There seems to be some misunderstanding about the new vSphere 8 CPU Topology Device Assignment feature, and I hope this article will help you understand (when to use) this feature. This feature defines the mapping of the virtual PCIe device to the vNUMA topology. The main purpose is to optimize guest OS and application optimization. This setting does not impact NUMA affinity and scheduling of vCPU and memory locality at the physical resource layer. This is based on the VM placement policy (best effort). Let’s explore the settings and their effect on the virtual machine. Let’s go over the basics first. The feature is located in the VM Options menu of the virtual machine.
Click on CPU Topology
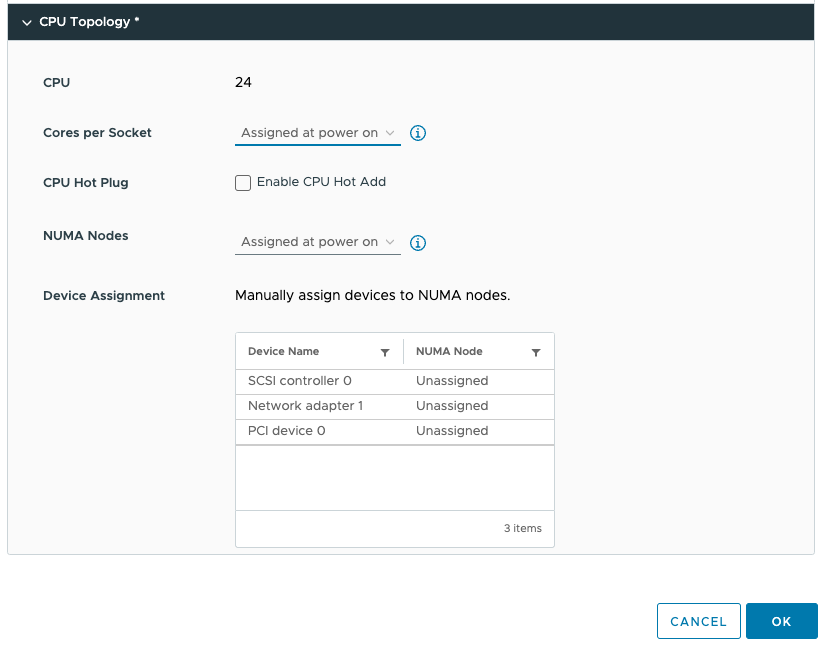
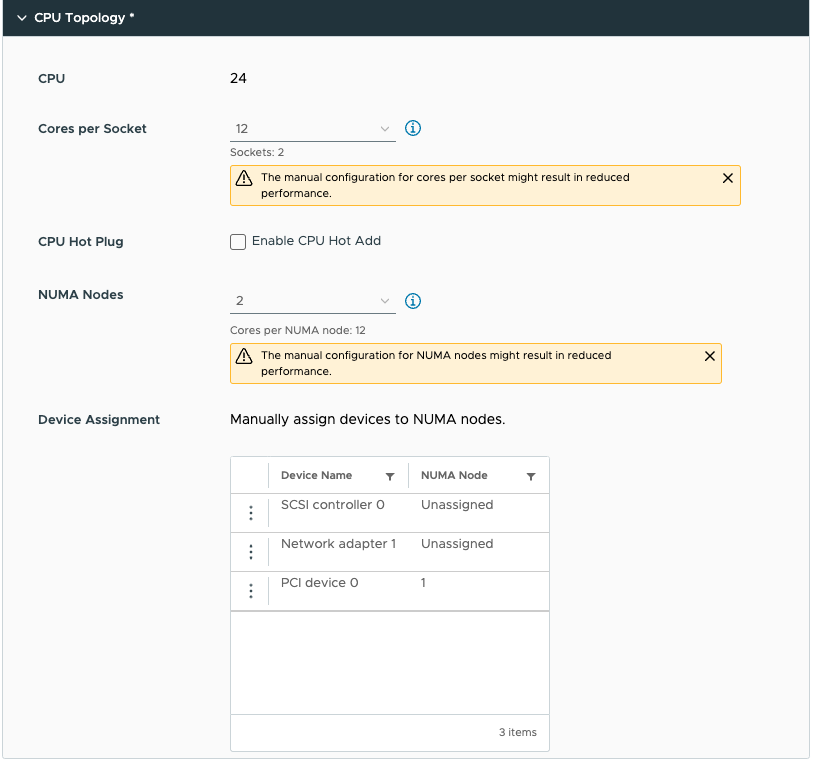
By default, the Cores per Socket and NUMA Nodes settings are “assigned at power on” and this prevents you from assigning any PCI device to any NUMA node. To be able to assign PCI devices to NUMA nodes, you need to change the Cores per Socket setting. Immediately, a warning indicates that you need to know what you are doing, as incorrectly configuring the Cores per Socket can lead to performance degradation. Typically we recommend aligning the cores per socket to the physical layout of the server. In my case, my ESXi host system is a dual-socket server, and each CPU package contains 20 cores. By default, the NUMA scheduler maps vCPU to cores for NUMA client sizing; thus, this VM configuration cannot fit inside a single physical NUMA