The previous article “Initial Placement of a vSphere Pod,” covered the internal construction of a vSphere Pod to show that it is a combination of a tailor-made VM construct and a group of containers. Both the Kubernetes and vSphere platforms contain a rich set of resource management controls, policies, and features that guide, control, or restrict scheduling of workloads. Both control planes use similar types of expressions, creating a (false) sense of unification in the context of managing a vSphere pod. This series of articles examines the overlap of the different control plane dialects, and how the new vSphere 7 platform allows the developer to use Kubernetes native expressions, while the vSphere Admin continues to use the familiar vSphere native resource management functionalities.
Workload Deployment Process
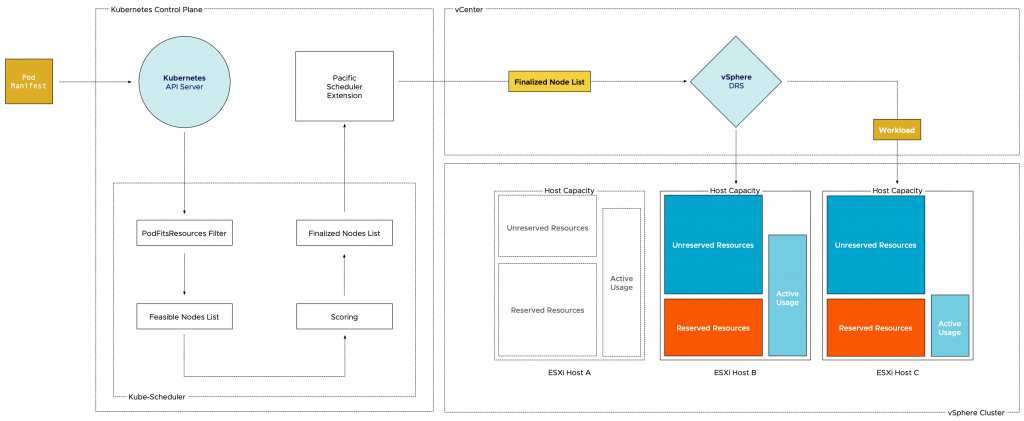
Both control planes implement a similar process to deploy a workload, the workload needs to be scheduled on a resource producer (worker node, or ESXi host), the control plane selects a resource producer based on the criteria presented by the resource consumer (pod manifest / VM configuration). The control plane verifies which resource producer is equipped with enough resource capacity, if there are enough resources available and if it meets the criteria listed in the pod manifest/VM configuration. An instruction is sent over to the workload producer to initiate a power-up process of the workload.

The difference between the deployment processes of containers and virtual machines is the size aspect. A virtual machine is defined by its virtual hardware and this configuration acts as a boundary for the guest OS and its processes (hence the strong isolation aspect of a virtual machine). A container is a controlled process and uses an abstract OS to control the resource allocation, there is no direct hardware configuration assigned to a process. And this difference introduces a few interesting challenges when you want to run a container natively on a hypervisor. The hypervisor requires workload constructs to define their hardware configuration so it can schedule the workloads and manage resource allocation between active workloads. How do you size a construct that might provide you with absolutely no hints on expected resource usage? You can prescribe an arbitrary hardware configuration, but then you miss out on capturing the intent of the developer if he or she wants the application to be able to burst and temporarily use more resources than it structurally needs. You do not want to create a new resource management paradigm, where developers need to change their current methods of deploying workloads, you want to be able to accept new workloads with the least amount of manual effort. But having these control planes work together is not only a process of solving challenges, it provides the ability to enrich the user experience as well. This article explores the difference in resource scheduler behavior and how Kubernetes resource requests, limits, and QoS policies affect vSphere pod sizing. It starts off by introducing Kubernetes constructs and Kubernetes scheduling to provide enough background information to understand how it can impact vSphere pod sizing and eventually placement of a vSphere pod.
Managing Compute Resources for Containers
In Kubernetes, you can specify how much resources a container can consume (limits) and how many resources the worker node must allocate to a container (request). These are similar to vSphere VM reservations and limits. Similar to vSphere, Kubernetes selects a worker node (Kubernetes term for a host that runs workload), based on the request (reservation) of a container. In vSphere, the atomic unit to assign reservation, shares, and limits is the virtual machine, in Kubernetes, it’s the container. It sounds straight-forward, but there is a bit of a catch.
