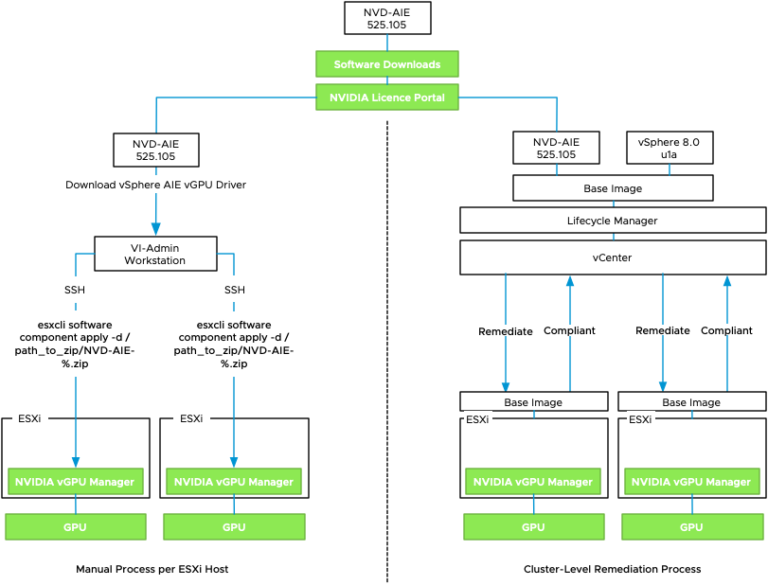
Many organizations are in the process of deploying large language models to apply to their use cases. Publically available Large Language Models (LLMs), such as ChatGPT, are trained on publicly available data through September 2021. However, they are unaware of proprietary private data. Such information is critical to the majority of enterprise processes. To help an LLM to become a useful tool in the enterprise space, an LLM is further trained of finetuned on proprietary data to adapt to organization-specific concepts.
This process introduces terminology that is used more often outside the data science community. Having a better understanding of the following concepts should enhance your ability to navigate the data science team’s requirements when building an LLM deployment architecture.
Neural Network: A Large Language Model (LLM) is a sophisticated neural network architecture designed for natural language processing tasks. LLMs use multiple layers of interconnected nodes to learn language patterns from vast amounts of text data. Parameters, specifically weights, and biases, are crucial components that define how the model processes information.
Weights govern the strength of connections between nodes, influencing the LLM’s ability to capture linguistic nuances. Biases adjust the activation levels of nodes, allowing the model to adapt its responses. During forward propagation, the input text is transformed into tokens and flows through the network, undergoing contextual analysis and predicting subsequent words or phrases.
Backward propagation, an integral part of training, calculates gradients to adjust weights and biases. This process refines the model’s parameters, aligning its language generation with human-written text. Through continuous learning, LLMs become adept at tasks like completing text, translating, and generating new content.
Large Language Model: A Large Language Model is a specific Natural Language Processing (NLP) model that predicts the next word or token. Compared to other NLP models (which are based on language models LM), they are characterized by their size (parameter count of >1B) and are typically trained on vast amounts of text data from the internet. This enables them to learn a broad range of language features and general knowledge. LLMs can handle a number of tasks, from summarization to content generation to question and answer. NLP models are typically focused on sentiment analysis and text classification. LLMs can be further fine-tuned for various tasks with minimal additional training, while NLP is less versatile and requires extensive task-specific training.
Foundation model: A foundation model is an LLM, sometimes referred to as a Pretrained Language Model (PLM), that is robust enough to act as a “foundation” that can be used as is or fine-tuned/adapted for newer domains. In general, it is trained on diverse data, capable of being customized and fine-tuned for various applications and tasks. For example, the open-source LLaMA 2 models are trained on 2 trillion tokens primarily sourced from publicly available online data sources. Meta required 368640 GPU (A100-80 GBs) hours to train the 13B LLaMa-2 model.
Token: A token is a fundamental unit of text that an LLM uses to process and understand language. In English, a token can be as short as a single character or as long as a word. For example, in the sentence “I love vSphere,” there are three tokens: “I,” “love,” and “vSphere.” However, the word “vSphere” might be broken down into two tokens depending on the model’s tokenizer. Token length is important because it can impact the overall size of the input data, computational resources required for processing, and the model’s ability to perform linguistically. Tokens help break down the text into manageable pieces for analysis and are essential for language generation. They serve as the building blocks that allow LLMs to comprehend human language.
