vSphere
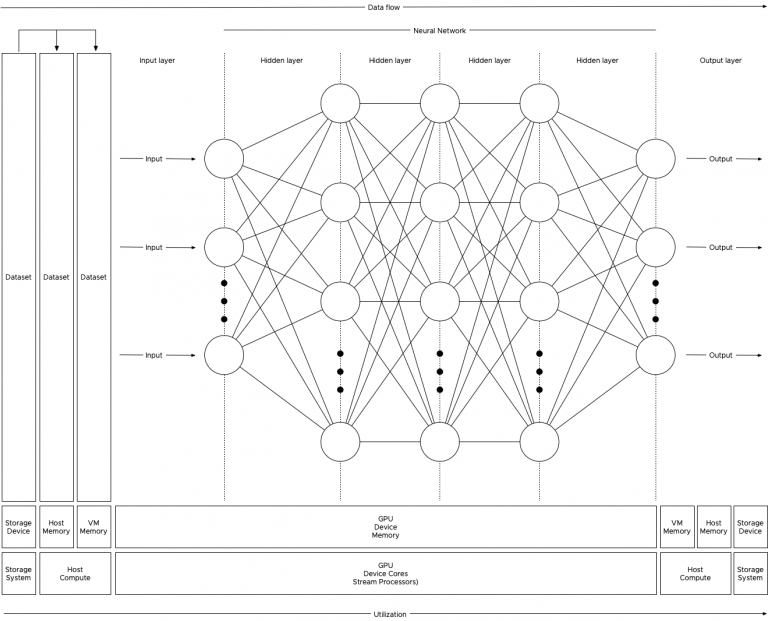
In the previous article “PCIe Device NUMA Node Locality” I covered the physical connection between the processor and the PCIe device...
Last week Duncan and I were guests on the ever popular Virtually Speaking Podcast. In this show we discussed the difference...
Today someone asked if the congestion threshold of SIOC is related to which host latency threshold? Is it the Device average...
After skipping both VMworld events in 2008 I’m attending the VMworld event in San Francisco. This is the first event after VMware released vSphere...