The vSphere 7.0 U2a update released on April 27th introduces the new VM service and VM operator. Hidden away in what seems to be a trivial update is a collection of all-new functionalities. Myles Gray has written an extensive article about the new features. I want to highlight the administrative controls of VM classes of the VM service.
VM Classes
What are VM classes, and how are they used? With Tanzu Kubernetes Grid Service running in the Supervisor cluster, developers can deploy Kubernetes clusters without the help of the Infra Ops team. Using their native tooling, they specify the size of the cluster control plane and worker nodes by using a specific VM class. The VM class configuration acts a template used to define CPU, memory resources and possibly reservations for these resources. These templates allow the InfraOps team to set guardrails for the consumption of cluster resources by these TKG clusters.
The supervisor cluster provides twelve predefined VM classes. They are derived from popular VM sizes used in the Kubernetes space. Two types of VM classes are provided, a best-effort class and a guaranteed class. The guaranteed class edition fully reserves its configured resources. That is, for a cluster, the spec.policies.resources.requests match the spec.hardware settings. A best-effort class edition does not, that is, it allows resources to be overcommitted. Let’s take a closer look at the default VM classes.
| VM Class Type | CPU Reservation | Memory Reservation |
| Best-Effort-‘size’ | 0 MHz | 0 GB |
| Guaranteed-‘size’ | Equal to CPU config | Equal to memory config |
There are eight default sizes available for both VM class types. All VM classes are configured with a 16GB disk.
| VM Class Size | CPU Resources Configuration | Memory Resources Configuration |
| XSmall | 2 | 2 Gi |
| Small | 2 | 4 Gi |
| Medium | 2 | 8 Gi |
| Large | 4 | 16 Gi |
| XLarge | 4 | 32 Gi |
| 2 XLarge | 16 | 128 Gi |
| 4 XLarge | 16 | 128 Gi |
| 8 XLarge | 32 | 128 Gi |
Burstable Class
One of the first things you might notice if you are familiar with Kubernetes is that the default setup is missing a QoS class, the Burstable kind. Guaranteed and Best-Effort classes are located at both ends of the spectrum of reserved resources (all or nothing). The burstable class can be anywhere in the middle. I.e., the VM class applies a reservation for memory and or CPU. Typically, the burstable class is portrayed to be a lower-cost option for workloads that do not have a sustained high resource usage. Still, I think the class can play an essential role in no-chargeback cloud deployments.

To add burstable classes to the Supervisor Cluster, go to the Workload Management view, select the Services tab, and click on the manage option of the VM Service. Click on the “Create VM Class” option and enter the appropriate settings. In the example below, I entered 60% reservations for both CPU and memory resources, but you can set independent values for those resources. Interestingly enough, no disk size configuration is possible.
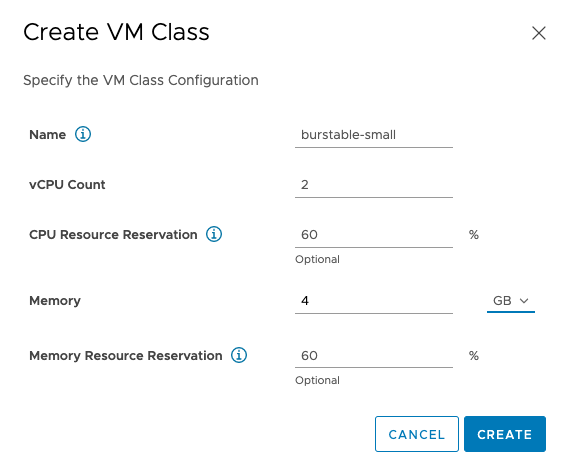
Although the VM Class is created, you have to add it to a namespace to be made available for self-service deployments.