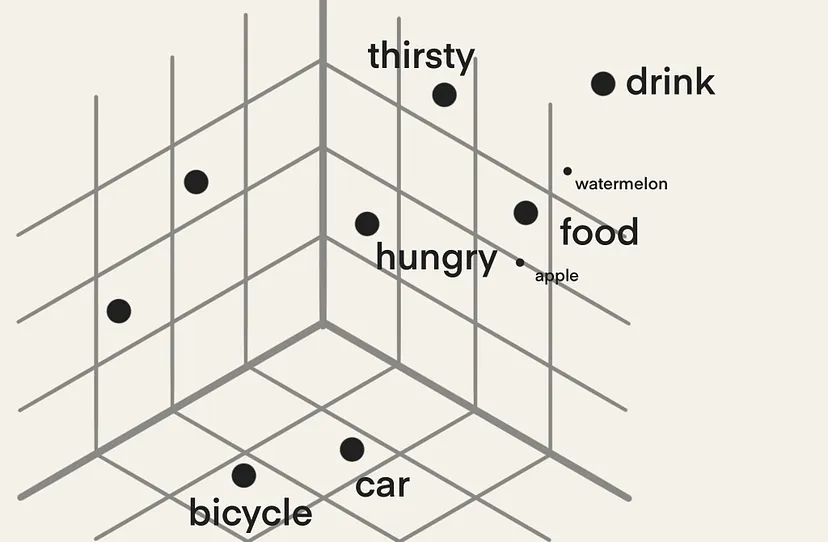
Embeddings: are numerical representations of tokens. Each token is transformed into a vector of numbers. These vectors encode the semantic meaning of the text and facilitate computer-based processing and analysis of human language. This language-to-number translation equips machine-learning processes to interact with language data efficiently.
Vector: Vectors are commonly used to represent data points in a multi-dimensional space. Each element of a vector corresponds to a specific dimension, and the combination of these elements defines the position of the vector in that space. Vectors are essential for measuring similarities and transforming data. The article “Explaining Vector Databases in 3 Levels of Difficulty” provides a great primer on vectors, embeddings, and Vector databases.
Parameters: Parameters are the learned values that a model acquires through training to facilitate predictions or classifications on new data. In neural networks, these parameters are commonly denoted as weights and biases, dictating how input data undergoes transformation into output predictions.
An LLM model size is typically expressed in parameter count in billions, such as the LLaMA-2 13B. This model contains roughly 13 Billion parameters. The memory consumption depends on the floating-point format (precision). Typically for LLM, a BF16 or FP16 is used. A parameter using BF16 consumes 2 bytes. 1 Billion bytes equal a gigabyte. Thus, we can easily calculate the “static” model memory consumption. LLaMA-2 13B consumes 26 GB of GPU memory when loaded into the GPU. Streaming data into the LLM or fine-tuning the model increases memory consumption.
Transformer Architecture: The transformer architecture is a foundational framework for training and utilizing large neural networks in natural language processing (NLP). It revolutionized the field by introducing the attention mechanism, which allows the model to weigh the importance of different words in a sentence. It introduced a self-attention mechanism to process input data in parallel, allowing it to truly understand the context of words depending on other words that are placed further away within the sentence (long-range dependencies). The transformer architecture has an encoder and decoder functionality. The encoder creates a “contextualized representation” of a prompt, capturing the meaning and significance of the words in the prompt by considering how they relate to each other within the given context. The decoder receives and processes the contextualized representation, using its understanding of the context to guide output generation. Typically, it generates one word of the output at a time. The first word generated is based on the input context, and the next word is generated based on the input context and the previously generated word. This is called autoregressive context.
(Downstream) Task: An LLM is typically refined further to achieve a specific goal or perform a particular downstream task. Many foundation models today can perform a wide range of NLP tasks without refinement for a particular downstream task. A “task” refers to a specific job or activity that the model is designed to perform using its language understanding and generation capabilities. Tasks can include a wide range of natural language processing objectives. The most common ones are text generation (predicting the next word/token), summarization (given an input, return a short output), question answering (predicting the next word/token based on search results in the prompt), sentiment analysis, translation, and instruction. When a new downstream task is needed, we still need to fine-tune the foundation LLM to respond to domain-specific prompts (eg; ensure it favors a particular term, “Tanzu,” over others).
Prompt: A prompt is a specific input given to the model to guide its behavior and generate desired text output. The prompt serves as an instruction or query that helps the LLM understand the task or context it needs to respond to. It can be a sentence, a paragraph, or even just a few keywords, depending on the task at hand. For example, if technical marketing wants an LLM to generate a technical specification overview, they can use the prompt “Write a detailed description of our latest update release, highlighting its unique features and capabilities.”
