Last week Duncan and I were guests on the ever popular Virtually Speaking Podcast. In this show we discussed the difference in technical writing, i.e., writing a blog post versus writing a book. We spoke a lot about the challenges of writing a book and the importance of a supporting cast. We received a lot of great feedback on social media, and Pete told me the episode was downloaded more than a 1000 times in the first 24 hours. I think this is especially impressive as he published the podcast on a Saturday Afternoon. Due to this popularity, I thought it might be cool to share the episode in case you missed the announcement.
Pete and John shared the links to our VMworld sessions on this page. During the show, I mentioned the VMworld session of Katarina Wagnerova and Mark Brookfield. If you go to VMworld, I would recommend attending this session. It’s always interesting to hear people talk about how they designed an environment and dealt with problems in a very isolated place on earth.
Enjoy listening to the show.

Resource Consumption of Encrypted vMotion
vSphere 6.5 introduced encrypted vMotion and encrypts vMotion traffic if the destination and source host are capable of supporting encrypted vMotion. If true, vMotion traffic consumes more CPU cycles on both the source and destination host. This article zooms in on the impact of CPU consumption of encrypted vMotion on the vSphere cluster and how DRS leverages this new(ish) technology.
CPU Consumption of vMotion Process
ESXi reserves CPU resources on both the destination and the source host to ensure vMotion can consume the available bandwidth. ESXi only takes the number of vMotion NICs, and their respective speed into account, the number of vMotion operations does not affect the total of CPU resources reserved! 10% of a CPU core for a 1 GbE NIC, 100% of a CPU core for a 10 GbE NIC. vMotion is configured with a minimum reservation of 30%. Therefore, if you have 1 GbE NIC configured for vMotion, it reserves at least 30% of a single core.
Encrypted vMotion
As mentioned, vSphere 6.5 introduced encrypted vMotion and by doing so it also introduced a new stream channel architecture. When an encrypted vMotion process is started, 3 stream channels are created. Prepare, Encrypt and Transmit. The encryption and decryption process consumes CPU cycles and to reduce the overhead as much as possible, the encrypted vMotion process uses the AES-NI Instruction set of the physical CPU.
