During this Christmas break, I wanted to learn PowerCLI properly. As I’m researching the use-cases of new hardware types and workloads in the data center, I managed to produce a script to identify the PCIe Device to NUMA Node Locality within a VMware ESXi Host. The script set contains a script for the most popular PCIe Device types for data centers that can be assigned as a passthrough device. The current script set is available on Github and contains scripts for GPUs, NICs and (Intel) FPGAs.
PCIe Devices Becoming the Primary Units of Data Processing
Due to the character of new workloads, the PCIe device is quickly moving up from “just” being a peripheral device to become the primary unit for data processing. Two great examples of this development are the rise of General Purpose GPU (GPGPU), often referred to as GPU Compute, and the virtualization of the telecommunication space.
The concept of GPU computing implies using GPUs and CPUs together. In many new workloads, the processes of an application are executed on a few CPU cores, while the GPU, with its many cores, handles the computational intensive data-processing part. Another workload, or better said, a whole industry that leans heavily on the performance of PCIe devices, is the telecommunication industry. Virtual Network Functions (VNF) require platforms using SR-IOV capable NICs or SmartNICs to provide ultra-fast packet processing performance.
In both scenarios having insight into PCIe Device to processor locality is a must to provide the best performance to the application or avoid introducing menacing noisy neighbors that can influence the performance of other workloads active in the system.
PCIe Device NUMA Node Locality
The majority of servers used in VMware virtualized environments are two CPU socket systems. Each CPU socket accommodates a processor containing several CPU cores. A processor contains multiple memory controllers offering a connection to directly connected memory. An interconnect (Intel: QuickPath Interconnect (QPI) & UltraPath Interconnect (UPI), AMD: Infinity Fabric (IF)) connects the two processors and allows the cores within each processor to access the memory connected to the other processor. When accessing memory connected directly to the processor, it is called local memory access. When accessing memory connected to the other processor, it is called remote memory access. This architecture provides Non-Uniform Memory Access (NUMA) as access latency, and bandwidth differs between local memory access or remote memory access. Henceforth these systems are referred to as NUMA systems.
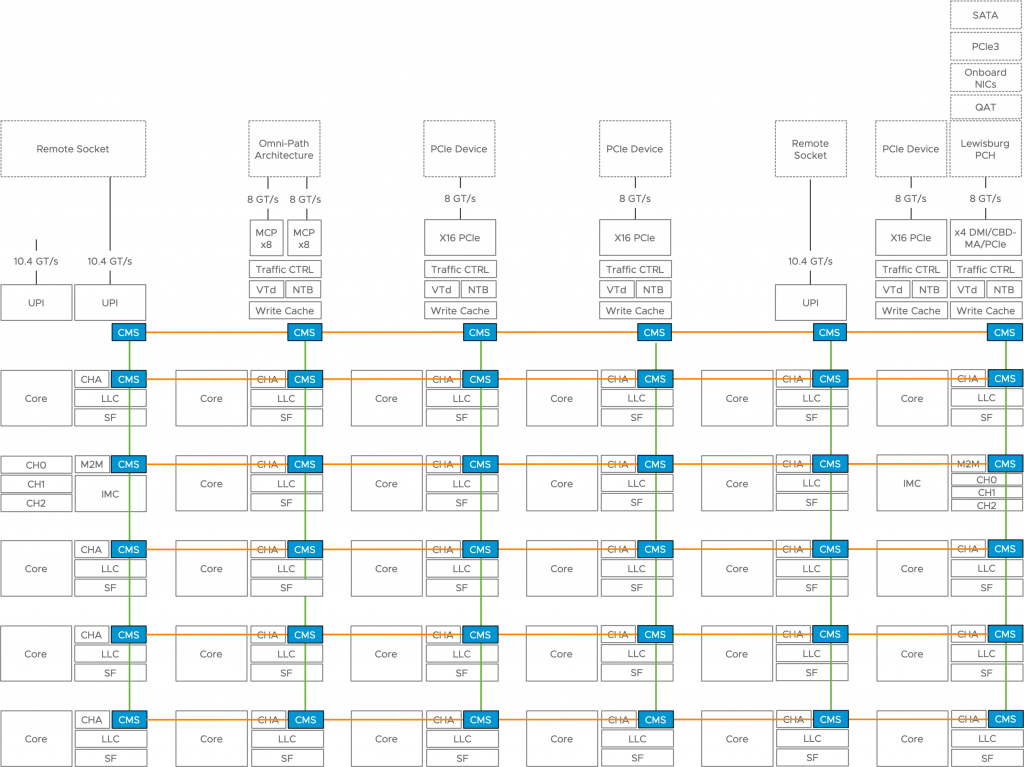
It was big news when the AMD Opteron and Intel Nehalem Processor integrated the memory controller within the processor. But what about PCIe devices in such a system? Since the Sandy Bridge Architecture (2009), Intel reorganized the functions critical to the core and grouped them in the Uncore, which is a “construct” that is integrated into the processor as well. And it is this Uncore that handles the PCIe bus functions. It provides access to NVMe devices, GPUs, and NICs. Below is a schematic overview of a 28 core Intel Sky lake processor showing the PCIe ports and their own PCIe root stack.