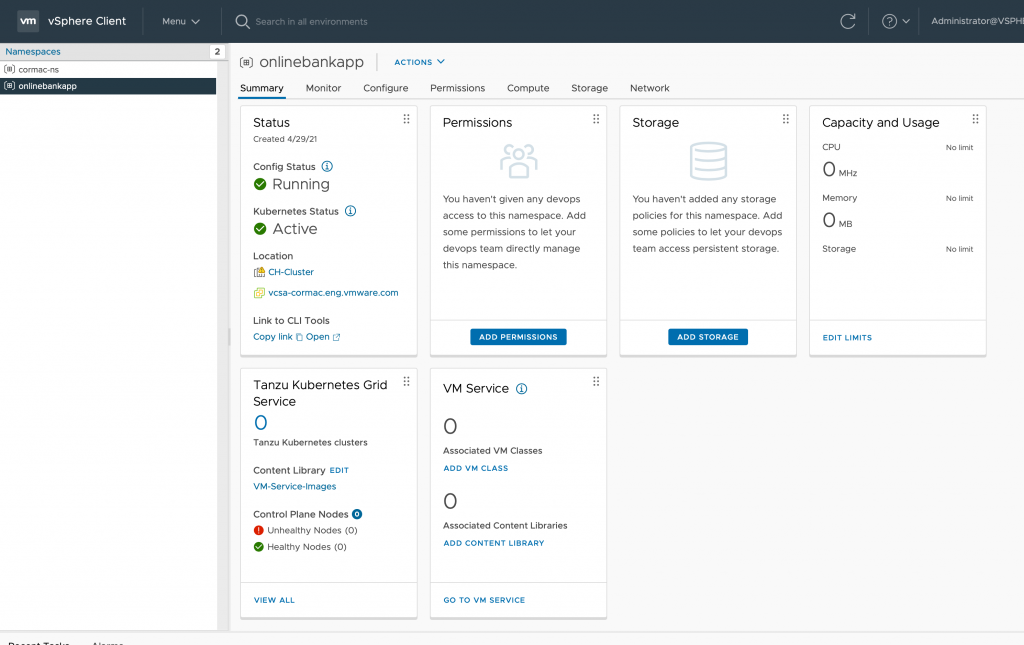
Click on “Add VM Class” in the VM Service tile. I modified the view by clicking on the vCPU column, to find the different “small” VM classes and selected the three available classes.
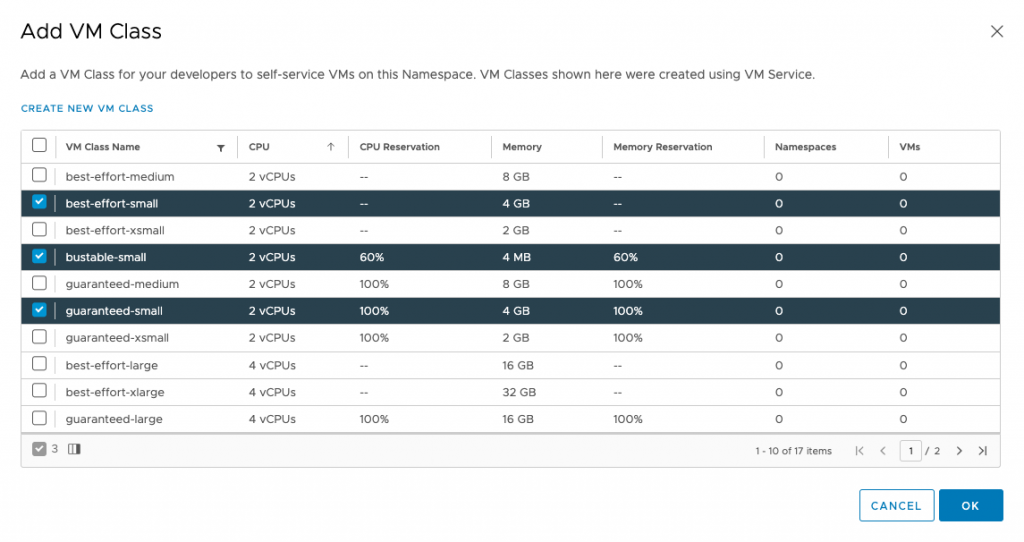
After selecting the appropriate classes, click ok. The Namespace Summary overview shows that the namespace offers three VM classes.