AES-NI stands for Advanced Encryption Standard- New Instruction and was introduced in the Intel Westmere-EP generation (2010) and AMD Bulldozer (2011). It’s safe to say that most data centers run on AES-NI equipped CPUs. However, if the source or destination host is not equipped with AES-NI, vMotion automatically reverts to unencrypted if the default setting is selected.
Although the encrypted vMotion leverages special CPU hardware instructions set to offload overhead, it does increase the CPU utilization. The technical paper “VMware vSphere Encrypted vMotion Architecture, Performance, and Best Practices” published by VMware list the overhead on the source and destination host.
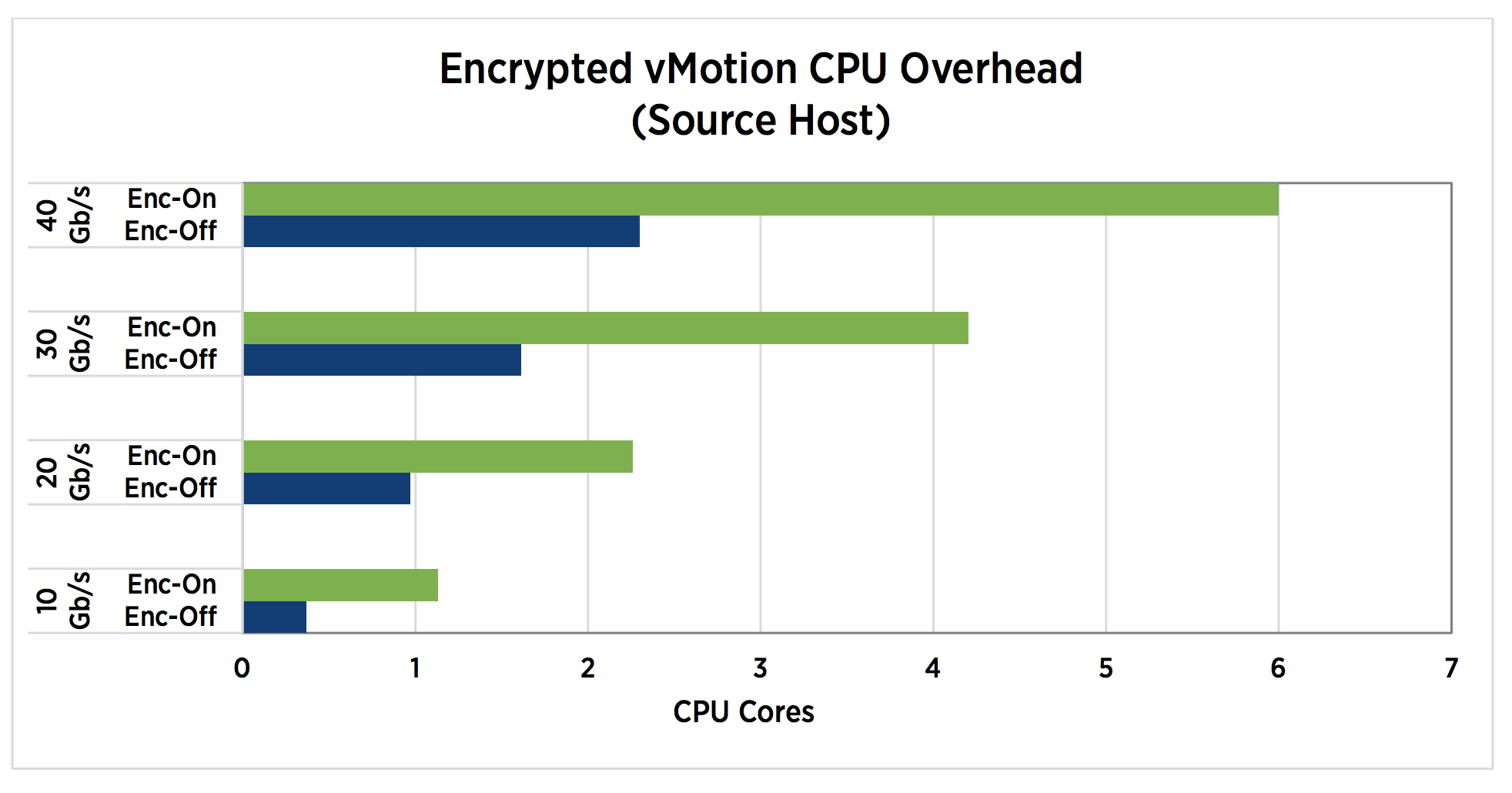
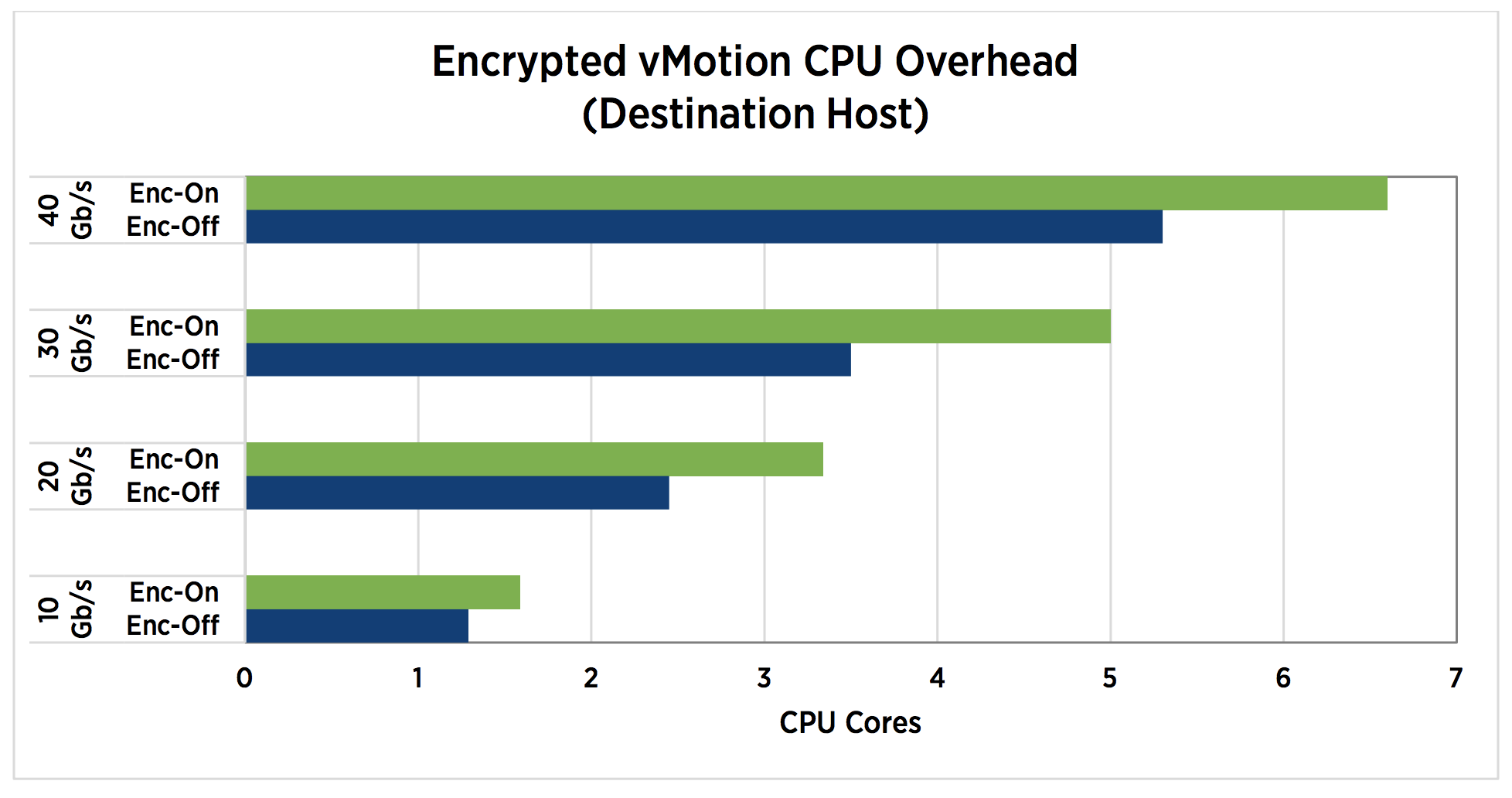
Encrypted vMotion is a per-VM setting, by default, every VM is configured with Encrypted vMotion set to Opportunistic. The three settings are:

| Setting | Behavior |
|---|---|
| Disabled | Does not use encrypted vMotion |
| Opportunistic | Use encrypted vMotion if the source and destination host supports it. Only vSphere 6.5 and later use encrypted vMotion |
| Required | Only allow encrypted vMotion. If the source and destination host does not support encrypted vMotion, migration with vMotion is not allowed. |
Please be aware that encrypted vMotion settings are transparent to DRS. DRS generates a load balancing migration, and when the vMotion process starts, the vMotion process verifies the requirements. Due to the transparency, DRS does not take encrypted vMotion settings and host compatibility into account when generating a recommendation.
If you select required, because of security standards, it is important to understand if you are running a heterogeneous cluster with various vSphere versions. Is every host in your cluster 6.5 otherwise you are impacting the ability of DRS to load-balance optimally. Or are different types of CPU generations inside the cluster, do they support AES-NI? Please make sure the BIOS version supports AES-NI and make sure AES-NI is enabled in the BIOS! Also, verify if the applied Enhanced vMotion Compatibility (EVC) baseline exposes AES-NI.
CPU Headroom