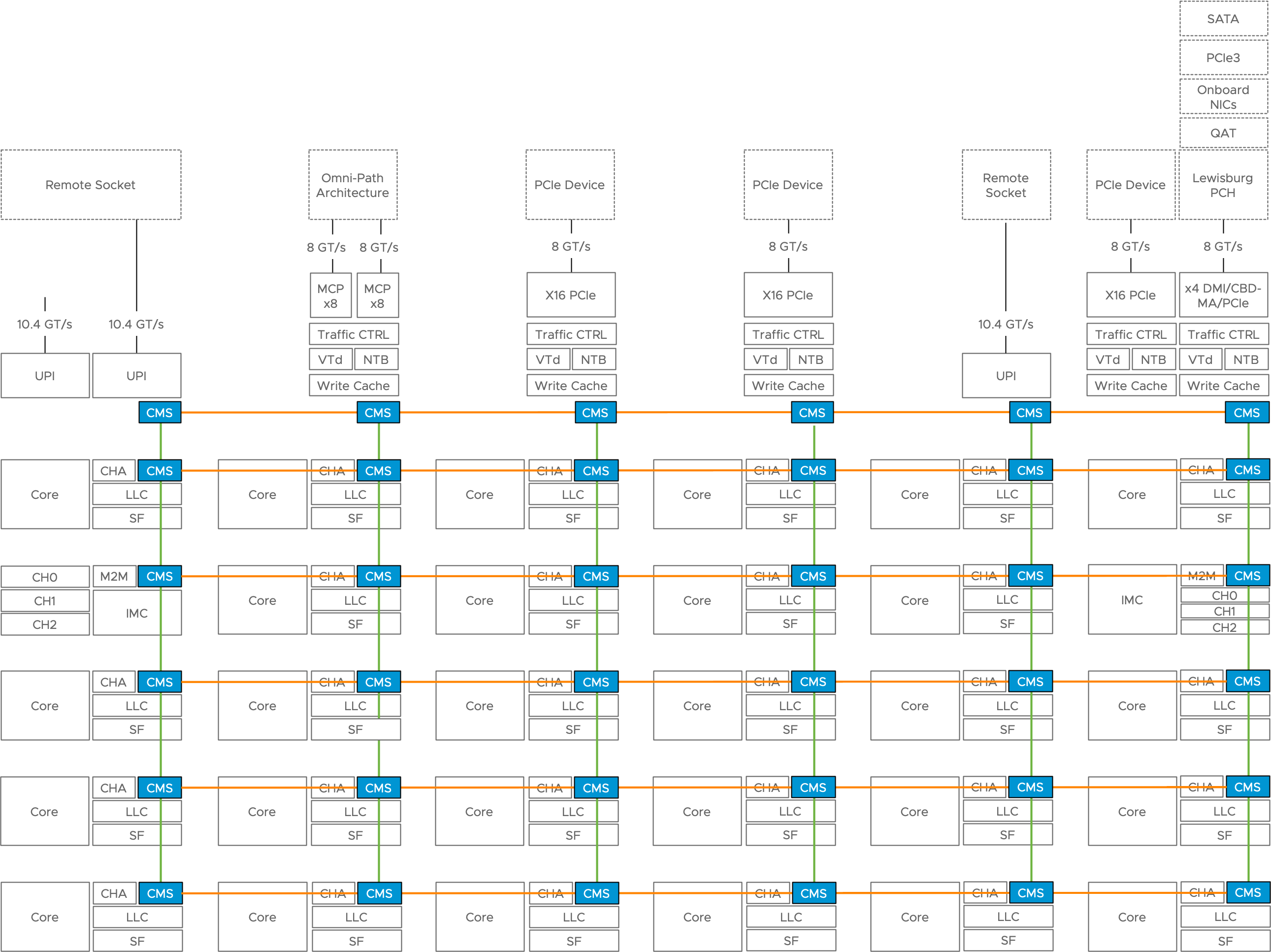
In essence, a PCIe device is hardwired to a particular port on a processor. And that means that we can introduce another concept to NUMA locality, which is PCIe locality. Considering PCIe locality when scheduling low-latency or GPU compute workload can be beneficial not only to the performance of the application itself but also to the other workloads active on the system.
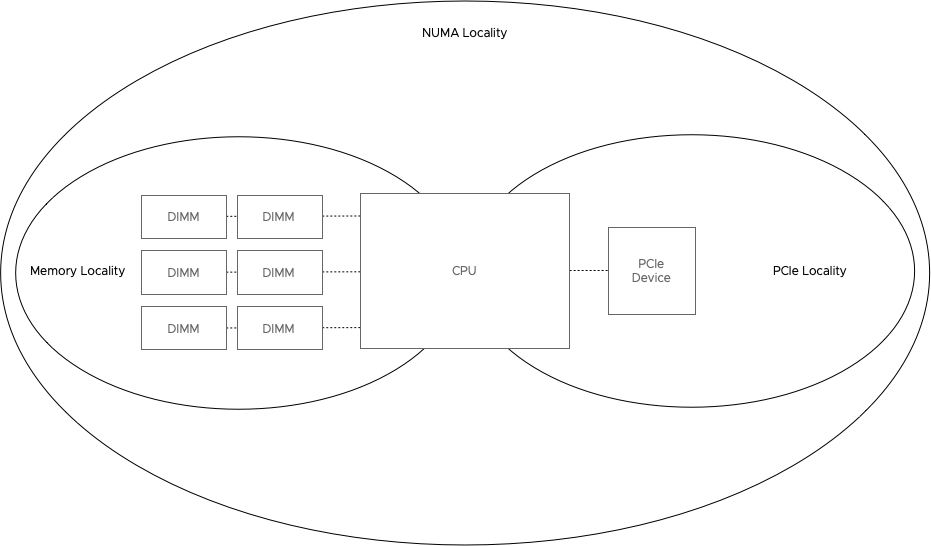
For example, Machine Learning involves processing a lot of data, and this data flows within the system from the CPU and memory subsystem to the GPU to be processed. Properly written Machine Learning application routines minimize communication between the GPU and CPU once the dataset is loaded on the GPU, but getting the data onto the GPU typically turns the application into a noisy neighbor to the rest of the system. Imagine if the GPU card is connected to NUMA node 0, and the application is running on cores located in NUMA node 1. All that data has to go through the interconnect to the GPU card.
The interconnect provides more theoretical bandwidth than a single PCIe 3.0 device can operate at, ~40 GB/s vs. 15 GB/s. But we have to understand that interconnect is used for all PCIe connectivity and memory transfers by the CPU scheduler. If you want to explore this topic more, I recommend reviewing Amdahl’s Law – Validity of the single processor approach to achieving large scale computing capabilities – published in 1967. (Still very relevant) And the strongly related Little’s Law. Keeping the application processes and data-processing software components on the same NUMA node keeps the workloads from flooding the QPI/UPI/ AMD IF interconnect.