Prompt engineering: The quality and specificity of the prompt can greatly influence the LLM’s output. A well-crafted prompt provides clear guidance to the model, leading to more relevant and accurate generated text. Prompt engineering involves designing prompts effectively to achieve the desired results for various tasks such as translation, summarization, question answering, and more. Prompt engineering can also be used to induce LLMs to say undesirable things, for example, with a prompt that tells an LLM to forget its existing rules before responding.
Zero-shot: refers to the model’s ability to perform tasks or generate text about new topics without additional training or examples in the prompt. It relies on its existing knowledge to tackle new challenges without requiring specific learning for each one.
P-tuning: This technique involves fine-tuning a small trainable model prior to engaging the LLM. The small model encodes the text prompt and crafts task-specific virtual tokens, which are then added to the prompt and fed into the LLM. Once the fine-tuning is done, these virtual tokens are stored in a lookup table and used during inference, replacing the smaller model. P-tuning is far more resource efficient compared to other forms of fine-tuning of an LLM. The time required to tune a smaller model can often be measured in minutes instead of days with fine-tuning the LLM. This is a great talk about P-tuning and what exactly virtual tokens are.
Parameter Efficient Fine-Tuning: PEFT aims to make the fine-tuning process more efficient by focusing on updating only a subset of the model’s parameters (e.g., 100M parameters for a 15B model), rather than retraining the entire model from the ground up. The idea behind PEFT is to balance retaining the knowledge captured by the pre-trained model and tailoring it to perform well on a specific task. By carefully selecting and adjusting certain parameters, you can achieve good performance on the task while reducing the computational cost and time required for fine-tuning. PEFT also overcomes the issues of catastrophic forgetting, a behavior observed during the full fine-tuning of LLMs. There are multiple PEFT methods: :
Adapter-based PEFT: Adapters are new modules added to the pre-trained network, and only the new parameters are trained, while the original LLM-trained parameters are left untouched. As a result, a small proportion of parameters of the original LLM is trained. This means that the model keeps remembering the previous tasks and uses a small number of new parameters to learn the new task. However, the downside of adding these new layers is the inference latency increase. This issue appears unavoidable because the adapter layers are added sequentially to an LLM. They must be processed sequentially, and there is no way to parallel process them.
LoRA: Low-Rank Adaptation of Large Language Models: LoRA also freezes the pre-trained parameters, but instead of adding additional layers to the neural network, it adds values to the parameters. As a result, the model can be executed fully in parallel, avoiding additional inferencing latency. In addition, LoRA applies a very intelligent method to reduce the number of trainable parameters, reducing fine-tuning time and memory consumption. A further reduction of memory consumption can be achieved by quantizing the majority (non-outliers) trainable parameters, which results in using an integer data type (INT8) instead of a floating point. A parameter stored in INT8 consumes 8 bits, reducing the memory footprint in half compared to BF16. This is the most popular method of PEFT.
Quantized Low-Ranking Adaptation (QLoRA): QLoRA takes it one step further and compresses the weights and activations to 4-bit precision. QLoRA uses a specific data type for storing the base model weights and data type to perform computations. During the computations, QLoRA “dequantizes” the weights from a 4-bit precision (4-bit NormalFloat) into a 16-bit bfloat. The weights are only decompressed when needed; therefore, QLoRA allows large models to run on GPUs with smaller memory capacities.
IA3 (Infused Adapter by Inhibiting and Amplifying Inner Activations): IA3 is a newer PEFT technique intended to improve over LoRA. It offers the same benefits as the LoRA. However, it’s only tested on really “small” LLM models (3B) currently, and most backends do not support this yet. The last update on the GitHub IA3 repo was done in September 2022, which might hint at a lack of popularity of this PEFT method in the data science community.
Fine Tuning: Fine-tuning is the mechanism to improve LLM models for a specific task (e.g., summarizing legal documents) or domain (e.g., more knowledge about virtualization). During the training of an LLM, the neural network is exposed to unlabeled data and learns through a form of self-supervision (e.g., predicting the next word or sentence entailment). That means that the algorithm explores the patterns, structures, and relationships within the dataset on its own without being provided with specific labeled output for every task, but the robustness of its dataset may mean that it will already be good at some tasks (eg; generating coherent sounding sentences). Fine-tuning always involves supervised learning, where human labelers validate and curate data for a specific task (e.g., to fine-tune the model’s question-answering capabilities, we would have question and answer pairs as the input).
