Two weeks ago Pete Flecha (a.k.a. Pedro Arrow) and John Nicholson invited me to their always awesome podcast to talk about resource management. During our conversation, we covered both on-prem and the features of VMware Cloud on AWS that help cater the needs of your workload.

Being a guest on this podcast is an honour and times flies talking to these two guys. Hope you enjoy it as much as I did.
vSphere 6.5 DRS and Memory Balancing in Non-Overcommitted Clusters
DRS is over a decade old and is still going strong. DRS is aligned with the premise of virtualization, resource sharing and overcommitment of resources. DRS goal is to provide compute resources to the active workload to improve workload consolidation on a minimal compute footprint. However, virtualization surpassed the original principle of workload consolidation to provide unprecedented workload mobility and availability.
With this change of focus, many customers do not overcommit on memory. A lot of customers design their clusters to contain (just) enough memory capacity to ensure all running virtual machines have their memory backed by physical memory. In this scenario, DRS behavior should be adjusted as it traditionally focusses on active memory use.
vSphere 6.5 provides this option in the DRS cluster settings. By ticking the box “Memory Metric for Load Balancing” DRS uses the VM consumed memory for load-balancing operations.
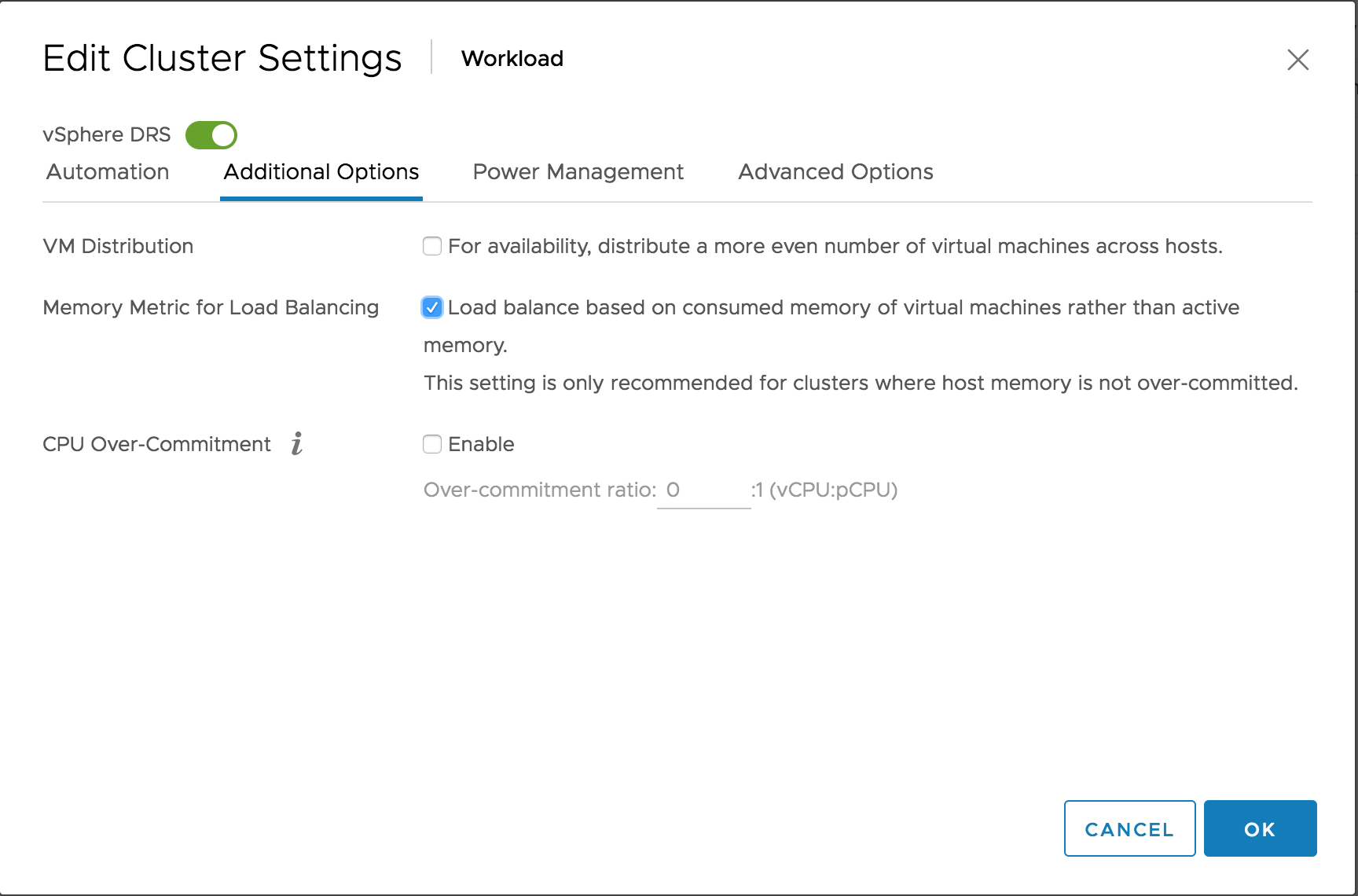
Please note that DRS is focussed on consumed memory, not configured memory! DRS always keeps a close eye on what is happening rather than accepting static configuration. Let’s take a closer look at DRS input metrics of active and consumed memory.
Out-of-the-box DRS Behavior
During load balancing operation, DRS calculates the active memory demand of the virtual machines in the cluster. The active memory represents the working set of the virtual machine, which signifies the number of active pages in RAM. By using the working-set estimation, the memory scheduler determines which of the allocated memory pages are actively used by the virtual machine and which allocated pages are idle. To accommodate a sudden rapid increase of the working set, 25% of idle consumed memory is allowed. Memory demand also includes the virtual machine’s memory overhead.