For VNF workloads, it is essential to avoid any latency introduced by the system. Concepts like VT-d (Virtualization Technology for Directed I/O) reduces the time spent in a system for IOs and isolate the path so that no other workload can affect its operation. Ensuring the vCPU operates within the same NUMA domain ensures that no additional penalties are introduced by traffic on the interconnect and ensures the shortest path is provided from the CPU to the PCIe device.
Constraining CPU Placement
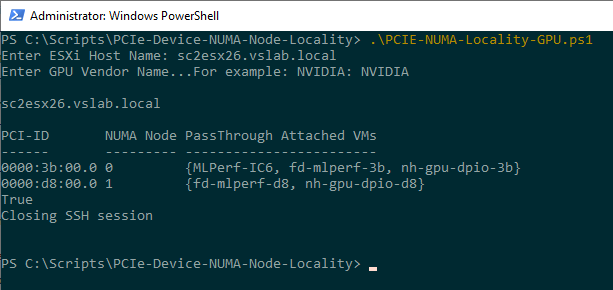
The PCIe Device NUMA Node Locality script assists in obtaining the best possible performance by identifying the PCIe locality of GPU, NIC of FPGA PCIe devices within VMware ESXi hosts. Typically VMs running NFV or GPGPU workloads are configured with a PCI passthrough enabled device. As a result, these VMware PowerCLI scripts inform the user which VMs are attached directly to the particular PCIe devices.
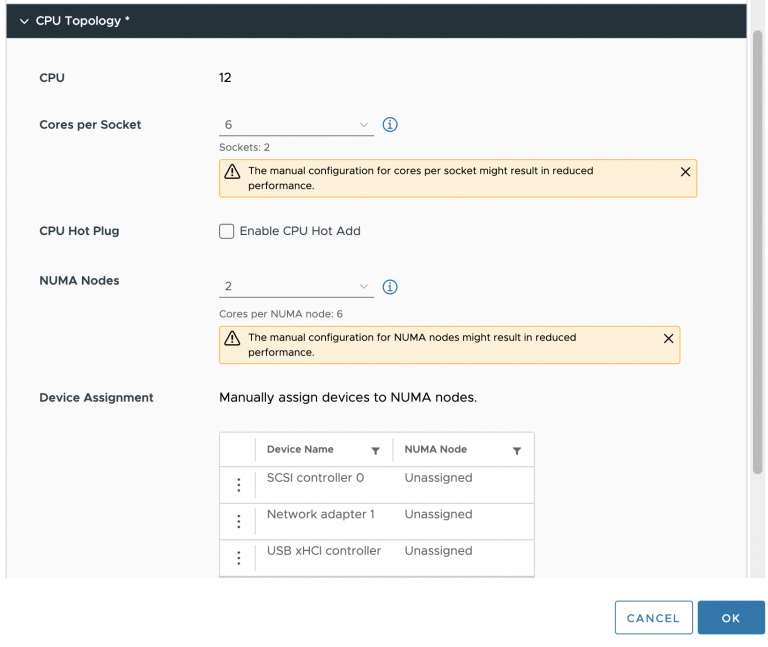
Currently, the VMkernel schedulers do no provide any automatic placement based on PCIe locality. CPU placement can be controlled by associating the listed virtual machines with a specific NUMA node using an advanced setting.
Please note that applying this setting can interfere with the ability of the ESXi NUMA scheduler to rebalance virtual machines across NUMA nodes for fairness. Specify NUMA node affinity only after you consider the rebalancing issues.
The Script Set
The purpose of these scripts is to identify the PCIe Device to NUMA Node locality within a VMware ESXi Host. The script set contains a script for the most popular PCIe Device types for Datacenters that can be assigned as a passthrough device. The current script set contains scripts for GPUs, NICs, and (Intel) FPGAs.
Please note that these scripts only collect information and do not alter any configuration in any way possible.
Requirements
- VMware PowerCLI
- Connection to VMware vCenter
- Unrestricted Script Execution Policy
- Posh-SSH
- Root Access to ESXi hosts
Please note that Posh-SSH only works on Windows version of PowerShell.