A container is deployed not directly onto a Kubernetes Worker Node, but it is encapsulated in a higher-level construct called a pod. In short, the reason why a pod exists is that it’s expected to run a single process in a container. If an app exists out of multiple processes, a group of containers should exist, and you do not want to manage a group of processes independently, but the app itself, hence the existence of a pod. What’s the catch? Although you deploy a pod, you have to specify the resource allocation settings per container and not per pod. But since a pod is an atomic unit for scheduling, the requests of all the containers inside the pod are summed, and the result is used for worker node selection. Once the pod is placed, the worker node resource scheduler has to take care of each container request and limits individually. But that is a topic for a future article. Let’s take a closer look at a pod manifest.

Container Size Thinking versus VM Size Thinking
The pod manifest list two containers, each equipped with a request and a limit for both CPU and memory. A CPU can be expressed in a few different ways. 1 equals to 1 CPU, which is the same as a hyperthread of an Intel processor. If that seems lavishly outlandish, you can actually use a smaller unit of expression by using millicpu or decimals. That means that 0.5 means half of a hyperthread or 500 millicpu. For a seasoned vSphere admin, you are now exploring the other end of the spectrum, instead of dealing with users who are demanding 64 Cores, we are now trying to split atoms here. With memory, you can express memory requirements in plain integers (126754378954) or fixed-point integers using suffixes 64MiB (226 bytes). Kubernetes.Io documentation can help you with which fixed-point integer exists. In this example, the pod request is 128 Mi of memory and 500m of CPU resources.
Kubernetes Scheduling
During the process of initial placement of the container, the scheduler needs to check the “compatibility” first. After the Kubernetes scheduler has considered the taints and tolerations, the pod affinity and anti-affinity, and the node affinity, it looks at the node capacity to understand if it can satisfy the pod requests (128Mi and 500m CPU). To be more precise, it inspects the “node allocatable.” This is the number of resources that is available for pods to consume. Kubernetes reserves some resources of the node to make sure system daemons and itself can run without risking resource starvation. The node allocatable resources are divided into two parts, allocated and unallocated. The total of allocated resources is the sum of all request configurations of all active containers on the worker node. As a result, Kubernetes matches the request stated in the pod manifest and the unallocated resources listed by each worker node in the cluster. The node with the most unallocated resources is selected to run the pod. To be clear, Kubernetes’ initial placement does not consider actual resource usage.
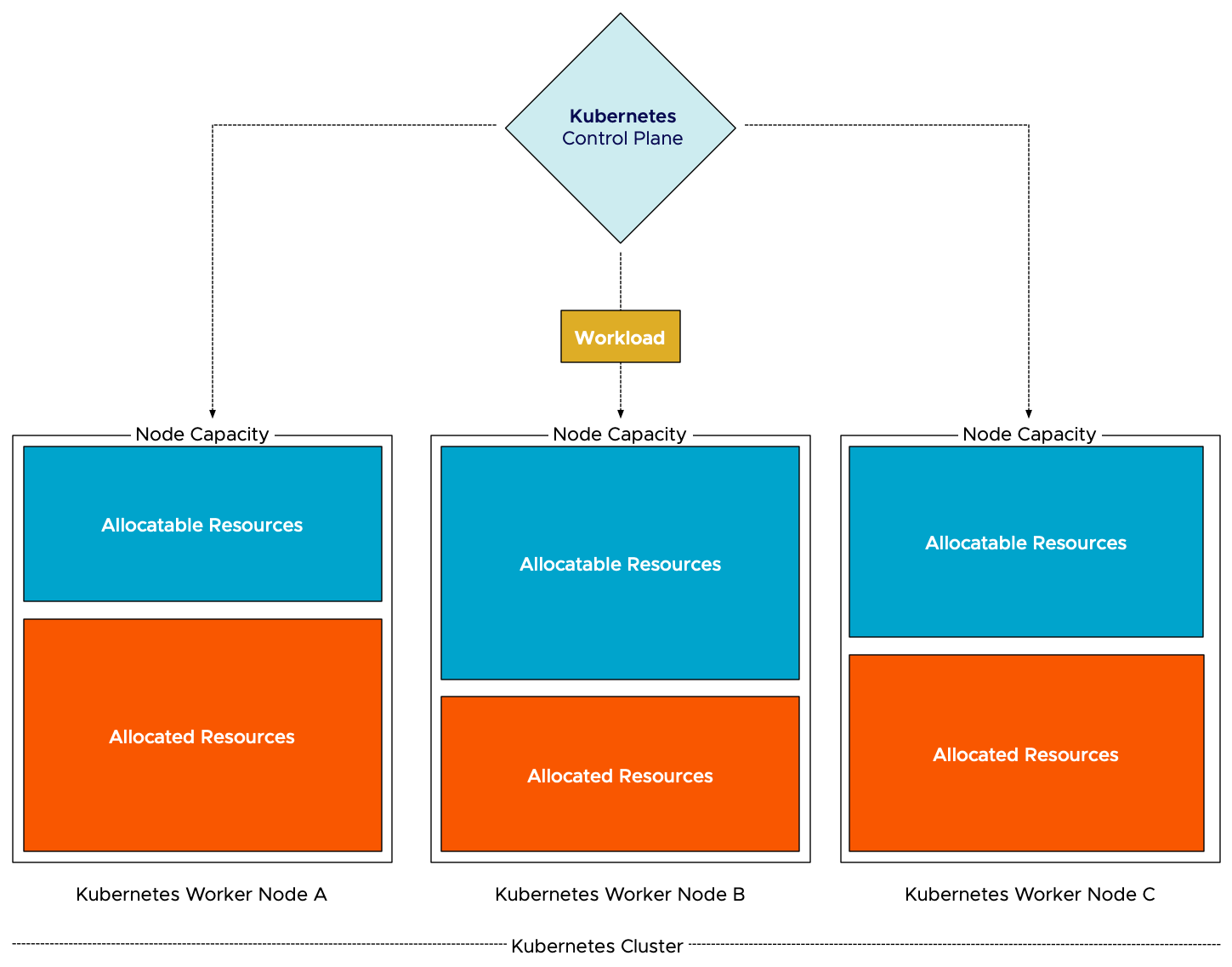