Let’s use a 16 GB virtual machine as an example of how DRS calculates the memory demand. The guest OS running in this virtual machine has touched 75% of its memory size since it was booted, but only 35% of its memory size is active. This means that the virtual machine has consumed 12288 MB and 5734 MB of this is used as active memory.

As mentioned, DRS accommodate a percentage of the idle consumed memory to be ready for a sudden increase in memory use. To calculate the idle consumed memory, the active memory 5734 MB is subtracted from the consumed memory, 12288 MB, resulting in a total 6554 MB idle consumed memory. By default, DRS includes 25% of the idle consumed memory, i.e. 6554 * 25% = +/- 1639 MB.

The virtual machine has a memory overhead of 90 MB. The memory demand DRS uses in its load balancing calculation is as follows: 5734 MB + 1639 MB + 90 MB = 7463 MB. As a result, DRS selects a host that has 7463 MB available for this machine if it needs to move this virtual machine to improve the load balance of the cluster.
Memory Metric for Load Balancing Enabled
When enabling the option “Memory Metric for Load Balancing” DRS takes into account the consumed memory + the memory overhead for load balancing operations. In essence, DRS uses the metric Active + 100% IdleConsumedMemory.

vSphere 6.5 update 1d UI client allows you to get better visibility in the memory usage of the virtual machines in the cluster. The memory utilization view can be toggled between active memory and consumed memory.
Recently, Adam Eckerle on Twitter published a great article that outlines all the improves of vSphere 6.5 Update 1d. Go check it out. Animated Gif courtesy of Adam.
When reviewing the cluster it shows that the cluster is pretty much balanced.