node. The NUMA scheduler will distribute the vCPUs across two NUMA clients equally; thus, 12 vCPUs will be placed per NUMA node (socket). As a result, the Cores per Socket configuration should be 12 Cores per Socket, which will inform ESXi to create two virtual sockets for that particular VM. For completeness’ sake, I specified two NUMA nodes as well. This setting is a PER-VM setting, it is not NUMA Nodes per Socket. You can easily leave this to the default setting, as ESXi will create a vNUMA topology based on the Cores per Socket settings. Unless you want to create some funky topology that your application absolutely requires. My recommendation, keep this one set to default as much as possible unless your application developer begs you otherwise.
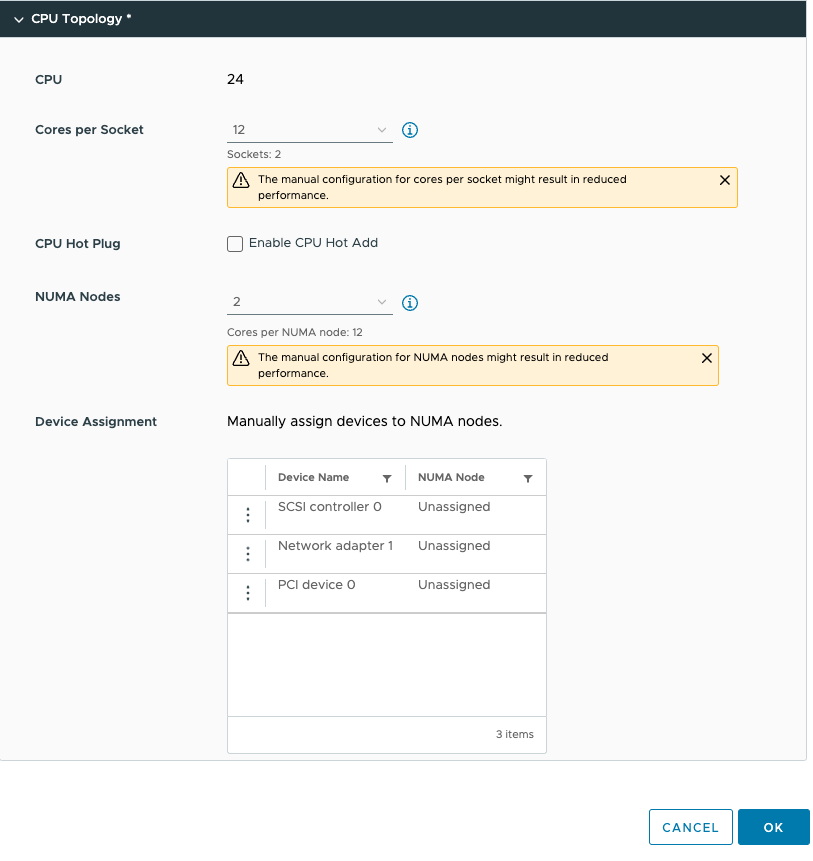
This allows us to configure the PCIe devices. As you might have noticed, I’ve added a PCIe device. This device is an NVIDIA A30 GPU in Dynamic Direct Path I/O (Passthrough) mode. But before we dive into the details of this device, let’s look at the virtual machine’s configuration from within the guest OS. I’ve installed Ubuntu 22.04 LTS and used the command lstopo. (install using: sudo apt install hwloc)
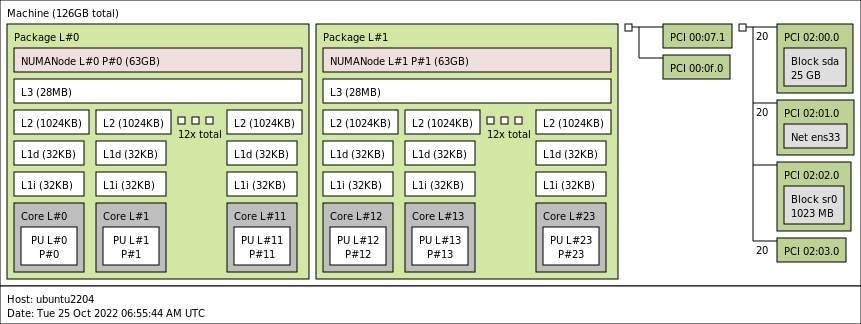
You see the two NUMA nodes, with each twelve vCPUs (Cores) and a separate PCI structure. This is the way a virtual motherboard is structured. Compare this to a physical machine, and you notice that each PCI device is attached to the PCI controller that is located within the NUMA node.
