I recently received a few questions from customers migrating between clusters with different CPU socket footprints. The challenge is not necessarily migrating live workloads between clusters because we have Enhanced vMotion Compatibility (EVC) to solve this problem.
For VMware users just learning about this technology, EVC masks certain unique features of newer CPU generations and creates a generic baseline of CPU features throughout the cluster. If workloads move between two clusters, vMotion still checks whether the same CPU features are presented to the virtual machine. If you are planning to move workloads, ensure the EVC modes of the clusters are matching to get the smoothest experience.
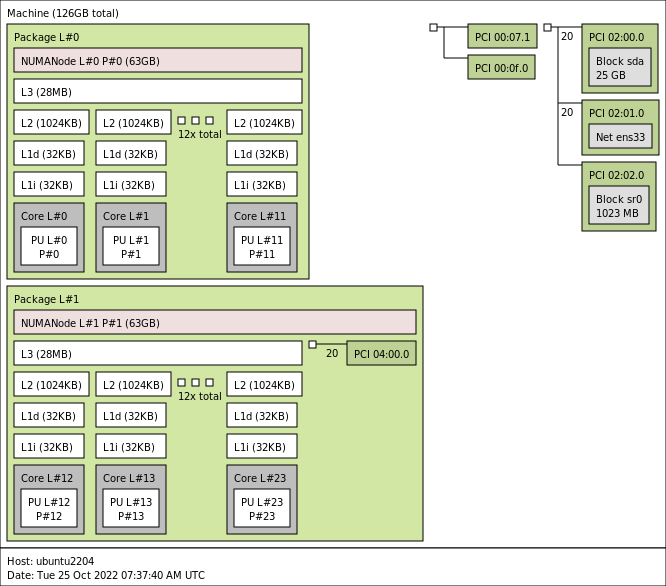
The challenge when moving live workloads between ESXi hosts with different socket configurations is that vNUMA topology of the virtual machine does not match the physical topology. A virtual NUMA topology exists out of two components, the component that presents the CPU topology to the virtual machine, called the VPD. The VPD exists to help the guest OS and the applications optimize their CPU scheduling decisions. This VPD construct is principally the virtual NUMA topology. The other component, the PPD, groups the vCPUs and helps the NUMA scheduler for placement decisions across the physical NUMA nodes.

