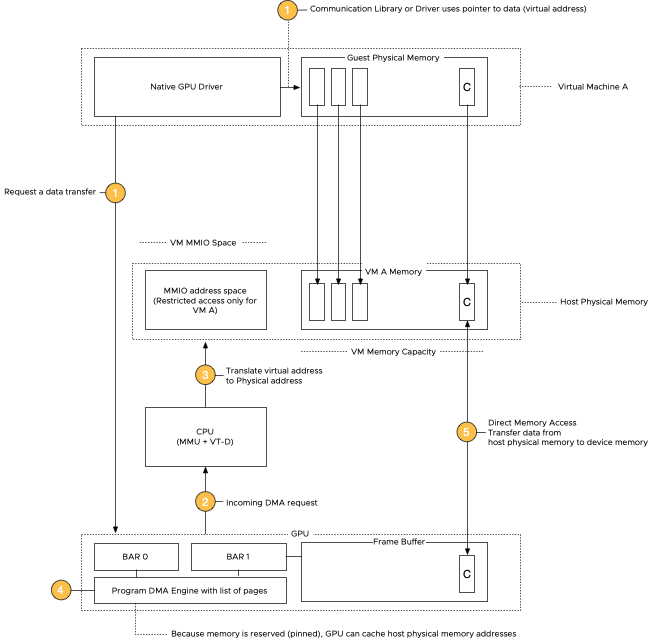
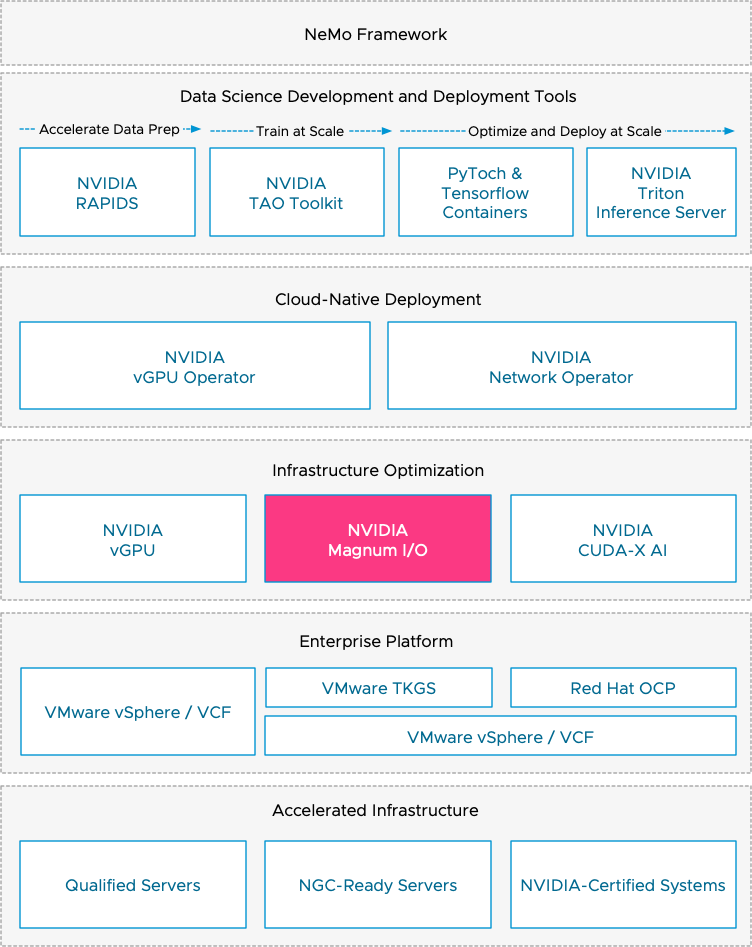
vSphere ML Accelerator Spectrum Deep Dive – ESXi Host BIOS, VM, and vCenter Settings
To deploy a virtual machine with a vGPU, whether a TKG worker node or a regular VM, you must enable some...