For the last 18 months, I’ve been focusing on machine learning, especially how customers can successfully deploy machine learning infrastructure on a vSphere infrastructure.
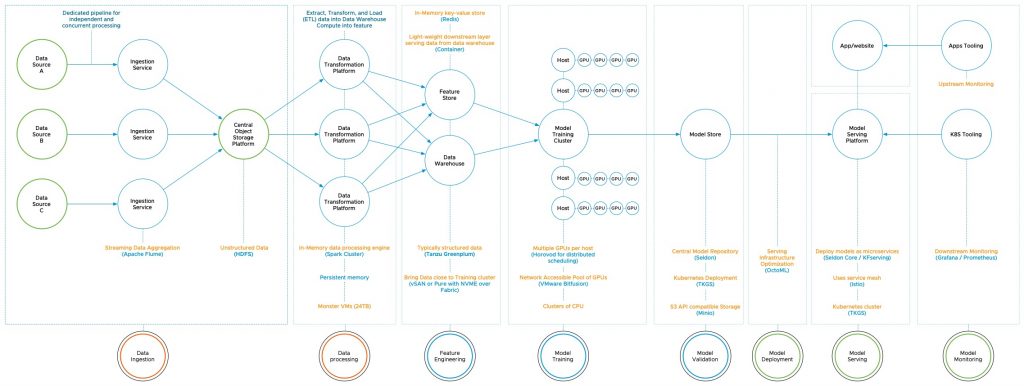
This space is exciting as it has so many great angles to explore. Besides the model training, a lot of stuff happens with the data. Data is transformed, data is moved. Data sets are often hundreds of gigabytes in size. Although that doesn’t sound that much compared to modern databases, these data sets are transformed and versioned. Where massive databases nest on an array, these data sets travel through pipelines that connect multiple systems with different architectures, from data lakes to in-memory key-value stores. As a data center architect, you need to think about the various components involved, where the compute horsepower is needed? How do you deal with an explosion of data? Where do you place particular storage platforms, what kind of bandwidth is needed, and do you always need the extreme low-latency systems in your ML infrastructure landscape?
The different ML model engineering life cycle phases generate different functional and technical requirements, and the persona involved is not data center architectural-minded. Sure they talk about ML infrastructure, but their concept of infrastructure is different from “our” concept of infrastructure. Typically, the lowest level of abstraction a data science team deals with is a container or a VM. Concepts of availability zones, hypervisors, or storage areas are foreign to them. When investigating ML pipelines and other toolsets, technical requirements are usually omitted. This isn’t weird, as containers are more or less system-like processes, and you typically do not specify system resource requirements for system processes. But for an architect or a VI team that wants to shape a platform capable of dealing with ML workload, you need to get a sense of what’s required.
I intend to publish a set of articles that helps to describe where the two worlds of data center infrastructure and ML infrastructure interact, where the rubber meets the road. The series covers the different phases of the ML model engineering lifecycle and what kind of requirements they produce. What is MLOps, and how does this differ from DevOps? Why is data lineage so crucial in today’s world, and how does this impact your infrastructure services? What type of persona is involved with machine learning, their tasks and role in the process, and what type of infrastructure service can benefit them. And how we can map actual data and ML pipeline components to an abstract process diagram full of beautiful terms such as data processing, feature engineering, model validation, and model serving.

I’m sure that I will introduce more topics along the way, but if you have any topic in mind that you want to see covered, please leave a comment!


