Note: This article describes NUMA scheduling on ESX 3.5 and ESX 4.0 platform, vSphere 4.1 introduced wide NUMA nodes, information about this can be found in my new article: ESX4.1 NUMA scheduling
With the introduction of vSphere, VM configurations with 8 CPUs and 255 GB of memory are possible. While I haven’t seen that much VM’s with more than 32GB, I receive a lot of questions about 8-way virtual machines. With today’s CPU architecture, VMs with more than 4 vCPUs can experience a decrease in memory performance when used on NUMA enabled systems. While the actually % of performance decrease depends on the workload, avoiding performance decrease must always be on the agenda of any administrator.
Does this mean that you stay clear of creating large VM’s? No need to if the VM needs that kind of computing power, but the reason why I’m writing this is that I see a lot of IT departments applying the same configuration policy used for physical machines. A virtual machine gets configured with multiple CPU or loads of memory because it might need it at some point during its lifecycle. While this method saves time, hassle and avoid office politics, this policy can create unnecessary latency for large VMs. Here’s why:
NUMA node
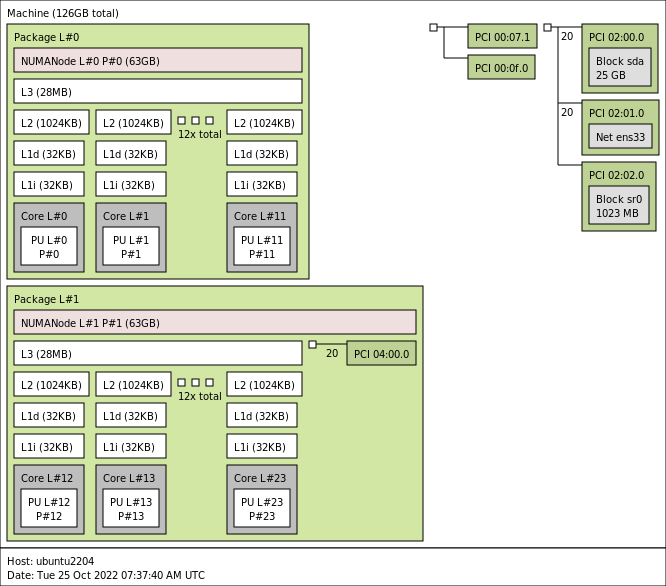
Most modern CPU’s, Intel new Nehalem’s and AMD’s veteran Opteron are NUMA architectures. NUMA stands for Non-Uniform Memory Access, but what exactly is NUMA? Each CPU get assigned its own “local” memory, CPU and memory together form a NUMA node. An OS will try to use its local memory as much as possible, but when necessary the OS will use remote memory (memory within another NUMA node). Memory access time can differ due to the memory location relative to a processor, because a CPU can access it own memory faster than remote memory.

Figure 1: Local and Remote memory access
Accessing remote memory will increase latency, the key is to avoid this as much as possible. How can you ensure memory locality as much as possible?
VM sizing pitfall #1, vCPU sizing and Initial placement.
ESX is NUMA aware and will use the NUMA CPU scheduler when detecting a NUMA system. On non-NUMA systems the ESX CPU scheduler spreads load across all sockets in a round robin manner. This approach improves performance by utilizing as much as cache as possible. When using a vSMP virtual machine in a non-NUMA system, each vCPU is scheduled on a separate socket.
On NUMA systems, the NUMA CPU scheduler kicks in and use the NUMA optimizations to assigns each VM to a NUMA node, the scheduler tries to keep the vCPU and memory located in the same node. When a VM has multiple CPUs, all the vCPUs will be assigned to the same node and will reside in the same socket, this is to support memory locality as much as possible.

Figure 2: NON-NUMA vCPU placement

Figure 3: NUMA vCPU placement
At this moment, AMD and Intel offer Quad Core CPU’s, but what if the customer decides to configure an 8-vCPU virtual machine? If a VM cannot fit inside one NUMA node, the vCPUs are scheduled in the traditional way again and are spread across the CPU’s in the system. The VM will not benefit from the local memory optimization and it’s possible that the memory will not reside locally, creating added latency by crossing the intersocket connection to access the memory.
VM sizing pitfall #2: VM configured memory sizing and node local memory size
NUMA will assign all vCPU’s to a NUMA node, but what if the configured memory of the VM is greater than the assigned local memory of the NUMA node? Not aligning the VM configured memory with the local memory size will stop the ESX kernel of using NUMA optimizations for this VM. You can end up with all the VM’s memory scattered all over the server.
So how do you know how much memory every NUMA node contains? Typically each socket will get assigned the same amount of memory; the physical memory (minus service console memory) is divided between the sockets. For example 16GB will be assigned to each NUMA node on a two socket server with 32GB total physical. A quick way to confirm the local memory configuration of the NUMA nodes is firing up esxtop. Esxtop will only display NUMA statistics if ESX is running on a NUMA server. The first number list the total amount of machine memory in the NUMA node that is managed by ESX, the statistic displayed within the round brackets is the amount of machine memory in the node that is currently free.