It is important to keep some unreserved and unallocated CPU resources available for the vMotion process, to avoid creating gridlock. DRS needs some resources to run its threads, and vMotion requires resources to move VMs to lesser utilized ESXi host. Know that encrypted vMotion taxes the system more, in oversaturated clusters, it might be interesting to understand whether your security officer state encrypted vMotion as a requirement.
Stretched Clusters on VMware Cloud on AWS, a Really Big Thing
This week Emad published an excellent article about the stretched cluster functionality of VMware Cloud on AWS. To sum up, you can now deploy a single vSphere cluster across two AWS availability zones.

A trip to Memory Lane
I think the ability to stretch a vSphere cluster across two availability zones is a really big thing. Go back to the days where we had to refactor the application to make it highly available. To reduce application downtime, you typically used clustering software such as Microsoft cluster or Veritas clustering services. But not all applications were fit for this solution.
When we introduced VMware High Availability back in 2006, we brought a big change to the industry. From that point on you could provide crash-consistent failover ability to all your workloads. No need to refactor any application, no need to build outlandish hardware solutions. Just enable a few tickboxes at the infrastructure layer, and every workload running inside a VM is protected. And to this day, HA remains the most popular functionality of vSphere.
Amazon Web Services Resiliency Strategy
Amazon urges you to design your application to be resilient to infrastructure outages. Amazon AWS is hosted in multiple locations worldwide. These locations are composed of regions and Availability Zones. Each region is a separate geographic area that has multiple, isolated locations known as Availability Zones. AWS provides the ability to place instances and data in multiple locations.
And you can take advantage of the safety and reliability of geographic redundancy by spanning your Auto Scaling group across multiple Availability Zones within a region and then attach a load balancer to distribute incoming traffic across those Availability Zones. Incoming traffic is distributed equally across all Availability Zones enabled for your load balancer.
