This week I had the pleasure to talk to a customer about NUMA use-cases and a very interesting config came up. They have a VM with a particular memory configuration that exceeds the ESXi host NUMA node memory configuration. This scenario is covered in the vSphere 6.5 Host Resources Deep Dive, excerpt below.
Memory Configuration
The scenario described happens in multi-socket systems that are used to host monster-VMs. Extreme memory footprint VMs are getting more common by the day. The system is equipped with two CPU packages. Each CPU package contains twelve cores. The system has a memory configuration of 128 GB in total. The NUMA nodes are symmetrically configured and contain 64 GB of memory each.

However, if the VM requires 96 GB of memory, a maximum of 64 GB can be obtained from a single NUMA node. This means that 32 GB of memory could become remote if the vCPUs of that VM can fit inside one NUMA node. In this case, the VM is configured with 8 vCPUs.

The VM fits from a vCPU perspective inside one NUMA node, and therefore the NUMA scheduler configures for this VM a single virtual proximity domain (VPD) and a single a load-balancing group which is internally referred to as a physical proximity domain (PPD).
Example Workload
Running a SQL DB on this machine resulted in the following local and remote memory consumption. The VM consumes nearly 64 GB on its local NUMA node (clientID shows the location of the vCPUs) while it consumes 31 GB of remote memory.

In this scenario, it could be beneficial to the performance of the VM to rely on the NUMA optimizations that exist in the guest OS and application. The VM advanced setting numa.consolidate = FALSE instructs the NUMA scheduler to distribute the VM configuration across as many NUMA nodes as possible.

In this scenario, the NUMA scheduler creates 2 load-balancing domains (PPDs) and allows for a more symmetrical configuration of 4 vCPUs per node.
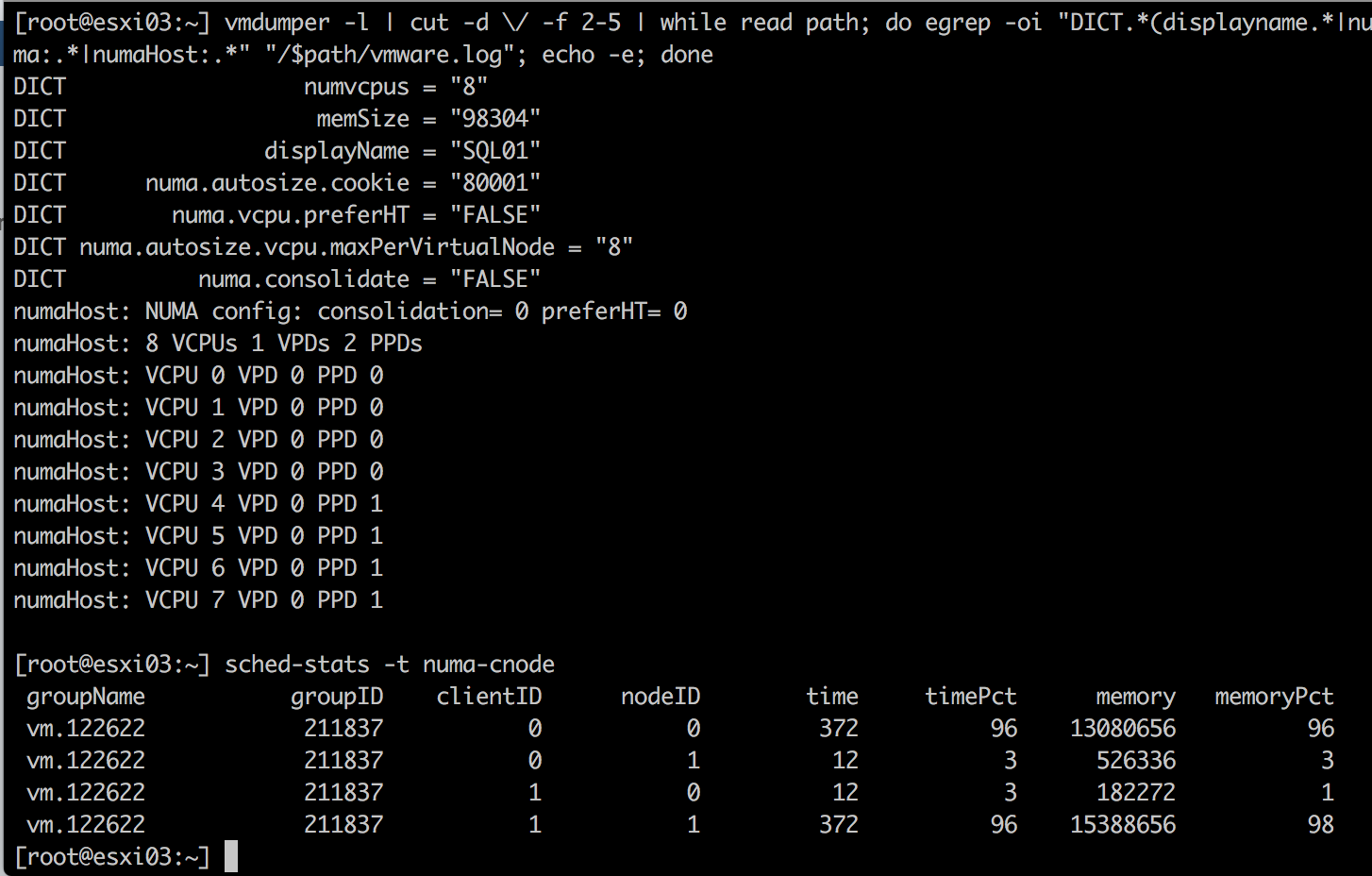
Please note that a single VPD (VPD0) is created and as a result, the guest OS and the application only detect a single NUMA node. Local and remote memory optimizations are (only) applied by the NUMA scheduler in the hypervisor.
Whether or not the application can benefit from this configuration depends on its design. If it’s a multi-threaded application, the NUMA scheduler can allocate memory closes to the CPU operation. However, if the VM is running a single-threaded application, you still might end up with a lot of remote memory access, as the physical NUMA node hosting the vCPU is unable to provide the memory demand by itself.
Test the behavior of your application before making the change to create a baseline. As always, use advanced settings only if necessary!


