DRS
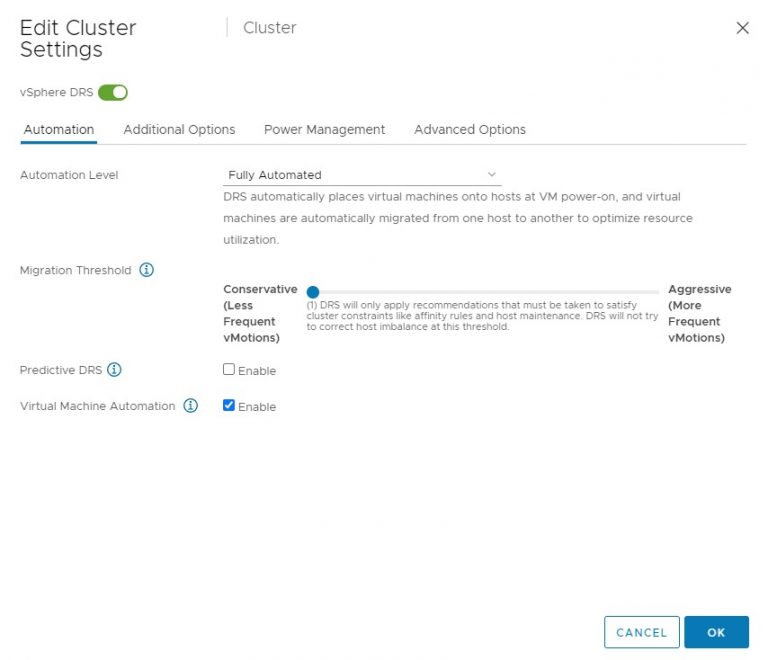
DRS threshold 1 does not initiate Load balancing vMotions
vSphere 7.0 introduces DRS 2.0 and its new load balancing algorithm. In essence, the new DRS is completely focused on taking...
New whitepaper available on vSphere 7 DRS Load Balancing
vSphere 7 contains the new DRS algorithm that differs tremendously from the old one. The performance team has put the new...vSphere 7 DRS Scalable Shares Deep Dive
You are one tickbox away from completely overhauling the way you look at resource pools. Yes you can still use them...DRS Migration Threshold in vSphere 7
DRS in vSphere 7 is equipped with a new algorithm. The old algorithm measured the load of each host in the...