As depicted in the diagram, the workload needs to be scheduled. The Kubernetes control plane reviews the individual worker nodes, filters the nodes out which node can fit the pods, and then selects the node based on the configured prioritization function. The most used function is the “LeastRequestedPriority” option, which favors worker nodes with fewer requested resources. As node B has the least amount of reserved resources, the scheduler deems this node to be the best candidate to run the workload.
vSphere Scheduling
DRS has a more extensive resource scheduling model. The method used by Kubernetes is more or less in-line with the vSphere admission control model. Kubernetes scheduling contains more nuances and features than I just described in the paragraphs above. It checks if a node is reporting memory pressure, allowing it to exclude from the node selection list (CheckNodeMemoryPressure), and a priority functionality is in beta, but overall looking at reserved and unreserved memory can be considered to be a little bit coarse. vSphere has three admission controls that all work together to ensure continuity and resource availability. DRS resource scheduling aligns the host resource availability, with the resource entitlement of the workload. Reservations, shares, limits, and actual resource usage of a workload is used to determine the appropriate host. Now you might want to argue that a workload that needs to be placed does not use any resources yet, so how does this work?
During initial placement, DRS considers the configured size as resource entitlement, in this case the resource entitlement is a worst-case scenario. So a VM with a hardware configuration of 4 vCPUs and 16 GB has a resource entitlement before power-up of 4 vCPUs and 16GB plus some overhead for running the VM (VM overhead). However, if a reservation is set of 8GB, then the resource entitlement is now switched to a minimum resource entitlement of 4 vCPU, 8GB+VM overhead. A host must have at least have 8GB(+VM overhead ) of unreserved resources available to be considered. How is this different from Kubernetes? Well, this part isn’t. The key is taking the future state of a workload into consideration. DRS understands the actual resource usage (and the entitlement) of all other active workloads running on the different hosts. And thus, it has an accurate view of the ability (and possibility) of the workload to perform on each host. Entitlement indicates the number of resources the workload has the right to consume; as such, it also functions as a form of prediction, an estimation on workload pressure. Would you rather place a new workload on a crowded host or on one that is less busy?
In this example, there are three hosts, each with 100 GB of memory capacity. Host A has workload active that has reserved 60 GBs of memory. 40 GB of memory is unreserved. Host B and host C have workload active that have reserved 40 GBs of memory. 60GBs of memory is unreserved. A new workload with a 35 GB reservation comes in. The Kubernetes scheduler would have considered both hosts to be equally good. However, DRS is aware of active use. Host B has an active resource consumption of 70 GB, while host C has an active use of 45 GBs. As host B resource usage is closer to its capacity, DRS selects host C as the destination host for initial placement.