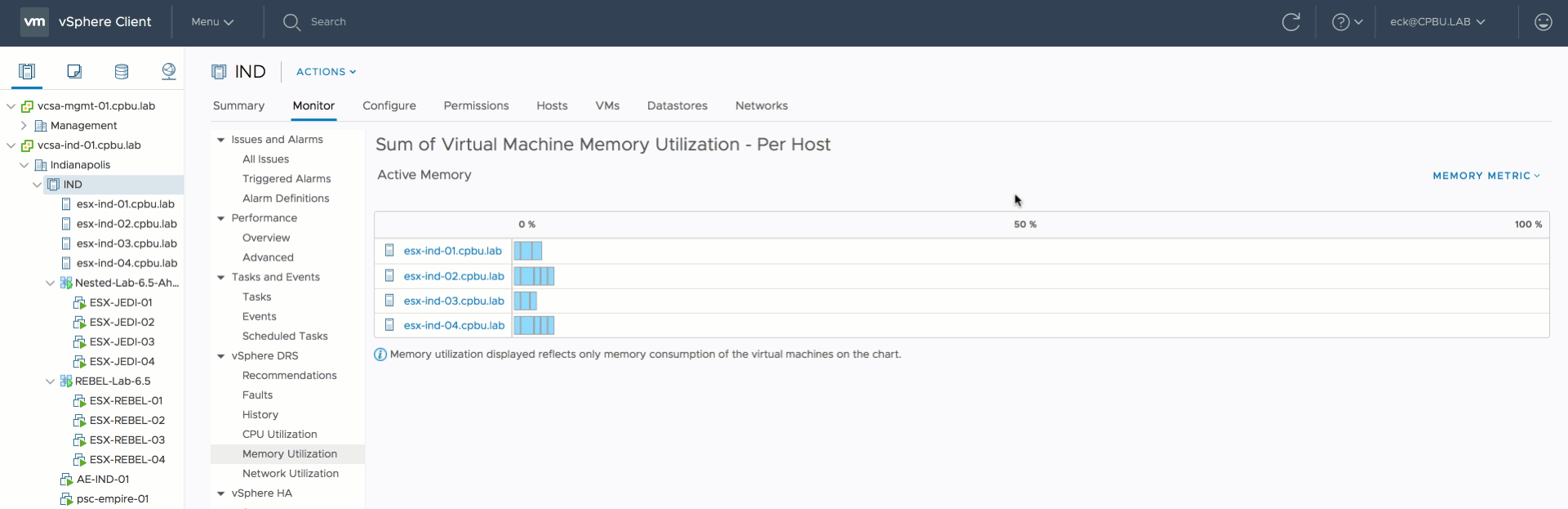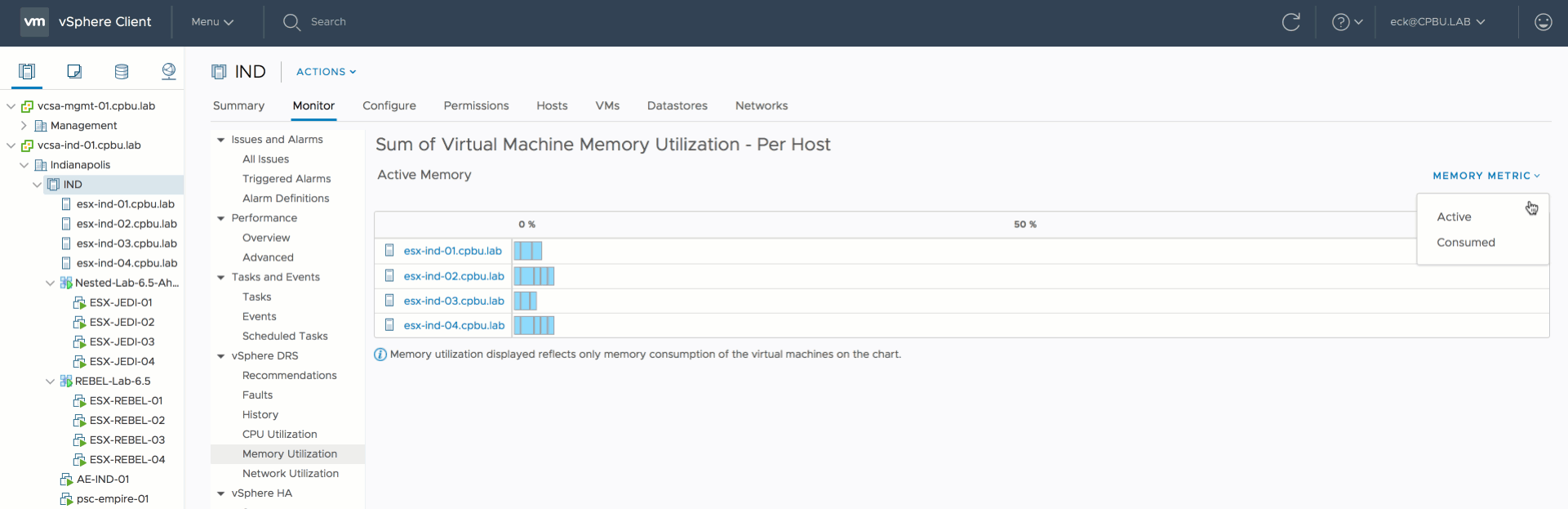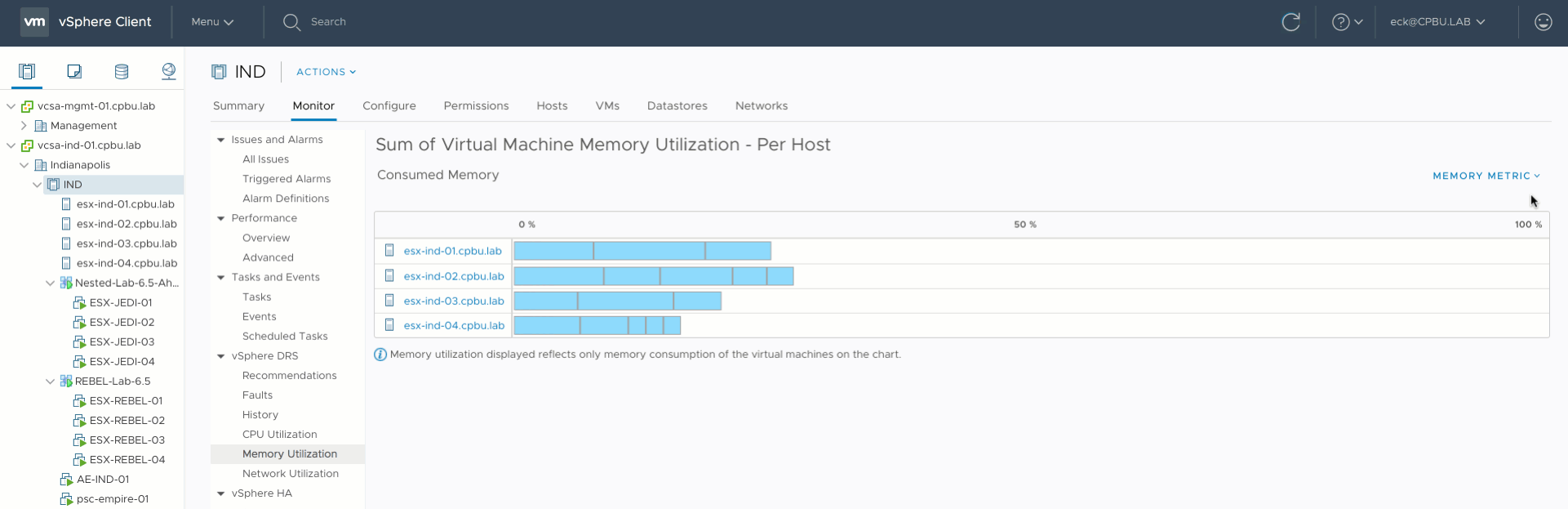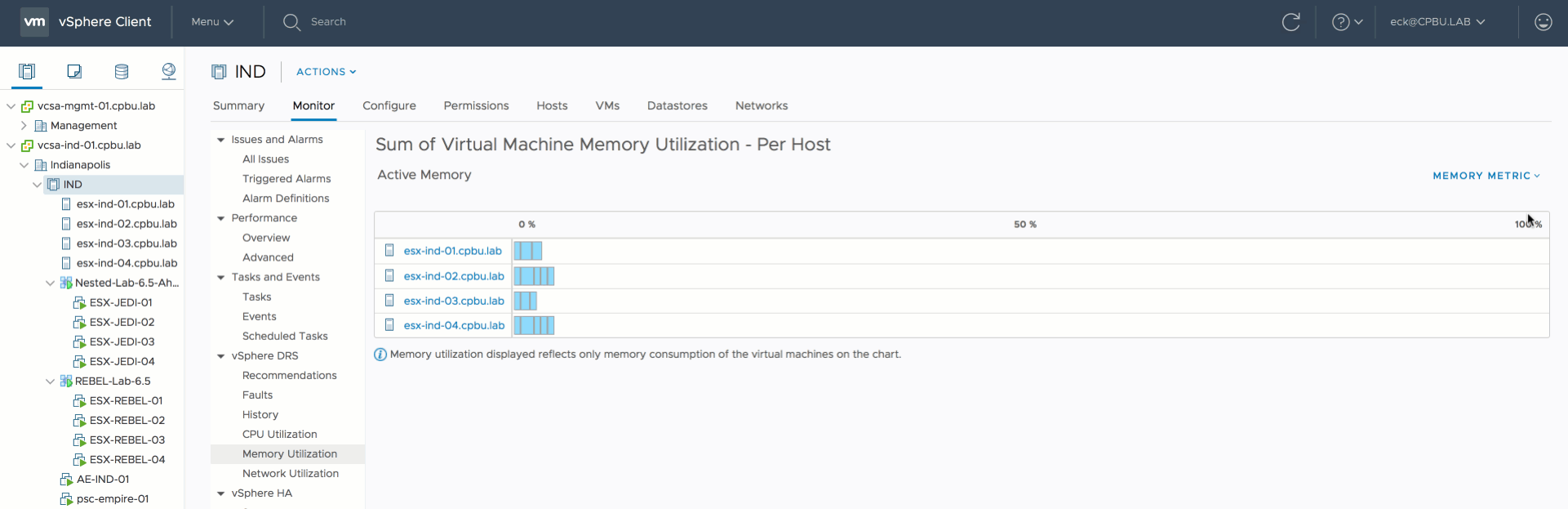
When looking at the default view of the sum of Virtual Machine memory utilization (active memory). It shows that ESXi host ESXi02 is busier than the others.

However since the active memory of each host is less than 20% and each virtual machine is receiving the memory they are entitled to, DRS will not move virtual machines around. Remember, DRS is designed to create as little overhead as possible. Moving one virtual machine to another host to make the active usage more balanced, is just a waste of compute cycles and network bandwidth. The virtual machines receive what they want to receive now, so why take the risk of moving VMs?
But a different view of the current situation is when you toggle the graph to use consumed memory.