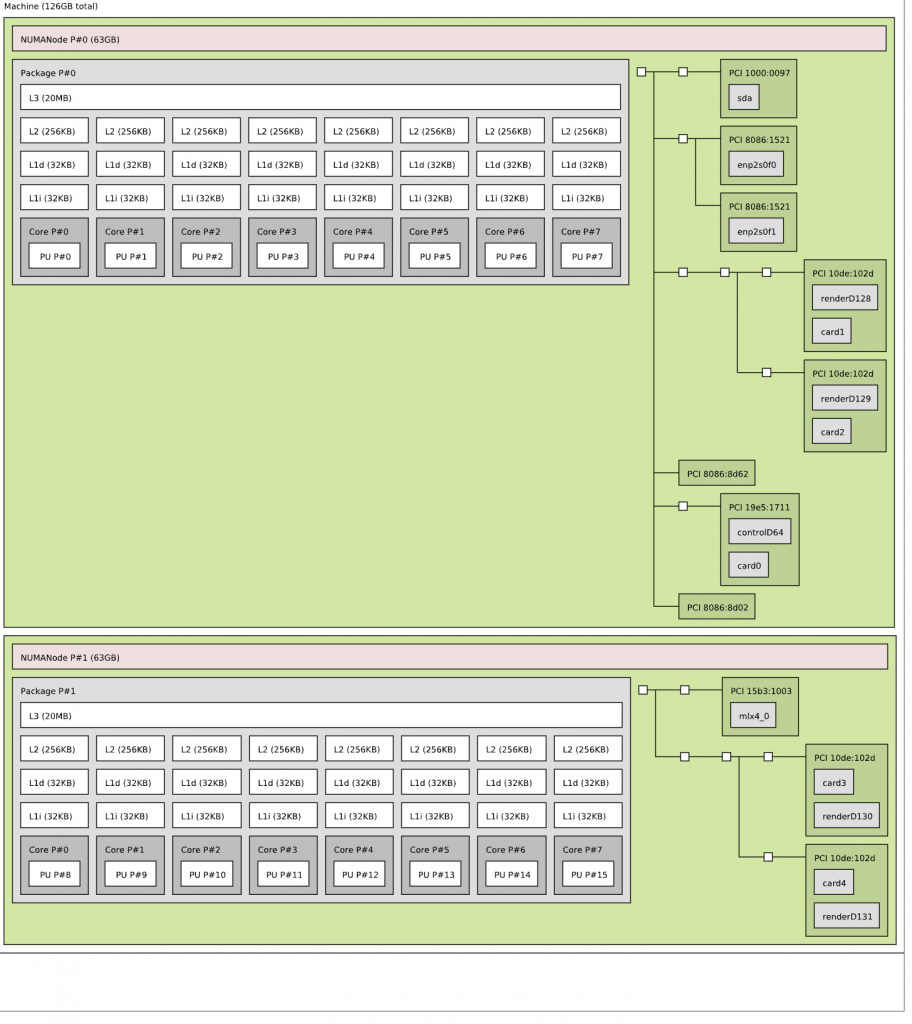
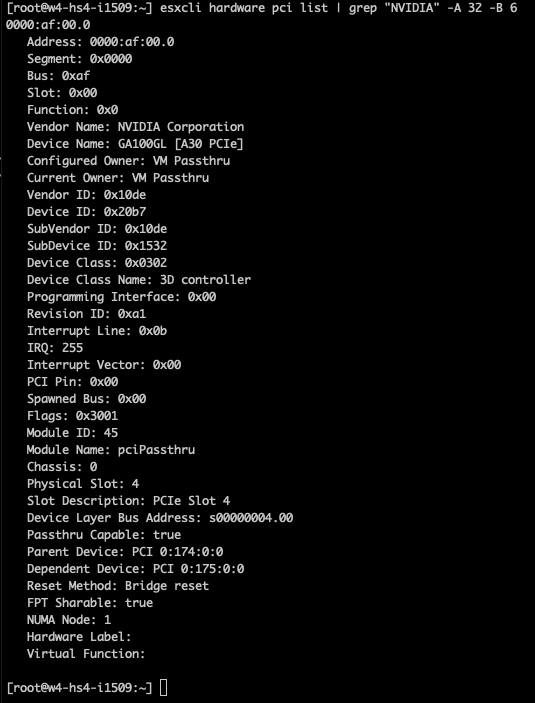
In the case of the A30, we need to understand its PCIe-NUMA locality. The easiest way to do this is to log on to the ESXi server through an SSH session and search for the device via the esxcli hardware pci list command. As I’m searching for an NVIDIA device, I can restrict the output of this command by using the following command “esxcli hardware pci list | grep “NVIDIA -A 32 -B 6”. This instructs the grep command to output 32 lines (A)after and 6 lines (B)before the NVIDIA line. The output shows us that the A30 card is managed by the PCI controller located in NUMA node 1 (Third line from the bottom).
We can now adjust the device assignment accordingly and assign it to NUMA node 1. Please note the feature allows you to also assign it to NUMA node 0. You are on your own here. You can do silly things. But just because you can, doesn’t mean you should. Please understand that most PCIe slots on a server motherboard are directly connected to the CPU socket, and thus a direct physical connection exists between the NIC or the GPU and the CPU. You cannot logically change this