The fascinating part of this story is that the VPD and PPD are closely linked, yet they can differ if needed. The scheduler attempts to mirror the configuration between the two elements; the PPD configuration is dynamic, but the VPD configuration always remains the same. From the moment the VM is powered on, the VPD configuration does not change. And that is a good thing because operating systems generally do not like to see whole CPU layouts change. Adding a core with CPU hot add is all right. But drastically rearranging caches and socket configurations it’s pretty much a bridge too far.
As mentioned before, the VPD remains the same. Still, the NUMA scheduler can reconfigure the PPD to optimize the vCPU grouping for the CPU scheduler. When will this happen? When you move a VM to a host with a different physical CPU configuration, i.e. Socket Count, or physical cores per socket count. This way, ESXi still squeezes out the best performance it can in this situation. The drawback of this situation is the mismatch between presentation and scheduling.
This functionality is great as it allows workloads to enjoy mobility between different CPU topologies without any downtime. However, we might want to squeeze out all the performance possible. Some vCPUs might not share the same cache, although the application thinks they do. Or, some vCPU might not even be scheduled together in the same physical NUMA node, experiencing latency and bandwidth reduction. To be more precise, this mismatch can impact memory locality and the action-affinity load-balancing operations of the scheduler. Thus, it can impact the VM performance and create more inter CPU traffic. This impact might be minor on a per-VM basis, but you have to think in scale, the combined performance loss of all the VMs, so for larger environments, it might be worthwhile to get it fixed.
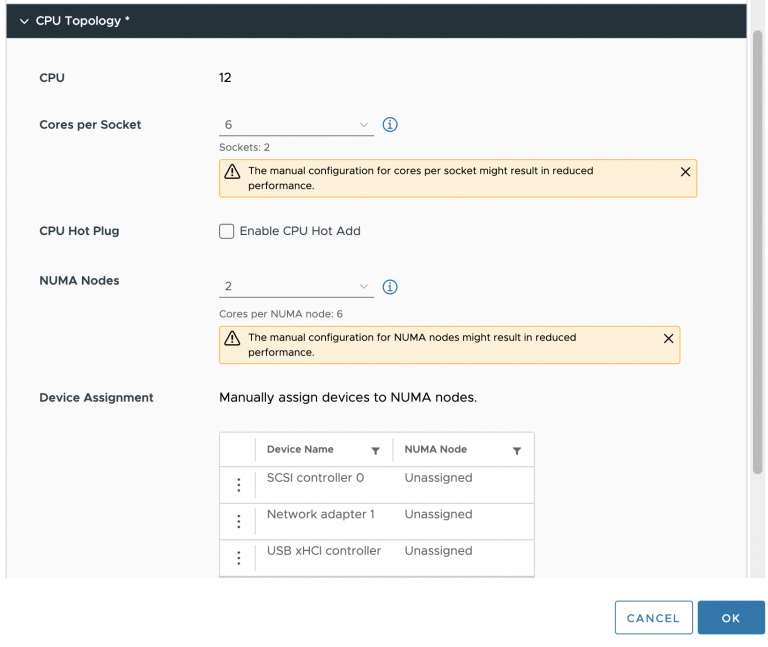
I’ve created a 36 vCPU VM on a dual-socket system with twenty physical CPU cores per socket. The power-on process of the virtual machine creates the vNUMA topology and enters all kinds of entries in the VMX file. Once the VM powers on, the VMX file receives the following entries.
numa.autosize.cookie = "360022"
numa.autosize.vcpu.maxPerVirtualNode = "18"
The key entry for this example is the “numa.autosize.vcpu.maxPerVirtualNode = “18”, as the NUMA scheduler likes to distribute as many vCPUs across many cores as possible and evenly across sockets.

But what happens if this virtual machine moves to a quad-socket system with 14 physical cores per socket? The NUMA scheduler will create three scheduling constructs to distribute those vCPUs across the NUMA nodes but keep the presentation layer the same not to confuse the guest OS and the applications.

Since the NUMA topologies are created during a VM’s power-on, we have to shut down the virtual machine and power it back to realign the VPD and PPD topology again. Well, since 2019, we don’t need to power down the VM anymore! And I have to admit. I only found out about it just recently. Bob Plankers (not this Bob) writes about the vmx.reboot.PowerCycle advanced parameter here. This setting does not require a complete power cycle anymore.
That means that if you are in the process of migrating your VM estate from dual-socket systems to quad-socket systems, you can add the following adjustments in the VMX file while the VM is running. (for example via PowerCLI / New-AdvancedSetting)
vmx.reboot.PowerCycle = true
numa.autosize.once = false
The setting vmx.reboot.PowerCycle will remove itself from the VMX file, but it’s best to remove the numa.autosize.once = false from the VMX file. So you might want to track this. Same as adding the setting, you can remove the setting while the VM is up and running.
When you have applied these settings to the VMX, the next time the VM reboots, the vNUMA topology will be changed. As always, keep in mind that older systems might react more dramatically than newer systems. After all, you are changing the hardware topology of the system. It might upset an older windows system or optimizations of an older application. Some older operating systems do not like this and will need to do reconfiguration themselves or need some help from the IT ops team. In the worst-case scenario, it will treat the customer to a BSOD with that in mind. It’s recommended to work with the customer with old OSes and figure out a test and migration plan.
Special thanks to Gilles Le Ridou for helping me confirm my suspicion and helping me test scenarios on his environment. #vCommunity!