Considering active resource usage of other active resource consumers, whether they are VM constructs or containers in vSphere pods, creates a platform that is more capable of satisfying intent. If a pod is configured with a burstable Quality of Service class (limit exceeds request), the developer declares the intent that the workload should be able to consume more resources if available. With initial placement enriched with active host resource usage, the probability of having that capability is highly increased.
Managing Compute Resources for vSphere Pods
Seeing that a vSphere pod is a combination of containers and a VM construct, both control planes interact with the different components of the vSphere pod. But some of the qualities of the different constructs impact the other constructs’ behavior, for example, sizing. A VM is a construct defined by its hardware configuration. In essence, a VM is virtualized hardware, and the scheduler needs to understand the boundaries of the VM to place and schedule it properly. This configuration acts as a boundary of the world where the guest OS lives in. A guest OS cannot see beyond the borders of a VM, and therefore it acts and optimizes for the world it lives in. It has no concept of “outer-space”. A container is the opposite of this. A container is, contrary to its definition, not a rigid or a solid structure. It’s a group of processes that are contained by features to isolate or “contain” resource usage (control groups). Compare this to a process or an application on a Windows machine. When you start or configure an application, you are not defining how many CPUs or memory that particular app can consume. You hope it doesn’t behave like Galactus (better known as Google Chrome) and that it just won’t eat up all your resources. That means that a process in Windows can see all the resources the host (i.e., laptop or virtual machine) contains. The same applies to Linux containers. A container can see all the resources that are available to its host; the limit setting restricts it to consume above this boundary. And that means that if no limit is set, the container should be able to consume as much as the worker node can provide. I.e., in VM-sizing terms, the size of the container is equal to the size worker node. If this container was to run inside a vSphere pod, the vSphere pod should have the size of the ESXi host. Although we all love our monster-VMs, we shouldn’t be doing this. Especially when most expressions of container resource management borders on splitting atoms, and are not intended to introduce planet-sized container entities in the data center.
Kubernetes QoS Classes and the impact of vSphere Pod Sizing
A very interesting behavior of Kubernetes is the implicit definition of Quality of Service (QoS) classes due to combinations of limits and requests definition in the pod manifest. As seen in the introduction of this article, a pod manifest contains limits and requests definitions of each container. However, these specifications are entirely optional. Based on the combination used, Kubernetes automatically assigns a QoS class to the containers inside the pod. And based on Qos classes, reclamation occurs. A developer well versed in the Kubernetes dialect understands this behavior and configures the pod manifest accordingly. Let’s take a look at the three QoS classes to understand a developers’ intent better.

Three Qos Classes exist BestEffort class, Burstable class, and Guaranteed class. If no requests and limits are set on all containers in the pod manifest, the BestEffort class is assigned to that pod. That means all containers in that pod can allocate as many resources as they want, but they are also the first containers to be evicted if resource pressure occurs. If all containers in the pod manifest contain both a memory and CPU requests and the request equals the limit, then Kubernetes assigns the Guaranteed QoS class to the Pod. Guaranteed pods are the last candidates to be hit if resource contention occurs. Every other thinkable combination of CPU and memory requests and limits ensures that Kubernetes assigns the Burstable class. It is important not to disrupt the expected behavior of resource allocation and reclamation and as a result, the requests and limits used in the pod manifest are used as guidance for vSphere Pod sizing while keeping the expected reclamation behavior of the various combinations.
If there is no limit set on a container, how must vSphere interpret this when sizing the vSphere pod? To prevent host-sized vSphere pods, a default container size is introduced. It’s on a per-container basis. To be exact, if a simplest pod with one container and no request/limit settings is created, that vSphere Pod will get 1 vCPU and 512 MB. It actually gets 0.5 cores by default, but if there is only one container we will round the vCPU up to 1. Why not on a pod basis? Simply because of scalability reasons, the size of the Pod scales up with the number of BestEffort containers inside. If a request or a limit is set, that is larger than the default size, than this metric is used to determine the size of the container. If the pod manifest contains multiple containers, the largest metric of each container is added and the result is used as a vSphere pod size. For example, a pod contains two containers, each with a request and limit that are greater than the default size of the container. The CPU limit exceeds the size of the CPU request, as a result, vSphere uses the sum of both CPU limits, and adds a little padding for the components that are responsible for the pod lifecycle, pod configuration, and vSpherelet interaction. A similar calculation is done for memory.

