NUMA
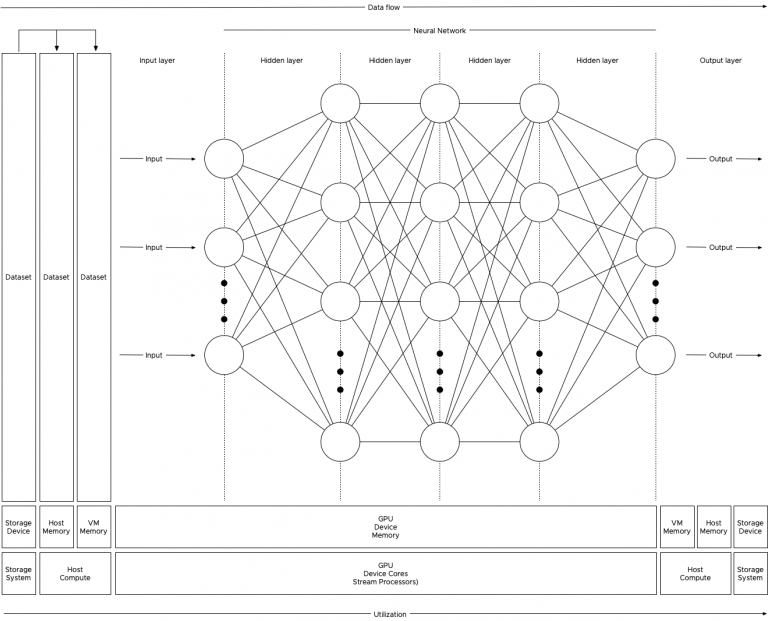
In the previous article “PCIe Device NUMA Node Locality” I covered the physical connection between the processor and the PCIe device...
ESXi Server is optimized for NUMA systems and contains a NUMA scheduler and a CPU scheduler. When ESXi runs on a...
Lately the question about setting CPU affinity is rearing its ugly head again. Will it offer performance advantages for the virtual...
AMD’s current flagship model is the 12-core 6100 Opteron code name Magny-Cours. Its architecture is quite interesting to say at least....
In part 1 of the series of post on the impact of oversized virtual machines NUMA architecture, memory overhead reservation and...
There seems to be a lot of confusion about this BIOS setting, I receive lots of questions on whether to enable...
I received a lot of questions about Hyperthreading and NUMA in ESX 4.1 after writing the ESX 4.1 NUMA scheduling article....
VMware has made some changes to the CPU scheduler in ESX 4.1; one of the changes is the support for Wide...
Note: This article describes NUMA scheduling on ESX 3.5 and ESX 4.0 platform, vSphere 4.1 introduced wide NUMA nodes, information about...