Follow
frankdenneman.nl
CPU
Machine Learning
NUMA
Podcast
About Me
Privacy Policy
GPU
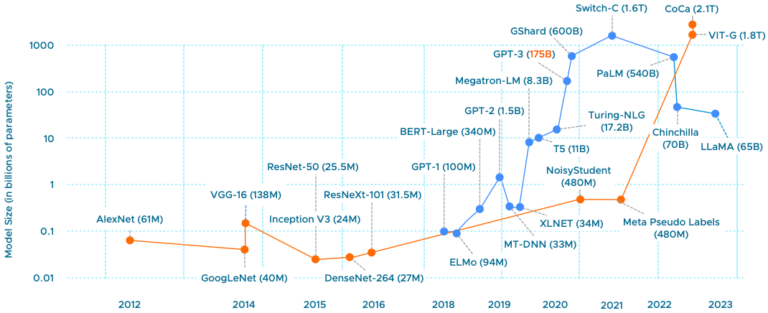
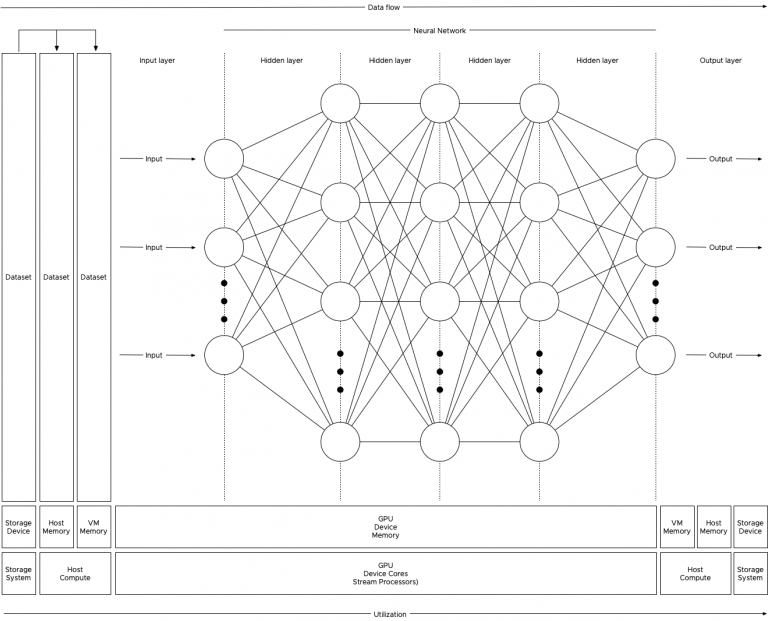
vSphere ML Accelerator Spectrum Deep Dive for Distributed Training – Multi-GPU
The first part of the series reviewed the capabilities of the vSphere platform to assign fractional and full GPU to workloads....
Machine Learning Workload and GPGPU NUMA Node Locality
In the previous article “PCIe Device NUMA Node Locality” I covered the physical connection between the processor and the PCIe device...