Initial Placement of Containers Inside a vSphere Pod on vSphere with Kubernetes
When a developer pushes a pod manifest to the Kubernetes control plane, the Kube-Scheduler is required to find an appropriate worker node. In the Kubernetes dialect, the worker-node that meets the resource allocation requirements of the pod is called a feasible node. In order to determine which nodes are feasible, Kube-Scheduler will filter the nodes that do not have enough unallocated resources that are required to satisfy the listed requests in the pod manifest. The second step in the process done by the Kube-Scheduler is to score each feasible node in the list based on additional requirements, such as affinity and labels. The ranked list is sent over to the Pacific Scheduler Extension which in turn sends it over to the vSphere API server, who forwards it to the vSphere DRS service. DRS determines which host aligns best with the resource requirements and is the most suitable candidate to ensure that the vSphere pod reaches the highest happiness score (getting the resources the vSphere pod is entitled to). The vSphere Pod LifeCycle Controller ensures that the Spherelet on the selected host creates the pod and injects the Photon Linux Kernel into the vSphere pod. The Spherelet starts the container. (See Initial Placement of a vSphere Pod for a more detailed diagram of the creation process of a vSphere Pod).

Please note that if the developer specifies a limit that exceeds the host capabilities than the configuration is created, however, the vSphere pod fails to deploy.
Resource Reclamation
In addition to sizing the vSphere pod, vSphere uses the resources requests listed in the pod manifest to apply vSphere resource allocation settings to guarantee the requested resources are available. There can be a gap between the set reservation and the size of the vSphere pod. Similar to VM behavior, these resources are available as long as there is no resource contention. When resource contention occurs, the reclamation of resources is initiated. In the case of a vSphere pod, vSphere broad spectrum of consolidation techniques are used, but when it comes to the eviction of a pod, vSphere lets Kubernetes do the dirty work. In all seriousness, this is due to internal Kubernetes event management and a more granular view of resource usage.
Namespaces
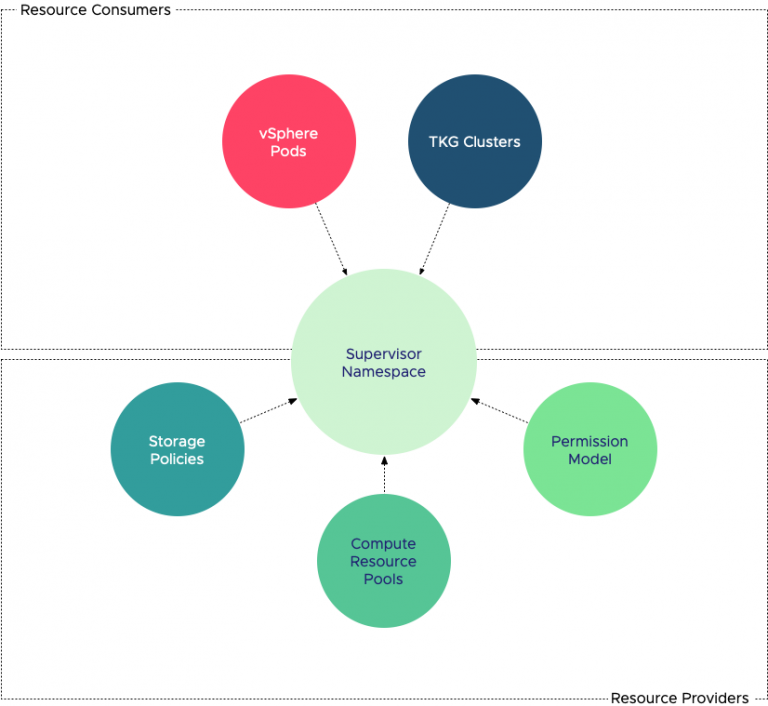
In Kubernetes, a higher-level construct is available to guide and control its member pods, this construct is called the namespace. vSphere 7 with Kubernetes provides a similar construct at the vSphere level, the supervisor namespace. A vSphere resource pool is used to manage the compute resources of the supervisor namespace. The namespace can be configured with an optional limit range that defines a default request or limit on containers, influencing vSphere pod sizes and reclamation behavior. The supervisor namespaces is a vast topic and therefore more info about Namespace will appear in the next article in this series.

Very useful info. Thanks
A lot of insight into VMpod scheduling…Thank you, Frank.