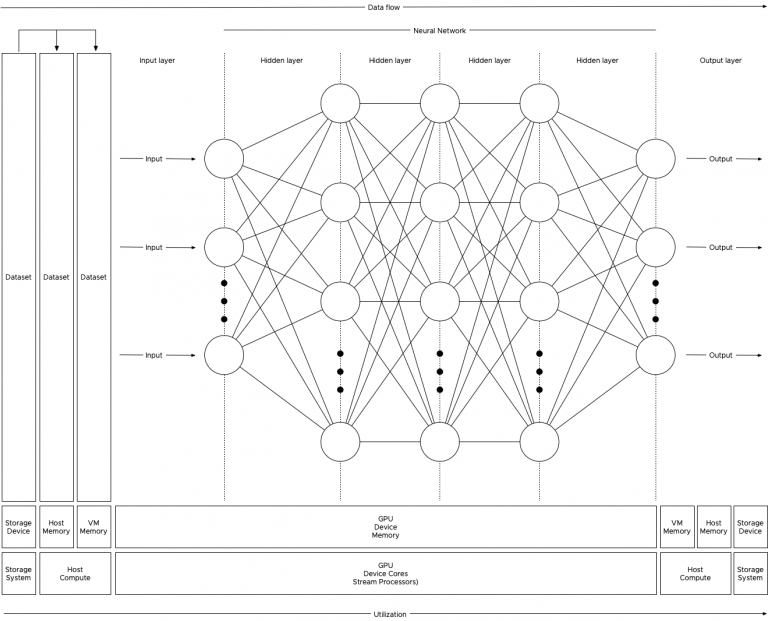
CPU

Sapphire Rapids Memory Configuration
The 4th generation of the Intel Xeon Scalable Processors (codenamed Sapphire Rapids) was released early this year, and I’ve been trying...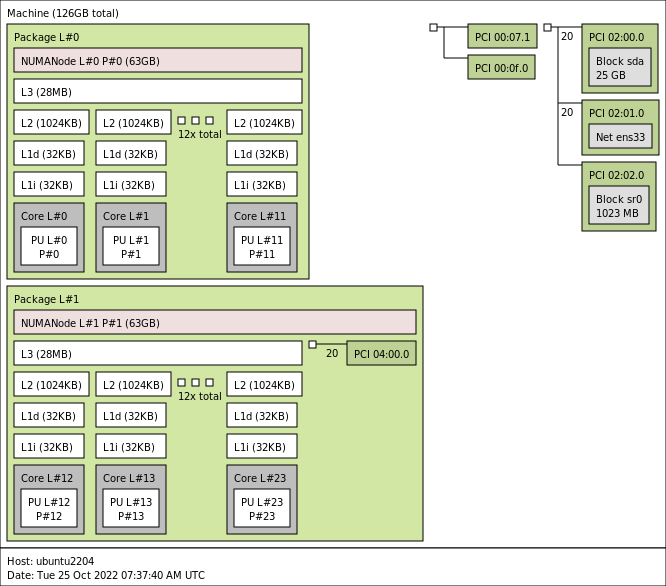
vSphere 8 CPU Topology Device Assignment
There seems to be some misunderstanding about the new vSphere 8 CPU Topology Device Assignment feature, and I hope this article...