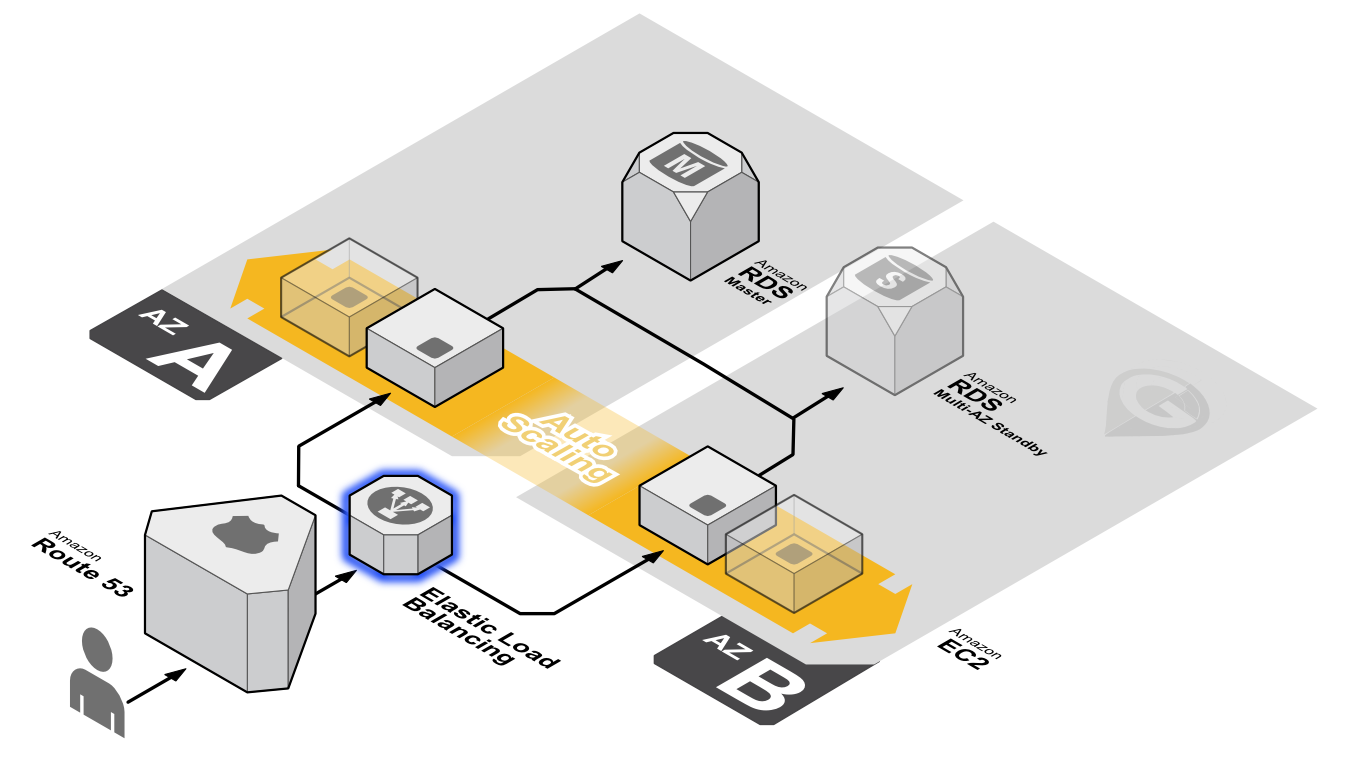
And this works very well if you are refactoring your application or if you are building a complete new cloud-native stack. The challenge we face today is that not all applications lend to getting refactored, or some applications do not require the journey from monolithic to full-FAAS.
Hybrid-Cloud Experience
With stretched clusters in VMware Cloud on AWS, we introduce the same ease of infrastructure resiliency to workloads that run on AWS infrastructure. Merely expand you vSphere cluster to 6 hosts and select multi-az deployment.