Figure 4: esxtop memory totals
Let’s explore NUMA statistics in esxtop a little bit more based on this example. This system is a HP BL 460c with two Nehalem quad cores with 64GB memory. As shown, each NUMA node is assigned roughly 32GB. The first node has 13GB free; the second node has 372 MB free. It looks it will run out of memory space soon, luckily the VMs on that node still can get access remote memory. When a VM has a certain amount of memory located remote, the ESX scheduler migrates the VM to another node to improve locality. It’s not documented what threshold must be exceeded to trigger the migration, but its considered poor memory locality when a VM has less than 80% mapped locally, so my “educated” guess is that it will be migrated when the VM hit a number below the 80%. Esxtop memory NUMA statistics show the memory location of each VM. Start esxtop, press m for memory view, press f for customizing esxtop and press f to select the NUMA Statistics.

Figure 5: Customizing esxtop
Figure 6 shows the NUMA statistics of the same ESX server with a fully loaded NUMA node, the N%L field shows the percentage of mapped local memory (memory locality) of the virtual machines.

Figure 6: esxtop NUMA statistics
It shows that a few VMs access remote memory. The man pages of esxtop explain all the statistics:
| Metric | Explanation |
|---|---|
| NHN | Current Home Node for virtual machine |
| NMIG | Number of NUMA migrations between two snapshots. It includes balance migration, inter-mode VM swaps performed for locality balancing and load balancing |
| NRMEM (MB) | Current amount of remote memory being accessed by VM |
| NLMEM (MB) | Current amount of local memory being accessed by VM |
| N%L | Current percentage memory being accessed by VM that is local |
| GST_NDx (MB) | The guest memory being allocated for VM on NUMA node x. “x” is the node number |
| OVD_NDx (MB) | The VMM overhead memory being allocated for VM on NUMA node x |
Transparent page sharing and memory locality.
So how about transparent page sharing (TPS), this can increase latency if the VM on node 0 will share its page with a VM on node 1. Luckily VMware thought of that and TPS across nodes is disabled by default to ensure memory locality. TPS still works, but will share identical pages only inside nodes. The performance hit of accessing remote memory does not outweigh the saving of shared pages system wide.

Figure 7: NUMA TPS boundaries
This behavior can be changed by altering the setting VMkernel.Boot.sharePerNode. As most default settings in ESX, only change this setting if you are sure that it will benefit your environment, 99.99% of all environments will benefit from the default setting.
Take away
With the introduction of vSphere ESX 4, the software layer surpasses some abilities current hardware techniques can offer. ESX is NUMA aware and tries to ensure memory locality, but when a VM is configured outside the NUMA node limits, ESX will not apply NUMA node optimizations. While a VM still run correctly without NUMA optimizations, it can experience slower memory access. While the actually % of performance decrease depends on the workload, avoiding performance decrease if possible must always be on the agenda of any administrator.
To quote the resource management guide:
The NUMA scheduling and memory placement policies in VMware ESX Server can manage all VM transparently, so that administrators do not need to address the complexity of balancing virtual machines between nodes explicitly.
While this is true, administrators must not treat the ESX server as a black box; with this knowledge administrators can make informed decisions about their resource policies. This information can help to adopt a scale-out policy (multiple smaller VMs) for some virtual machines instead of a scale up policy (creating large VMs) if possible.
Beside the preference for scale up or scale out policy, a virtual environment will profit when administrator choose to keep the VMs as agile as possible. My advice to each customer is to configure the VM reflecting its current and near future workload and actively monitor its habits. Creating the VM with a configuration which might be suitable for the workload somewhere in its lifetime can have a negative effect on performance.
Get notification of these blogs postings and more DRS and Storage DRS information by following me on Twitter: @frankdenneman