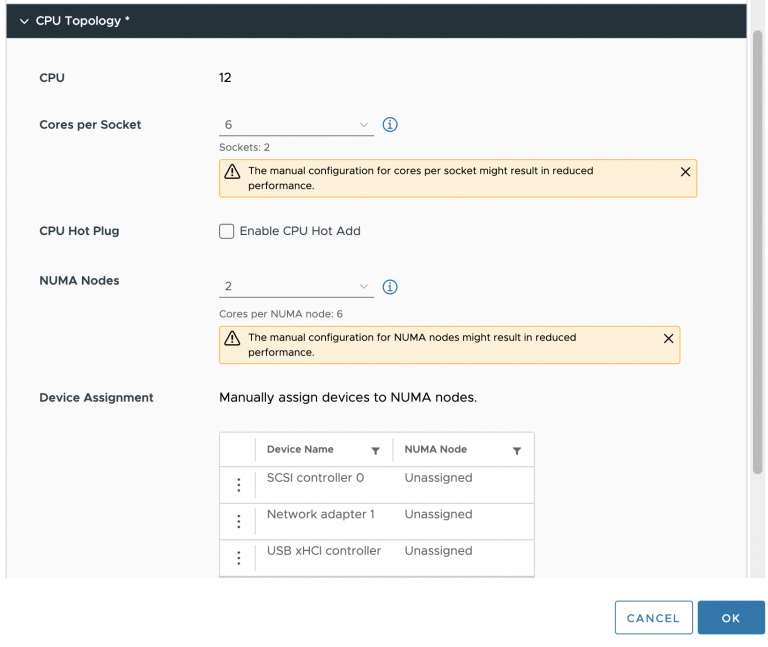
Just a quick thought, Frank – is there any way in this case to let the Guest OS know that it is now spread over two nodes? Configure 4 cps (cores per socket)? I guess it would still show all 8 vCPUs within one VPD, right?
It *could* be beneficial to the GuestOS/application if it would know, at least in some scenarios.
Yes, you can. You can alter the VPD size of the VPD by setting the numa.vcpu.maxPerVirtualNode to 4. This way it exposes two NUMA nodes of 4 CPU each.
You can also set the Cores Per Socket setting in the UI to 4 cores per socket. This way the hypervisor provides an environment that is more true to the physical world, sharing socket, cores and cache.
I will publish an article on this soon.
Hi Frank,
as always awesome explanation and pictures!
I think it would be very beneficial if for example vROps would show such information like this (% of remote memory access, non-optimal vNUMA config) and give some recommendations like those advanced settings. If you migrate to newer hardware you could end up again in an unbalanced configuration for certain VMs if your NUMA topology and memory per node changes with those newer CPU‘s. What you end up is an excel spreadsheet or somewhere else to track your non-standard VM configuration.
Maybe you have more information if something is planned to bring this valuable information into vROps?