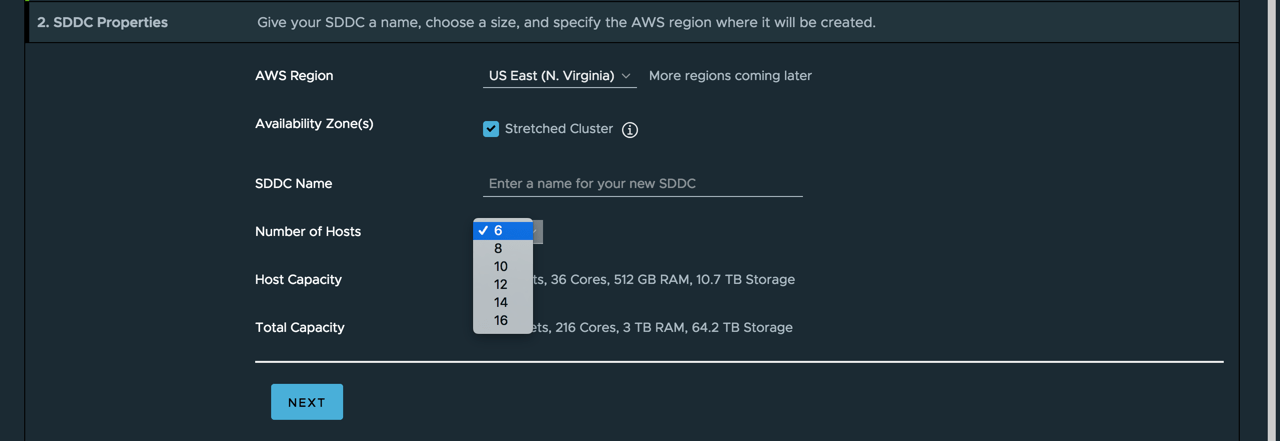
After that, the workload in the Cloud SDDC is protected for AZ outages. If something happens, HA detects the failed VMs and restarts them on different physical servers in the remaining AZ without manual human involvement.
The ability to stretch your vSphere cluster across AZs allows you to easily provide resiliency to your workload within the AWS infrastructure without the Herculean effort of refactoring all your applications.
Dying Home Lab – Feedback Welcome
The servers in my home lab are dying on a daily basis. After four years of active duty, I think they have the right to retire. So I need something else. But what? I can’t rent lab space as I work with unreleased ESXi code. I’ve been waiting for the Intel Xeon D 21xx Supermicro systems, but I have the feeling that Elon will reach Mars before we see these systems widely available. The system that I have in mind is the following:
- Intel Xeon Silver 4108 – 8 Core at 1.8 GHz (85TDP)
- Supermicro X11SPM-TF (6 DIMMs, 2 x 10 GbE)
- 4 x Kingston Premier 16GB 2133
- Intel Optane M.2 2280 32 GB
CPU
Intel Xeon Silver 4108 8 Core. I need to have a healthy number of cores in my system to run some test workload. Primarily to understand host and cluster scheduling. I do not need to run performance tests, thus no need for screaming fast CPU cores. TDP value of 85W. I know there is a 4109T with a TDP value of 70W, but they are very hard to get in the Netherlands.
Motherboard
Supermicro X11SPM-TF.Rocksolid Supermicro, 2 x Intel X722 10GbE NICs onboard and IPMI.
Memory
Kingston Premier 4 x 16 GB 2133 MHz. DDR4 money is nearing HP Printer Ink prices, 2133 MHz is fast enough for my testing, and I don’t need to test 6 channels of RAM at the moment. The motherboard is equipped with 6 DIMM slots, so if memory prices are reducing, I can expand my system.
Boot Device
Intel Optane M.2 32 GB. ESXi still needs to have a boot device, no need to put in 256 GB SSD.
This is the config I’m considering. What do you think? Any recommendations or alternate views?
Dedicated Hardware in a Public Cloud World
One of the more persistent misconceptions is that the components of VMware’s Software Defined Data Center (SDDC) on VMware Cloud on AWS are virtualized or that the deployed VMs run natively on Amazon. And to be honest, it’s not even weird that most people think this way. After all, Amazon Web Services launched in March 2006, 12 years ago. AWS and Elastic Compute Cloud (EC2) and Amazon Simple Storage Service (S3) are synonymous with each other. All of a sudden, you can know “run vSphere on AWS”.
To be short and sweet, VMware Cloud on AWS runs on physical hardware, it is not virtualized and running inside EC2 instances!
VMware Cloud is consuming the AWS infrastructure and using a bare-metal service offered by AWS. Of course, it is not as simple as installing vSphere on a bare-metal server and you got yourself a fully elastic cloud service. More than that needs to happen. VMware Cloud on AWS is a partnership between the two companies and both have done some extensive R&D work to make this happen. If you want to know more, Chris Wagner – Principle Architect of the service presented an excellent session (LHC3174BU) at VMworld on how we built it.