Reinforcement Learning with Human Feedback (RLHF): When validating the accuracy of a model designed for an image recognition task, we can quickly determine its accuracy. It either classifies the cat correctly or not. With LLMs, it’s a bit more challenging, as it is more difficult to define what makes a “good” text as it is subjective and context-dependent.
The RHLF method uses feedback generated by humans for generated text to measure the model performance. The method involves deploying multiple models during the training process. A pretrained language model and typically a smaller reward model. The PLM generates multiple responses based on a prompt and a reward model numerical scores each response on how well humans perceive this text. It ranks the response according to human preference and then applies reinforcement learning to train the PLM further to prioritize the response with the higher numerical scores.
RHLF systems are complex and challenging as gathering human preference data is expensive. RLHF performance is only as good as the quality of the human annotations. People tend to disagree. Therefore, ground truth is often lacking due to variance in opinions by the annotating team. There are multiple methods of human feedback besides the preference order, such as:
- Corrections: Upvoting or downvoting the model output (also known as prompt completion)
- Demonstrations: Humans write the preferred answer to a prompt
- Natural Language Input: Humans are asked to provide feedback on the model output in natural language
Supervised fine-tuning (SFT): involves adapting a PLM to a specific downstream task using validated training examples. Validated training examples are pairs of input data and output labels that have been carefully checked and confirmed to be accurate and reliable. SFT tunes the model to a specific task, such as responding to customer support questions. The model can be trained to adapt to specific knowledge-based or demonstrate a particular persona or empathy by using validated training examples.
Is PEFT considered supervised learning?: PEFT is not strictly categorized as supervised learning; rather, it is a technique that can be applied within the context of supervised learning. Supervised learning involves training a model on labeled data pairs, where the labels serve as the ground truth for training. PEFT, on the other hand, is a method that aims to fine-tune a pre-trained model using a limited amount of new data specific to a task to adapt the model’s parameters while leveraging its existing knowledge. PEFT is characterized by its emphasis on efficiency and parameter reuse. It does not require extensive retraining on the entire dataset, as it focuses on updating only a subset of the model’s parameters to adapt it to a new task.
In-Context Learning
Retrieval Augmented Generation (RAG): Once an LLM is trained, it is ignorant of new data. When an organization launches a new product or service, the customer service-focused LLM needs to be retrained to incorporate these new data points. RAG allows the LLM to act as a conversational interface, while RAG “grounds” the LLM with information that aligns with its use case while reducing hallucinations. RAG allows LLMs to access knowledge sources outside the trained model and augment the completion of the prompt with relevant information found in external sources. These sources can be the organizations’ proprietary data sources, like knowledge bases, Bugzilla, Confluence, internal documents, etc. RAG typically works together with a Vector Database or a search engine.
When the user provides the prompt to the LLM, the RAG framework performs a “contextual search” on the Vector database and generates the context. The RAG framework augments the original prompt by injecting the context into the prompt. The LLM receives the enriched prompt and can generate a better response as it has access to factual data. The LLM sends the generated response back to the user.
RAG frameworks and Vector DBs can be critical differentiators for organizations with rapidly changing knowledge bases or any other source of information. These organizations cannot change the LLM and redeploy at the same velocity as the demand for up-to-date information. Keeping the models’ answers in lock-step with the velocity of their service offering is challenging. A good example is a FAQ for a chatbot function at a call center for a new product or service. The data science team can add up-to-date data to the Vector DB answer and question domains and ensure that the RAG framework prioritizes the Vector DB over the LLM model for information retrieval.
Grounding: refers to the process of connecting the model’s prompt completion (responses) to real-world knowledge. Grounding is about ensuring that the model’s outputs are coherent, accurate, and relevant to the information available in the world. Pretraining, prompt-engineering, fine-tuning, and in-context learning all help to ground the LLM.
Hallucination: a hallucination is a confident response by the LLM that appears coherent and contextually relevant but is not based on accurate information from the input data or is not logically grounded in reality. An example is URLs that are generated by an LLM that does not exist.
Guardrails: Guardrails restrict LLMs to respond in a particular (safe) manner. These guardrails guide the LLM to stay on topic, avoid hallucinations or toxic responses, or execute malicious code. Chatbots can become an attack surface, and a security guardrail can protect LLM platforms. Guardrails are programmable constraints and are placed between the chatbot and the LLM. The NVIDIA NeMo framework offers a guardrail workflow to apply constraints to the LLM easily.