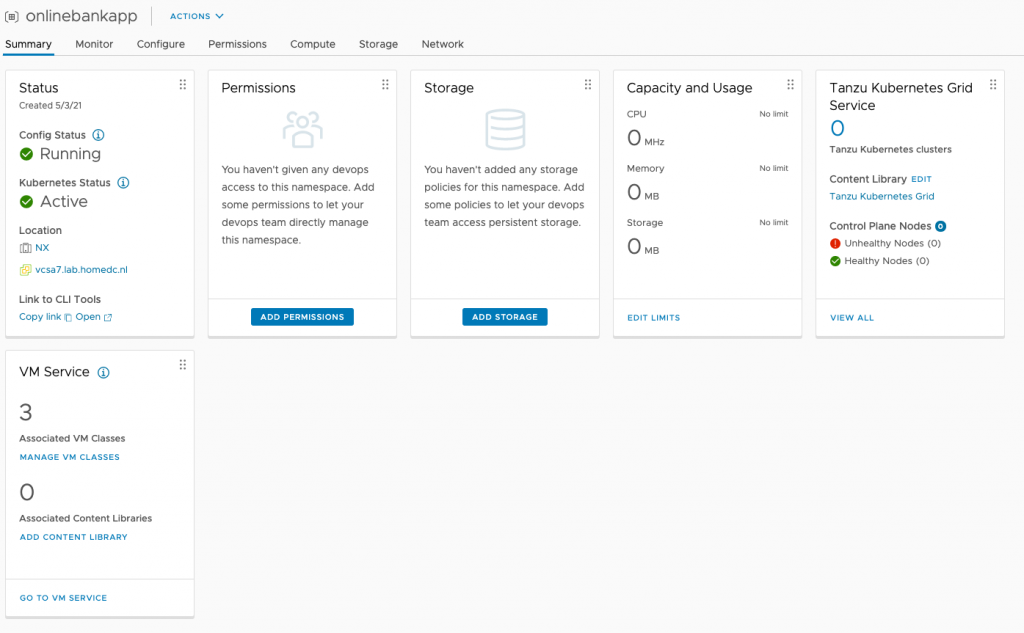
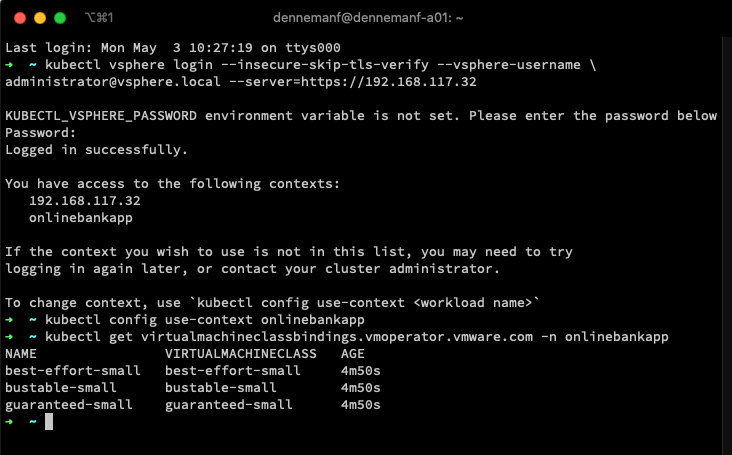
The developer can view the VM classes assigned to the namespace by using the following command:
kubectl get virtualmachineclassbindings.vmoperator.vmware.com -n namespacename I logged into the API server of the supervisor cluster, changed the context to the namespace “onlinebankapp” and executed the command:
kubectl get virtualmachineclassbindings.vmoperator.vmware.com -n onlinebankapp
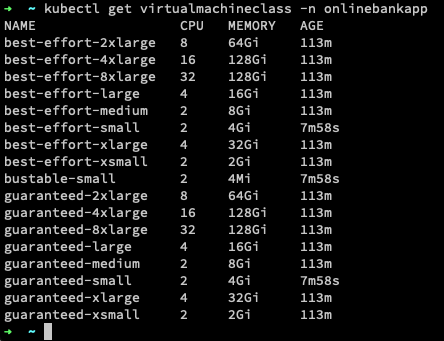
If you would have used the command “kubectl get virtualmachineclass -n onlinebankapp“, you get presented with the list of virtualmachineclasses available within the cluster.
Help Developers by Aligning Their Kubernetes Nodes to the Physical Infrastructure
With the new VM service and the customizable VM classes, you can help the developer align their nodes to the infrastructure. Infrastructure details are not always visible at the Kubernetes layers, and maybe not all developers are keen to learn about the intricacies of your environment. The VM service allows you to publish only the VM classes you see fit for that particular application project. One of the reasons could be the avoidance of monster-VM deployment. Before this update, developers could have deployed a six worker node Kubernetes cluster using the guaranteed 8XLarge class (each worker node equipped with 32 vCPUs, 128Gi all reserved), granted if your hosts config is sufficient. But the restriction is only one angle to this situation. Long-lived relationships are typically symbiotic of nature, and powerplays typically don’t help build relationships between developers and the InfraOps team. What would be better is to align it with the NUMA configuration of the ESXi hosts within the cluster.