Back to the service offering, when deploying an SDDC, by default a four node cluster is erected. Four physical hosts are assigned to a single customer account, and the service installs, patches and rolls out the full SDDC stack of vSphere, vSAN, and NSX. You just have to log on to vCenter and start deploying workloads.

Each ESXi host provides 36 CPU cores of 2.3 GHz (72 threads), 512 GB of RAM and 10.7 TB of raw storage capacity for the virtual machines to consume. As a result, a default vSphere cluster provides 144 CPU cores (288 threads), 2 TB of RAM and 42.8 TB of raw storage capacity. All physical resources!
Due to leveraging the scale of AWS data centers and its operational framework, the VMware Cloud on AWS fleet management service can deploy physical resources on demand! By logging into the console (vmc.vmware.com) you can add and remove physical host to the cluster.
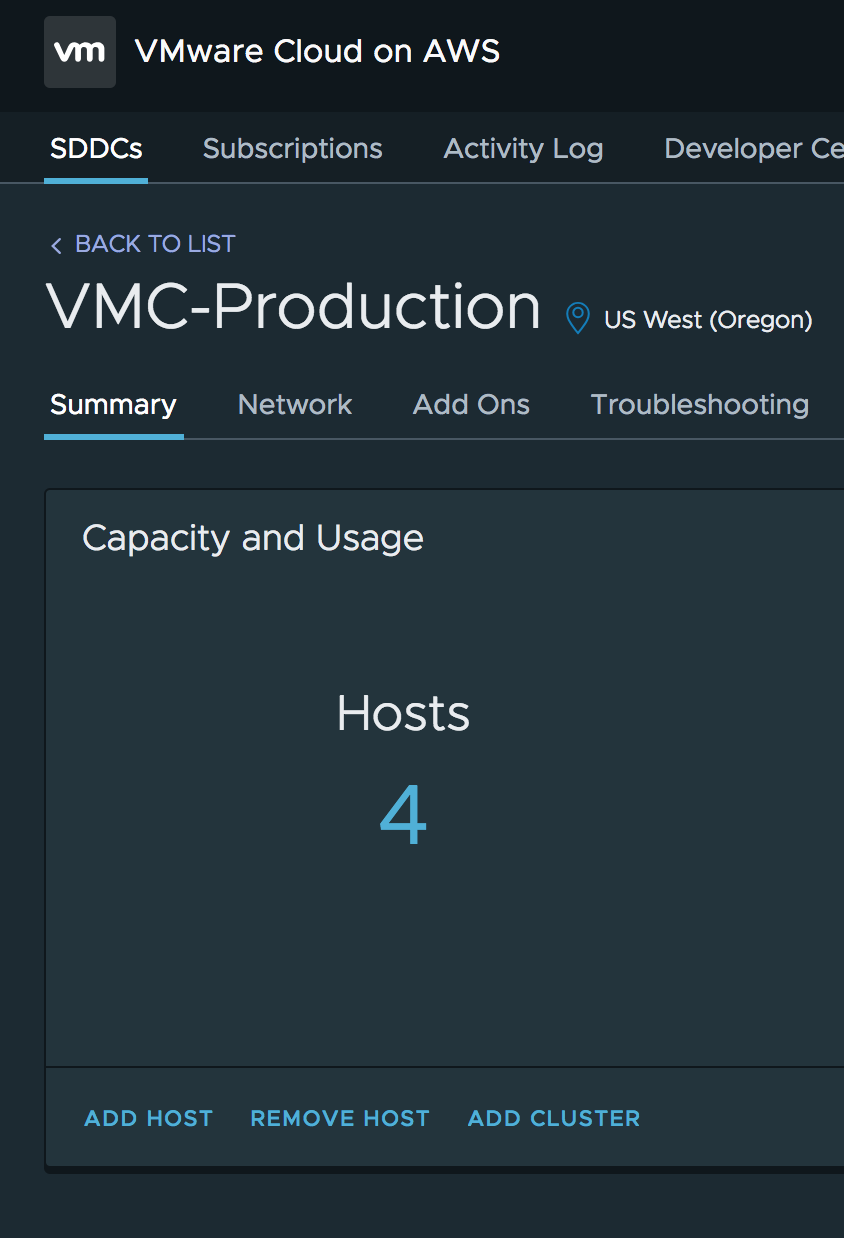
This allows you add physical hardware to the cluster, whenever you need it. No more long procurement process, no more waiting for the vendor to ship the goods. No more racking, stacking in a cold dark datacenter. Just with a few clicks, you get fresh new hardware added to your cluster, fully installed, configured, patched and ready to go. Typically this takes about 10 minutes for VMware Cloud on AWS to add a single physical host to your vSphere cluster. I’ve been to data centers that it took me more than 10 minutes to arrive at the correct cabinet.