Now we see a bigger difference in consumed memory utilization. Much more than 20% between ESXi02 and the other two hosts. By default DRS in vSphere 6.5 tries to clear a utilization difference of 20% between hosts. This is called Pair-Wise Balancing. However, since DRS is focused on Active memory usage, Pair-Wise Balancing won’t be activated with regards to the 20% difference in consumed memory utilization. After enabling the option “Memory Metric for Load Balancing” DRS rebalances the cluster with the optimal number of migrations (as few as possible) to reduce overhead and risk.

Active versus Consumed Memory Bias
If you design your cluster with no memory overcommitment as guiding principle, I recommend to test out the vSphere 6.5 DRS option “Memory Metric for Load Balancing”. You might want to switch DRS to manual mode, to verify the recommendations first.
Explainer on #Spectre & #Meltdown by Graham Sutherland
Sometimes you stumble across a brilliant Twitter thread, so good, that it should never be lost. Graham Sutherland (@gsuberland) helped the world in understanding the Spectre and Meltdown bugs. I’m publishing his tweet thread in text form as this is just the best explanation of the bugs I’ve seen.
Please note that VMware has released its response for Bounds-Check Bypass (CVE-2017-5753), Branch Target Injection (CVE-2017-5715) & Rogue Data Cache Load (CVE-2017-5754) – AKA Meltdown & Spectre.
https://blogs.vmware.com/security/2018/01/vmsa-2018-0002.html
Disclaimer: All text below is produced by Graham Sutherland, I’m not taking any credits for this work
Explainer on #Spectre & #Meltdown:
When a processor reaches a conditional branch in code (e.g. an 'if' clause), it tries to predict which branch will be taken before it actually knows the result. It executes that branch ahead of time – a feature called "speculative execution".