Great article Frank,
So what I would like to know is what the actual performance degradation is when for instance 50% of the memory is remote. Does for instance enabling cross numa node page sharing weigh up against the performance loss?
Enjoyed the article and good to hear that TPS does not share remote by default.
Thanks for sharing more ESXTOP tricks! 🙂 I have a question, Does the balloon driver/swapping only come into play when memory across all numa nodes is under severe pressure (6%,4,2,1%…) or does that apply within a node as well. if for example the VM Sizes are all so big as to prohibit node relocation (they are all 2 CPU 6GB machines for example)
Hi Rob,
Good question.
Memory reclaiming techniques will kick in when the memory state changes. The availability of the total available memory – SC memory is measured, not the amount of free memory of a numa node
Great post! Looking at figure#6, you have 8 VMs off which only 3 accessing the memory locally. I’m curious to see how behave the memory scheduler when having a high VM to host ratio?
Also talking about latency when accessing remote memory, is that latency higher than a non-NUMA aware system accessing its memory?
What about memory overcommitment, does the scheduler take into account the ‘real’ memory being used or the overcommited one?
That’s a lot of questions, sorry for that, it’s because your article is an excellent read 😉
Thx,
Didier
Good question, accessing remote memory is always slower than accessing local memory, but cannot answer if the latency is higher than a non-NUMA system accessing its memory.
Gonna look into that!
Just had the chance to read this now. Great article Frank!
Very nice article Frank! I enjoyed reading it!
I have been a reader for a long while, but this is my first time as a commenter. I just wanted to let you know that this has been / is my favorite post of yours! Keep up the good work and I’ll keep on checking back. If you’d be interested in swapping blogroll links with me, my website is MonaVie Scam.
Frank:
Good article, but a clarification needs to be noted. In your Pitfall #2 section, you lead with the following statement:
“Typically each socket will get assigned the same amount of memory; the physical memory (minus service console memory) is divided between the sockets. For example 16GB will be assigned to each NUMA node on a two socket server with 32GB total physical.”
The above reads as if some logical apportionment of memory takes place in NUMA systems. Node memory is typically allocated on a PHYSICAL basis, and assigned to the NUMA node based on the DIMM slot/bank configuration of the system board . In 2P systems, one bank of slots is mastered by a single CPU (local) and the amount of memory “assigned” to that node is entirely dependent on the number of slots filled and size of the DIMM. Each CPU’s memory node is likewise constrained. (Note: some size-constrained NUMA systems provide memory slots to only one CPU node.)
This distinction is necessary because non-uniform distribution of memory across the nodes in a NUMA system can be a physical provisioning issue – sometimes an intentional one. Someone asked about the penalty realized in remote node memory: for testing purposes that question can be easily answered by assigning (physically) 100% of memory to a single CPU’s bank (usually CPU0) and using CPU affinity to determine the performance penalty for remote memory access (move the VM from CPU0 to CPU1 and compare the difference running stream, or another memory benchmark, etc.)
Where the physical allocation distinction is also important is in memory configurations that may ship from vendors without regard to NUMA balancing. For instance, a 32GB (8x 4GB DIMM) configuration could be shipped in the following configurations (DPC = DIMM per channel):
CPU0 = 3DPC x 2-Channel plus 2DPC x 1-channel and CPU1 = 0 DIMM
CPU0 = 2DPC x 3-Channel and CPU1 = 2DPC x 1-Channel
CPU0 = 2DPC x 3-Channel and CPU1 = 1DPC x 2-Channel
CPU0 = 2DPC x 2-Channel and CPU1 = 2DPC x 2-Channel
While more permutations exist, only one of them balanced (i.e. 50-50 distribution of memory). The other configurations, while valid, result in different system assumptions and VM placement. For instance, the 2DPC x 3-channel node will have a greater memory bandwidth than the 2- or 1-channel configurations. Placement (affinity) of VM’s in this node would result in better performance for memory-bound workloads. It is not uncommon to find systems shipped with CPU0 full and CPU1 partially populated.
While NUMA allows for memory imbalances to be handled gracefully in ESX, there may be hidden costs as you point out in terms of remote-node memory latency and the performance ramifications therein. Economics could suggest an intentional imbalanced node configuration is necessary – i.e. placing 72GB (8GB, 3DPC x 3-channel)) in one “super” node (accommodating a 64GB VM) and 36GB (4GB, 3DPC x 3-channel) in another (several 2-6GB VMs).
The above “real world” example would result in a savings of about $3,200 in CAPEX – per system – versus the “balanced” configuration of 18x 8GB DIMMs. ESX’s NUMA balancing algorithms should be able to properly place those VM’s needing the larger contiguous bank of memory in the proper CPU node. In a system with many 48-64GB VM’s in such a confederation would likely need a DRS anti-affinity rule(s) to prohibit co-placement across a cluster. However, combined with ESX’s NUMA scheduler, the “optimal” balance of performance should be automatically achieved…