The VMware PowerCLI script primarily interfaces with the virtual infrastructure via a connection to the VMware vCenter Server. A connection (Connect-VIServer) with the proper level of certificates must be in place before executing these scripts. The script does not initiate any connect session itself. It assumes this is already in-place.
As the script extracts information from the VMkernel Sys Info Shell (VSI Shell) the script uses Posh-SSH to log into ESXi host of choice and extracts the data from the VSI Shell for further processing. The Posh-SSH module needs to be installed before running the PCIe-NUMA-Locality scripts, the script does not install Posh-SSH itself. This module can be installed by running the following command Install-Module -Name Posh-SSH (Admin rights required). More information can be found at https://github.com/darkoperator/Posh-SSH
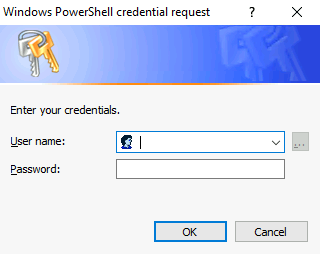
Root access is required to execute a vanish command via the SSH session. It might be possible to use SUDO, but this has functionality has not been included in the script (yet). The script uses Posh-SSH keyboard-interactive authentication method and presents a screen that allows you to enter your root credentials securely.
Script Content
Each script consists of three stages, Host selection & logon, data collection, and data modeling. The script uses the module Posh-SSH to create an SSH connection and runs a vsish command directly on the node itself. Due to this behavior, the script creates an output per server and cannot invoke at the cluster level.
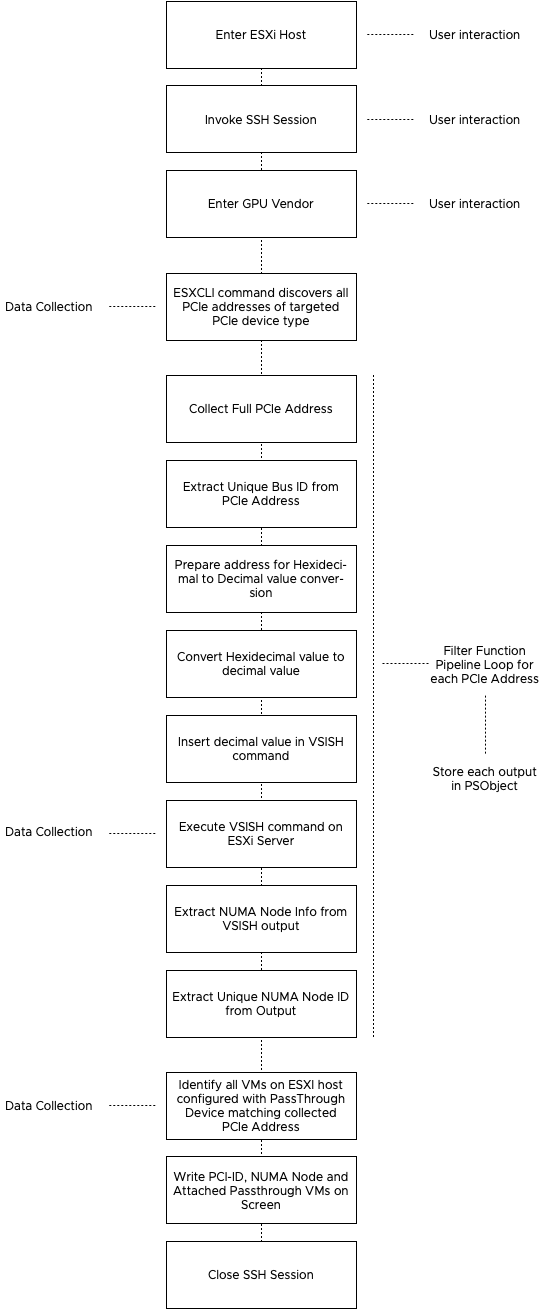
Host Selection & Logon
The script requires you to enter the FQDN of the ESXi Host, and since you are already providing input via the keyboard, the script initiates the SSH session to the host, requiring you to login with the root user account of the host. When using the GPU script, the input of the GPU vendor name is requested. The input can be, for example, NVIDIA, AMD, Intel, or any other vendor providing supported GPU devices. This input is not case-sensitive.