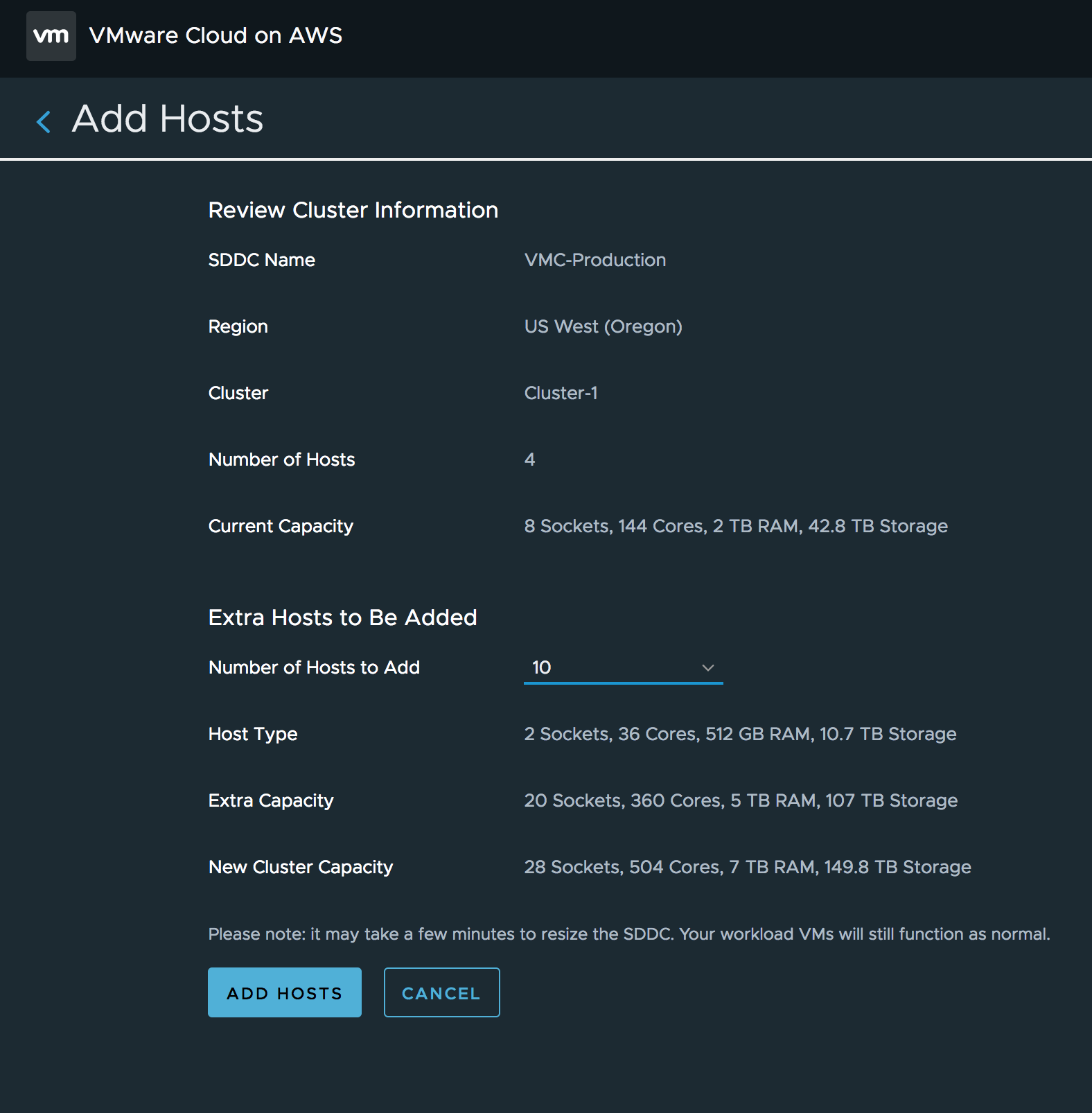
If one is not enough, you can add up to 28 ESXi hosts in the cluster. In the example above, I added 10 additional hosts. The console list the host type, the extra capacity added by this action (10 ESXi hosts = 360 Cores, 5 TB RAM and 107 TB of Storage and sums the new cluster capacity.
If you want to isolate specific workloads and add a separate cluster, just go right ahead and select the add cluster option in the console.