within the ESXi schedulers. The only thing you can do is to map the virtual world as close to the physical world as possible to keep everything as clear and transparent as possible. I mapped PCI device 0 (the A30) to NUMA node 1.
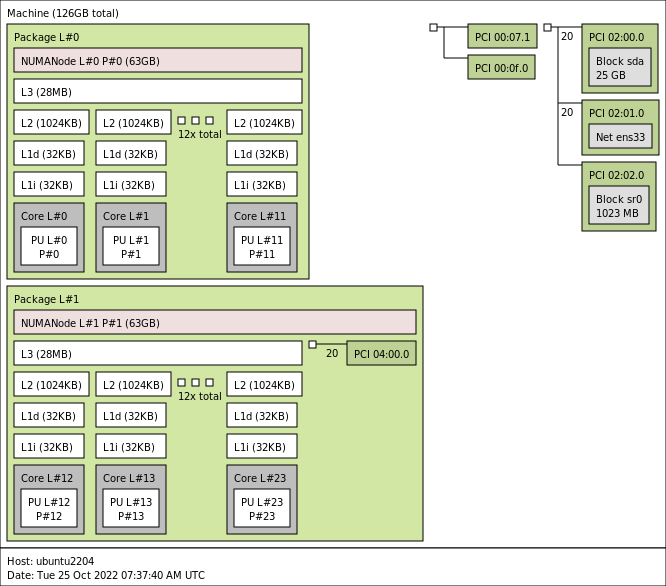
Running lstopo in the virtual machine provided me this result:



dumb question but does a similar potential performance gain exist with ryzen cpu’s based upon the Core Complexes (CCXs) on a Core Complex Die (CCD) assignments?
I know we have https://www.amd.com/system/files/documents/2019-amd-epyc-7002-tg-vmware-vsphere-56779_1.0.pdf and https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/performance/vsphere70u2-cpu-sched-amd-epyc.pdf as general info but have things changed since then regarding this with esxi 8?
Not a dumb question at all. There are some improvements in vSphere 8 for AMD, but the key elements EPYC users need to know are listed in your documents. Keep your workloads within the CCD size, and you get fast speeds. But if you size wrong and use non-NUMA optimized workloads on EPYC, the only thing you can hope for is that people still unconditionally love you. 😉