Data Collection
The script initiates an esxcli command that collects the PCIe address of the chosen PCIe device type. It stores the PCIe addresses in a simple array.
Data Modeling
The NUMA node information of the PCIe device is available in the VSI Shell. However, it is listed under the decimal value of the Bus ID of the PCIe address of the device. The part that follows is a collection of instructions converting the full address space into a double-digit decimal value. Once this address is available, it’s inserted in a VSISH command and execute on the ESXi host via the already opened SSH connection. The NUMA node, plus some other information, is returned by the host, and this data is trimmed to get the core value and store it in a PSobject. Throughout all the steps of the data modeling phase, each output of the used filter functions is stored in a PSObject. This object can be retrieved to verify if the translation process was executed correctly. Call $bdfOutput to retrieve the most recent conversion. (as the data of each GPU flows serially through the function pipeline, only the last device conversion can be retrieved by calling $bdfOutput.
The next step is to identify if any virtual machines registered on the selected host are configured with PCIe passthrough devices corresponding with the discovered PCIe addresses.
Output
A selection of data points is generated as output by the script:
| PCIe Device | Output Values |
|---|---|
| GPU | PCI ID, NUMA Node, Passthrough Attached VMs |
| NIC | VMNIC name, PCI ID, NUMA Node, Passthrough Attached VMs |
| FPGA | PCI ID, NUMA Node, Passthrough Attached VMs |
The reason why the PCI ID address is displayed is that when you create a VM, the vCenter UI displays the (unique) PCI-ID first to identify the correct card. An FPGA and GPU do not have a VMkernel label, such as the VMNIC label of a network card. No additional information about the VMs is provided, such as CPU scheduling locations or vNUMA topology, as these are expensive calls to make and can change every CPU Quorum (50 ms).
It’s recommended to review the CPU topology of the virtual machine and if possible to set the NUMA Node affinity following the instructions listed in VMware Resource Management Guide. Please note that using this advanced setting can impact the ability of the CPU and NUMA schedulers to achieve an optimal balance.
Using the Script Set
- Step 1. Download the script by clicking the “Download” button on the Github repository
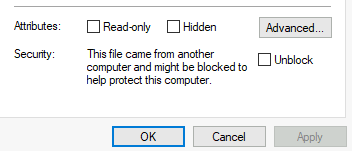
- Step 2. Unlock scripts (Properties .ps1 file, General tab, select Unlock.)
- Step 3. Open PowerCLI session.
- Step 4. Connect to VIServer
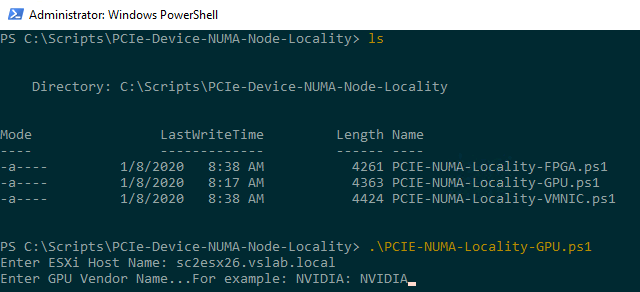
- Step 5. Execute script for example, the GPU script: .\PCIE-NUMA-Locality-GPU.ps1
- Step 6. Enter ESXi Host Name
- Step 7. Enter GPU Vendor Name
- Step 8. Enter Root credentials to establish SSH session
Step 8. Consume output and possibly set NUMA Node affinity for VMs
Acknowledgments
This script set would not have been created without the guidance of @kmruddy and @lucdekens. Thanks, Valentin Bondzio, for verification of NUMA details and Niels Hagoort and the vSphere TM team for making their lab available to me.


One Reply to “PCIe Device NUMA Node Locality”
Comments are closed.