Recently VMware decided that it’s best to change Transparent Page Sharing (TPS) behavior. In KB 2080735 they state the following:
Although VMware believes the risk of TPS being used to gather sensitive information is low, we strive to ensure that products ship with default settings that are as secure as possible. For this reason new TPS management options are being introduced and inter-Virtual Machine TPS will no longer be enabled by default in ESXi 5.5, 5.1, 5.0 Updates and the next major ESXi release. Administrators may revert to the previous behavior if they so wish.
VMware reworked the TPS code and the new code is included in version: ESXi 5.5 Update 2d (Q1, 2015), ESXi 5.1 Update 3 (12/4, 2014) and ESXi 5.0 Update 3d (Q1, 2015).
In the previous released patches*, new TPS management capabilities where introduced but not enabled by default. The new TPS management capabilities introduce the concept of salting has been introduced to control Intra-VM TPS.
What is salting?
This whole exercise of protecting TPS started when researchers found a way to determine the AES encryption key in use of virtual machines on a physical processor (grossly simplified explanation). To counter act this, VMware added salting options to harden TPS. In encryption salting is the act of adding random data to make a common password uncommon. By concatenating random data to a common password, the password now becomes uncommon, making it unlikely to show up in any common password list. This slows down the attack. Martin Suecia provided a more elaborate, but easy to understand, explanation about salting on crypto.stackexchange.com.
VMware adopted this concept to group virtual machines. If they contain the same random number they are perceived to be trustworthy and can share pages. If the random number doesn’t match, no memory page sharing occurs between the virtual machines. By default the vc.uuid of the virtual machine is used as random number. And because the vc.uuid is unique randomly generated string for a virtual machine in a Virtual Center, it will never be able to share pages with other virtual machines.
Lets rehash TPS, as there seems to be some misconception on how TPS works. TPS by itself is a two-tier process.
Two tier process
There is an act of identifying identical pages and there is an act of sharing (collapsing) identical pages. TPS cannot collapse pages immediately when starting a virtual machine. TPS is a process in the VMkernel; it runs in the background and searches for redundant pages. Default TPS will have a cycle of 60 minutes (Mem.ShareScanTime) to scan a VM for page sharing opportunities. The speed of TPS mostly depends on the load and specs of the Server. Default TPS will scan 4MB/sec per 1 GHz. (Mem.ShareScanGHz). Slow CPU equals slow TPS process. (But it’s not a secret that a slow CPU will offer less performance that a fast CPU.) TPS defaults can be altered, but it is advised to keep to the default. VMware optimized memory management in ESX 4 that allow pages which Windows initially zeroes will be page-shared by TPS immediately. Please not that this is based on best effort basis this to avoid creating massive overhead on trying to scan in-line.
TPS and large pages
One caveat, TPS will not collapse large pages when the ESX server is not under memory pressure. ESX will back large pages with machine memory, but installs page sharing hints. When memory pressure occurs, the large page will be broken down and TPS can do it’s magic. For more info: Future direction of disabling TPS by default and its impact on capacity planning.
TPS and CPU NUMA structures
Another impact on the memory sharing potential is the NUMA processor architecture. NUMA allows the best memory performance by storing memory pages as close to a CPU as possible. TPS memory sharing could reduce the performance while pages are shared between two separate CPU systems. For more info about NUMA and TPS please read the article: “Sizing VMS and NUMA nodes”
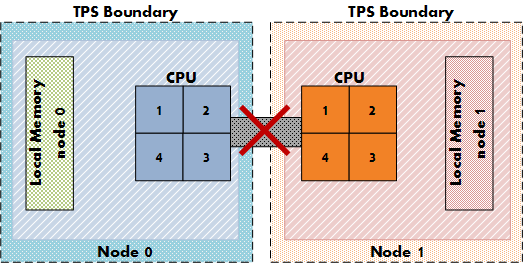
Intra-VM and Inter-VM
When TPS identifies a common page it will collapse it, common pages occur within the memory footprint of a virtual machine itself (Intra-VM) and between virtual machines (Inter-VM). The new setting allows for TPS to collapse page within the memory footprint of the virtual machine itself, but not between virtual machines! Be aware that Intra-VM sharing only occurs today within a NUMA node, with small pages or when large pages are torn down.
TPS salting
In order to Salt pages, two settings must be activated, one at the host (VMkernel) level and one at the virtual machine level. The VMkernel setting is Mem.ShareForceSalting and in the upcoming update releases it is set to “2”. Why not use the setting “1” you might ask? By reviewing the various KB articles, it seems that VMware extending the current salting options introduced in update releases: ({5.5,5.1}201410401 and 5.0 201412401) (KB: 2091682)
KB article 2097593 provides us with the following table:
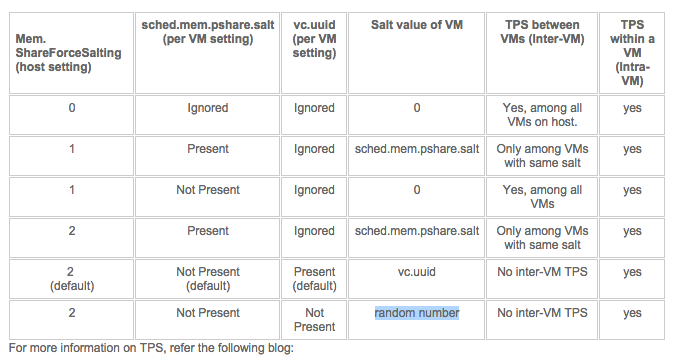
Re-enable Intra-VM TPS
That means that if you want to re-enable Intra-VM TPS you have two options. In-line with security guidelines or reverting back to traditional TPS behavior.
1: To be in-line with the security guidelines you have to set Mem.ShareForceSalting to 1 or 2 and for the virtual machines you wish to share, set sched.mem.pshare.salt to a common value. (Bottom row in the table)
2: To revert back to the traditional TPS behavior you have to set Mem.ShareForceSalting to 0.
For the changes to take effect do either of the two:
1. Migrate all the virtual machines to another host in cluster and then back to original host.
2. Shutdown and power-on the virtual machines.
Since its normal to place host in maintenance mode before changing its configuration, option 1 seems like the most common operation. Put a host into maintenance mode, let DRS migrate all the virtual machines to another host, change the setting and exit maintenance mode. Rinse and repeat for all hosts in the cluster.
Recommendations whether to use salting?
Honestly I don’t have any. Security is something that shouldn’t be taken lightly. VMware implies that this security measure is somewhat excessive. Therefor it depends on your security guidelines and your service offering (Public cloud versus own infrastructure) whether you should go through the extra length of securing TPS or not.
Would I recommend enabling TPS? Of course! It’s one of the most intelligent features of the vSphere stack. Allowing you to use the available resources as efficiently as possible.
By default salting is disabled (Mem.ShareForceSalting=0). This means TPS happens as it used to before this patch, that is, all the Virtual Machines on an ESXi box participate in TPS.
* Previous released patches
VMware ESXi 5.5, Patch ESXi550-201410401
VMware ESXi 5.1, Patch ESXi510-201410401
VMware ESXi 5.0, Patch ESXi500-201412401