NUMA Alignment
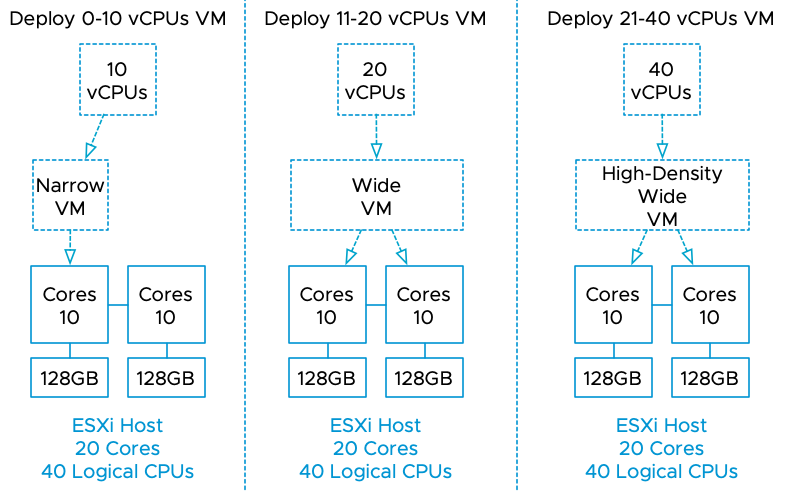
I’ve published many articles on NUMA, but here is a short overview of the various NUMA configuration of VMs. If a virtual machine (VM) powers on, the NUMA scheduler creates one or more NUMA clients based on the VM CPU count and the physical NUMA topology of the ESXi host. For example, a VM with ten vCPUs powered on an ESXi host with ten cores per NUMA node (CPN2) is configured with a single NUMA client to maximize resource locality. This configuration is a narrow-VM configuration. Because all vCPU have access to the same localized memory pool, this can be considered an Unified Memory Architecture (UMA).
Take the example of a VM with twelve vCPUs powered-on on the same host. The NUMA scheduler assigns two NUMA clients to this VM. The NUMA scheduler places both NUMA clients on different NUMA nodes, and each NUMA client contains six vCPUs to distribute the workload equally. This configuration is a wide VM configuration. If simultaneous multithreading (SMT) is enabled, a VM can have as many vCPUs equal to the number of logical CPUs within a system. The NUMA scheduler distributes the vCPUs across the available NUMA nodes and trusts the CPU scheduler to allocate the required resources. A 24 vCPU VM would be configured with two NUMA clients, each containing 12 vCPUs if deployed on a 10 CPN2 host. This configuration is a high-density wide VM.
A great use of VM service is to create a new set of VM classes aligned with the various NUMA configurations. Using the dual ten core system as an example, I would create the following VM classes and the associated CPU and memory resource reservations :
| CPU | Memory | Best Effort | Burstable | Burstable Mem Optimized | Guaranteed | |
| UMA-Small | 2 | 16GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
| UMA-Medium | 4 | 32GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
| UMA-Large | 6 | 48GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
| UMA-XLarge | 8 | 64GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
| NUMA-Small | 12 | 96GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
| NUMA-Medium | 14 | 128GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
| NUMA-Large | 16 | 160GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
| NUMA-XLarge | 18 | 196GB | 0% | 0% | 50% | 50% | 50% | 75% | 100% | 100% |
The advantage of curating VM classes is that you can align the Kubernetes nodes with a physical NUMA node’s boundaries at CPU level AND memory level. In the table above, I create four classes that remain within a NUMA node’s boundaries and allow the system to breathe. Instead of maxing out the vCPU count to what’s possible, I allowed for some headroom, avoiding a noisy neighbor with a single NUMA node and system-wide. Similar to memory capacity configuration, the UMA-sized (narrow-VM) classes have a memory configuration that does not exceed the physical NUMA boundary of 128GB, increasing the chance that the ESXi system can allocate memory from the local address range. The developer can now query the available VM classes and select the appropriate VM class with his or her knowledge about the application resource access patterns. Are you deploying a low-latency memory application with a moderate CPU footprint? Maybe a UMA-Medium or UMA-large VM class helps to get the best performance. The custom VM class can transition the selection process from just a numbers game (how many vCPUs do I want?) to a more functional requirement exploration (How does it behave?) Of course, these are just examples, and these are not official VMware endorsements.
In addition, I created a new class, “Burstable mem optimized”, A class that reserves 25% more memory capacity than its sibling VM class “Burstable”. This could be useful for memory-bound applications that require the majority of memory to be reserved to provide consistent performance but do not require all of it. The beauty of custom VM classes is that you can design them as they fit your environment and your workload. With your skillset and knowledge about the infrastructure, you can help the developer to become more successful.