Like you said, ESX servers are not black boxes, and understanding the system architecture is key in extracting performance and economies of scale. As multi-node, multi-hop systems come on-line (AMD Magny-Cours, Intel’s Nehalem-EX, etc.) in 2010, ESX admins will explore intentionally non-balanced “super node” memory configurations to enable placement of “outlier” VMs without wrecking CAPEX models. Do you happen to know how Xen/Hyper-V would handle the same NUMA situation?
Good article, I stumbled accross it because Im finding ESX isnt so great at balancing out a NUMA box when its only moderately load (seems OK when there is a decent load on the ESX hardware).
On our 24 core bl685 (4 x 6), we find that NUMA nodes 0 and 1 are pretty busy (unfortunately resulting in elevated cpu ready times on the VMS), whilst NUMA nodes 2 and 3 are almost unused.
I have a colleague who as a 32 core (dl785) farm with similar issues. ESX seems to have a weakness when it comes to balancing lightly loaded NUMA boxes, esx4 seems less willing to balance out a box compared with 3.5…
Thanks,
Can you tell me a bit more about the memory pressure? How are the VMs configured (memory wise)?
A customer of mine uses DL785 as well and they don’t have a problem, they don’t create a VM with more than 4GB.
Hi Frank,
A great article on a topic that is often unknown or overlooked by many.
Keep up the good work!
Cheers,
Simon (TechHead)
Frank, russian translation of the article: http://blog.vadmin.ru/2010/05/numa.html
Frank,
Great article. I’m looking for any whitepapers that has been done to show the difference in VM performance when accessing all local memory of a NUMA node versus VMs that have to access all remote memory or a mix. Have you encountered such a study? I think it would be helpful to make the decision on when and where to use 8 vCPU VMs. Based on my understanding of NUMA systems, ideally, you would want to have ESX servers with 8 core or 12 core processors if you want to offer 8-vCPU VMs. Otherwise, if I offer 8-vCPU VMs but only have NUMA nodes with 4 cores, my VM would never experience the full benefit of NUMA optimizations.
-Sean Clark
@brandon:
Hey, we expacted the same issue on the old Opteron DualCore CPUs.
Our Solution was to set NUMA.RebalanceEnable to 0.
After this settings our %RDY times came back to normal look and feel!
kind regards!
Alex, you are aware that you disabled NUMA with this setting right? What might help, is to adjust the Numa.MigImbalanceThreshold setting.
The Numa.MigImbalanceThreshold setting controls the minimum load imbalance between the NUMA nodes needed to trigger a virtual machine migration.
Default this advanced parameter is set to 10 percent, but in your case you might try a lower percentage.
Be aware that the CPU scheduler takes several metrics into account when calculating the CPU imbalance. Metrics such as the CPU entitlement and usage.
Which makes me wonder if both you and Brandon set CPU reservations on the virtual machines?
As always, please use the default settings as much as possible, only change advanced settings when absolutely necessary!
Writing a paper for my summer class this helped lots will credit the site thanks!
I admire someone that takes the pride you have and with your projecton of information. oSo when i actually do sit down to read material, I appreciate well written and organized blogs like this one. I have it bookmarked and will be back. Thanks.
@Frank, so for slow reply, ive moved on from the AMD/NUMA site and am currenlty at an Intel/NON NUMA site. However given all new Intel are NUMA I would like to see an answer.
The VM’s are a mixtures of large SQL (8 x 12-20GB RAM), medium (30 x 4GB citrix), and rats and mice (100 x 500mb – 2gb RAM).
In my un-educated guess, it would seem that numa rebalance DOESNT look at CPU ready time, and to be honest, this is the only metric that is under pressure. EG plenty of RAM and MHZ left in every node.
As mentioned its only when I run out of physical memory in a node, that a new node gets used…..
There are some situations where the vSphere scheduler doesn’t schedule optimally on NUMA systems. To improve the scheduling we’ve recommended disabling NUMA Round Robin in some cases (esxcfg-advcfg -s 0 /Numa/RoundRobin), and in Brandon’s case also recommended sizing VM’s so the vCPU’s are easily divisible by the physical core count. So on a Hex Core system that would be 1,2,3, or 6 vCPU’s per VM only, on a quad core system 1, 2 and 4 vCPU per VM. Doing both resulted in greatly improved CPU ready times. Best practice for performance is as you say, make sure VM Memory size is less than NUMA node size. But without some changes there are some situations where node migration doesn’t occur when it should.
Thanks for this article,
you wrote
“At this moment, AMD and Intel offer Quad Core CPU’s…”
Do you have some experiances to share about hexa core CPUs please ?
My Best
Hi Frank,
Just to let you know, I referred to “Figure 1: Local and Remote memory access” on my own blog over at http://www.benjaminathawes.com/blog/Lists/Posts/Post.aspx?ID=28.
I hope you don’t mind.
Ben
I Am Going To have to return again when my course load lets up – nevertheless I am taking your Rss feed so i could go through your site offline. Thanks.