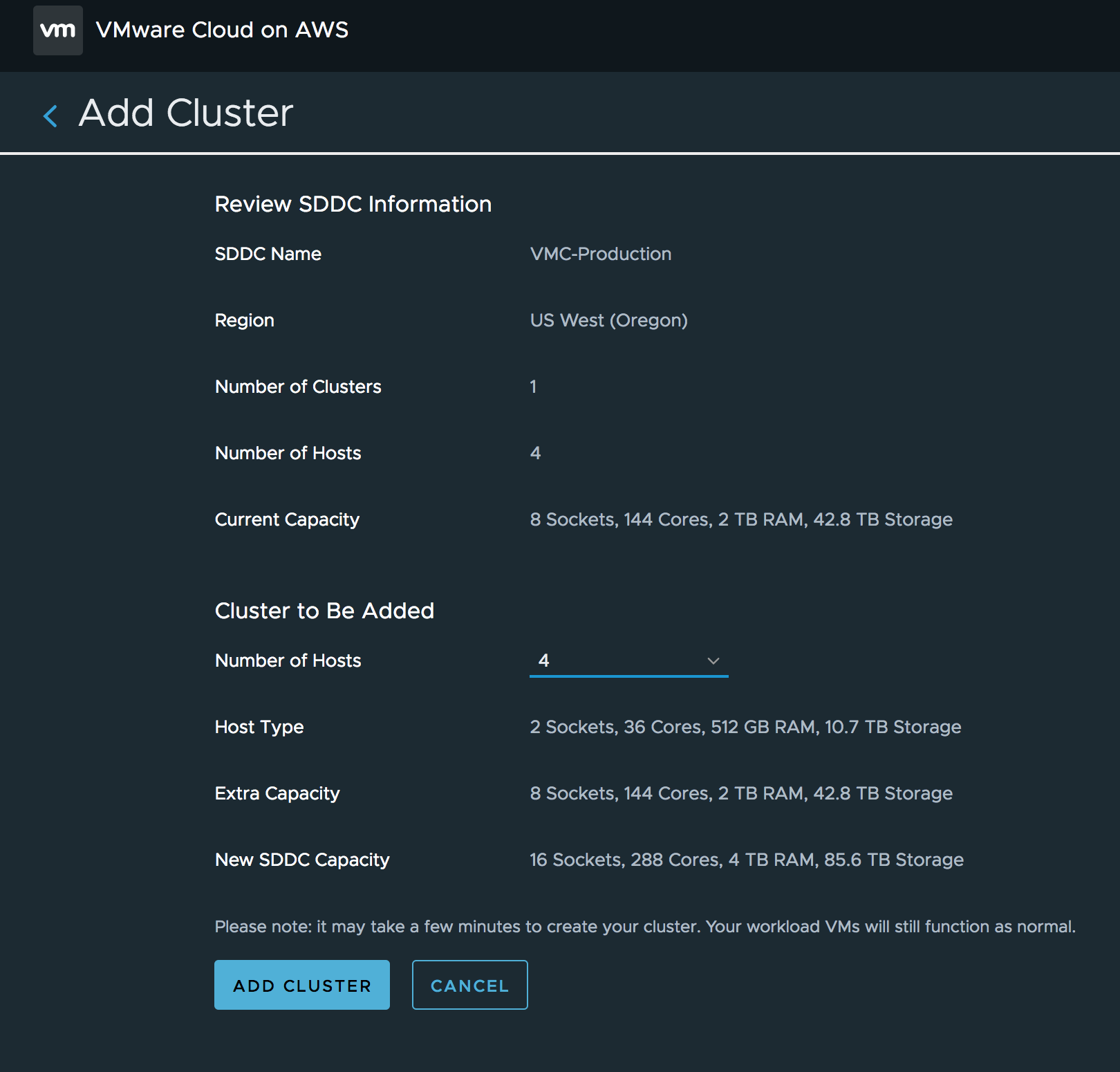
In total, a VMware Cloud on AWS customer can deploy up to 10 clusters of each 32 ESXi hosts in a single SDDC. In total two SDDCs can be erected. That means that a customer can have 23040 of physical CPU cores, 327 TB of memory and 6.8 Petabyte of storage. All physical hardware.
You can imagine all this is done by firing off a collection of API-calls to get this process orchestrated. The beauty of having this functionality capacity-by-code is that you can incorporate it into software features, such as vSphere HA and DRS. An upcoming new feature is Elastic DRS. In short, the ability to scale out and scale the cluster with physical hardware whenever workload demand requires it. I will provide a more in-depth view once we release this new feature.