Ever wondered why the band is always mentioned second, is the band replaceable? Is the sound of the instruments so ambiguous that you can swap out any musician with another? Apparently the front man is the headliner of the show and if he does he job well he will never be forgotten. The people who truly recognize talent are the ones that care about the musicians. They understand that the artist backing the singer create the true sound of the song. And I think this is also the case when it comes to DRS and his supporting act the Storage controllers. Namely SIOC and NETIOC. If you do it right, the combination creates the music in your virtual datacenter, well at least from a resource management perspective. 😉
Last week Chris Wahl started a discussion about DRS and its inability to not load-balance perfectly the VMs amongst host. Chris knows about the fact that DRS is not a VM distribution mechanism, his argument is more focused on the distribution of load on the backend; the north-south and east-west uplinks. And for this I would recommend SIOC and NETIOC. Let’s do a 10.000 foot flyby over the different mechanisms.
Distributed Resource Scheduler (DRS)
DRS distributes the virtual machines – the consumers – across the ESXi hosts, the producers. Whenever the virtual machine wants to consume more resources, DRS attempts to provide these resources to this virtual machine. It can do this by moving other virtual machines to different hosts, or move the virtual machine to another host. Trying to create an environment where the consumers can consume as much as possible. As workload patterns differ from time to time, from day to day, an equal number of VMs per host does not provide a balanced resource offering. It’s best to create a combination of idle and active virtual machines per host. And now think about the size of virtual machines, most environments do not have a virtual machine configuration landscape to utilizes a identical hardware configuration. And if that was the case, think about the applications, Some are memory bound, some applications are CPU bound. And to make it worse, think load correlation and load synchronicity. Load correlation defines the relationship between loads running in different machines. If an event initiates multiple loads, for example, a search query on front-end webserver resulting in commands in the supporting stack and backend. Load synchronicity is often caused by load correlation but can also exist due to user activity. It’s very common to see spikes in workload at specific hours, for example think about log-on activity in the morning. And for every action, there is an equal and opposite re-action, quite often load correlation and load synchronicity will introduce periods of collective non-or low utilization, which reduce the displayed resource utilization. All these things, all this coordination is done by DRS, fixating an identical number of VMs per host is in my opinion lobotomizing DRS.
But DRS is only focused on CPU and Memory. Arguably you can treat network and storage somewhat CPU consumption as well, but lets not go that deep. Some applications are storage bound some applications are network bound. For this other components are available in your vSphere infrastructure. The forgotten heroes, SIOC and NETIOC.
Storage IO Control (SIOC)
Storage I/O Control (SIOC) provides a method to fairly distribute storage I/O resources during times of contention. SIOC provides a datastore-wide scheduling using virtual disk shares to calculate priority. In a healthy and properly designed environment, every host that is part of the cluster should have a connection to the datastore and all host should have an equal amount of paths to the datastore. SIOC monitors the consumption and if the latency experienced by the virtual machine exceeds the user-defined threshold, SIOC distributes priority amongst the virtual machines hitting that datastore. By default every virtual machine receives the same priority per VMDK per datastore, but this can be modified if the application requires this from a service level perspective.
Network I/O Control (NETIOC)
The east-west equivalent of its north-south brother SIOC. NETIOC provides control for predictable networking performance while different network traffic streams are contending for the same bandwidth. Similar controls are offered, but are now done on traffic patterns instead of a per virtual machine basis. Similar architecture design hygiene applies here as well. All hosts across the cluster should have the same connection configuration and amount of bandwidth available to them. The article “A primer on Network I/O Control” provides more info on how NETIOC works, VMware published a NETIOC Best Practice white paper a while ago, but most of it is still accurate.
And the bass guitar player of the virtual datacenter, Storage DRS.
Storage DRS provides virtual machine disk placement and load balancing mechanisms based on both space and I/O capacity. Where SIOC reactively throttles hosts and virtual machines to ensure fairness, SDRS proactively generates recommendations to prevent imbalances from both space utilization and latency perspectives. More simply, Storage DRS does for storage what DRS does for compute resources.
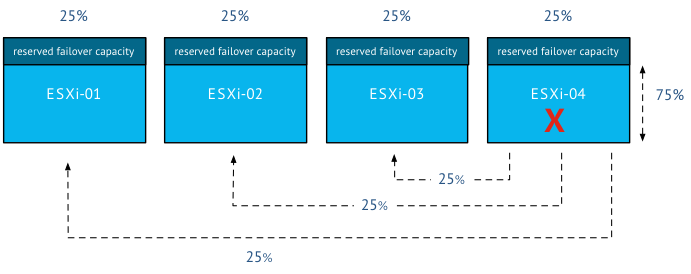
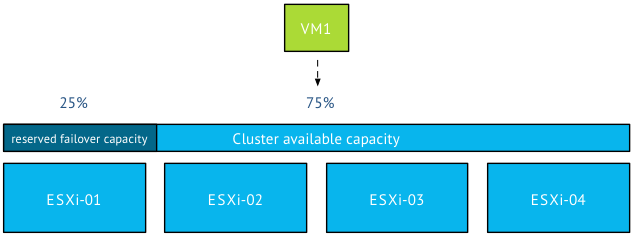
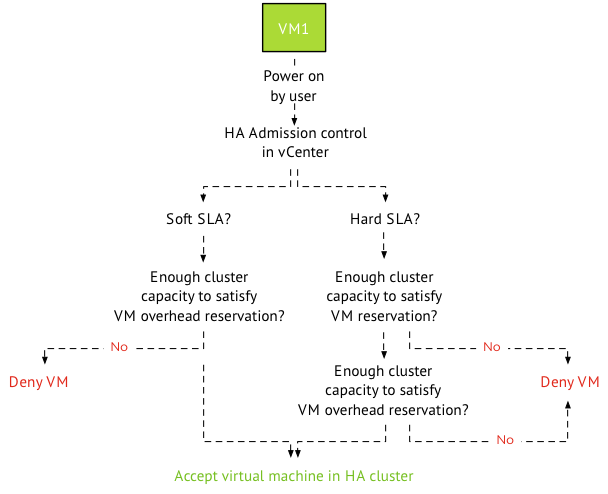
These mechanism combined with a healthy – well architected – environment will help you distribute the consumers across the producers with the proper context in mind. Which virtual machines are hot and which are not? Much better than playing the numbers game! Now, one might argue but what about failure scenarios? If a have an equal number of VMs running on my host, my failover time decreases as well. Well it depends. HA distributes virtual machines across the cluster and if DRS is up and running, it moves virtual machines around if it cannot satisfy the resource entitlement of the virtual machines (VM level reservations). Duncan wrote about DRS and HA behavior a while ago, and of course we touched upon this in our book the 5.1 clustering deepdive. (still fully applicable for 5.5 environments)
In my opinion, trying to outsmart advanced and adaptive computer algorithms with basic math reasoning is really weird. Especially when most people are talking about Software defined datacenters and whether you are managing pets versus cattle. When your environment is healthy and layed-out in a homogenous way , you cannot beat computer algorithms. The thing you should focus on is the alignment of resource priority to business service levels. And that’s what you achieve by applying the correct share levels at DRS, SIOC and NETIOC levels. Maybe you can devops your way into leveraging various scripting languages. 😉