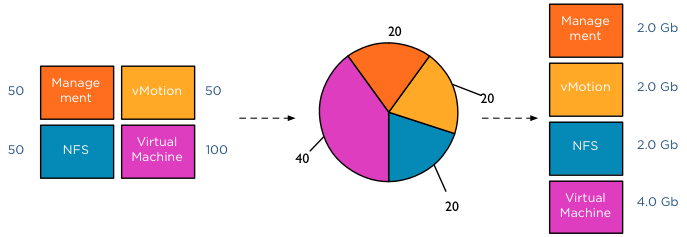
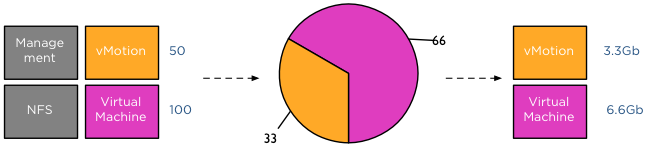
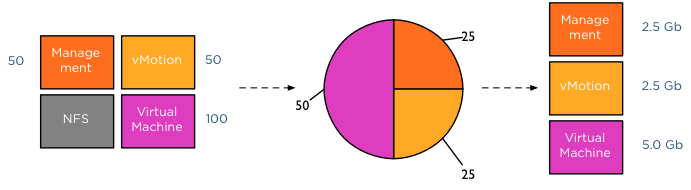
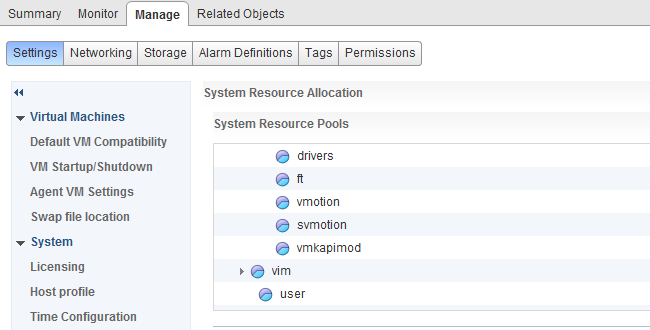
Folks,
We have been testing the HOL platform for a few weeks using automated scripts and thought it would be great if we could do a real time stress test of our environment.
The goal of this test is to put a massive load on our infrastructure and see how fast we can get the service to crawl to its knees. We understand that this is not a very good scientific approach but think collecting real user data will help us prepare for massive loads like Partner Exchange and VMworld.
Currently we have close to 10,000 users in the Beta so we expect the application / infrastructure to keel over right after we start. We want to use this test as a way to learn what happens and where the smoke is coming from.
If you registered for the Beta and you do not have an account please check your inbox from email from admin projectnee.com to verify your account. If you have not registered its time to do so,…REGISTER FOR BETA
Here is what we need you to do:
- Take any lab on Thursday Feb 7th from 2:00 – 4:00 PM PST.
- Send us feedback (on this thread) on your experience.
- Include Lab Name, Description of Problem, Screen Shot.
Follow Project NEE on Twitter for latest Updates http://twitter.com/vmwarehol
Thanks for your support!