— Graham Sutherland (Polynomial^DSS) ➡️ chaos.social (@gsuberland) January 4, 2018
Explainer on #Spectre & #Meltdown:
When a processor reaches a conditional branch in code (e.g. an ‘if’ clause), it tries to predict which branch will be taken before it actually knows the result. It executes that branch ahead of time – a feature called “speculative execution”.
The idea is that if it gets the prediction right (which modern processors are quite good at) it’ll already have executed the next bit of code by the time the actually-selected branch is known. If it gets it wrong, execution unwinds back and the correct branch is executed instead.
What makes the processor so good at branch prediction is that it stores details about previous branch operations, in what’s called the Branch History Buffer (BHB). If a particular branch instruction took path A before, it’ll probably take path A again, rather than path B.
What makes this interesting is that code is executed *speculatively*, before the result of a conditional statement has completed. That conditional statement could be security-critical. Thankfully the processor is (mostly) smart enough to roll back any side-effects of execution.
There are two important exclusions to the rollback of side-effects: cache and branch prediction history. These generally aren’t rolled back because speculative execution is a performance feature, and rolling back cache and BHB contents would generally hurt performance.
There are three ways to exploit this behaviour. The Spectre paper describes the first two exploits, with the following results:
1. Kernel memory disclosure from userspace on bare metal.
2. Kernel memory disclosure of the VM host/hypervisor from kernelspace in a VM.
The first exploit works by getting the kernel to execute some carefully written attacker-specified code which contains an array bounds check followed by an array read, where the read index is controlled by an attacker. This sounds like a big ask, but it’s not thanks to JIT.
On Linux, Extended Berkley Packet Filter (eBPF) allows users to write socket filters from usermode which get JIT compiled by the kernel in order to efficiently filter packets on a socket. The details aren’t important, but it means an attacker can get the kernel to execute code.
The exploit involves writing eBPF code which compiles to the following steps:
1. Allocate two fixed-size arrays
2. Bounds-check the user-provided index
3. If ok, read from the array1 at that index
4. Compute another index from 1 bit of the result
5. Read from array2 at that index
There’s actually a step before 5, which is “bounds check the read to array2”, but we never intend to do an out-of-bounds read here, so it’s irrelevant. I omitted it because I ran out of characters.
In terms of “real” execution, this code always terminates at step 2 when the user passes an out-of-bounds index for array1. But if the processor’s branch predictor assumes that check will succeed, it’ll speculatively execute the out-of-bounds read in step 3, and continue to 5.
Here’s the clever bit. In step 4 we take the value we got from the out-of-bounds read (which we wouldn’t normally have access to) and use one bit from it to select a particular memory address (array index) to read. If b=0 it reads index 0x200; if b=1 it reads index 0x300.
This ensures that the memory at either index 0x200 or index 0x300 is now cached. The CPU then realises that the bounds check in step 2 failed, so it unwinds back to that branch. However, the data from step 5 is still cached!
We can then go in and read the data at 0x200 and 0x300 and see which is cached by measuring how quick the read is. Once we know which index was cached we can directly infer one bit of kernel memory, based on the index selection from step 4.
There are some details as to how the cache needs to be primed before this attack, but it is possible to do this whole process in a loop and dump kernel memory from unprivileged userspace.
The second attack described in the Spectre paper involves poisoning the branch prediction history to trick the processor into speculatively executing code at an attacker-specified address, leading to further cache attacks as described above.
By performing a carefully selected sequence of indirect jumps, an attacker can fill up the branch prediction history in a way that allows the attacker to select which branch will be speculatively executed when performing an indirect jump.
This can be very powerful. If I know there’s a piece of code in kernel space that exhibits similar behaviour to our eBPF example from before, and I know what the address of that code is, I can indirectly jump to that code and the CPU will speculatively execute it.
If you’ve done exploitation before, you’ll probably recognise this as being similar to a ROP gadget. We’re looking for a sequence of code in kernel space that happens to have the right sequence of instructions to leak information via cache.
Keep in mind that the execution is speculative only – the processor will later realise that I didn’t have the privilege to jump to that code and throw an exception. So the target code has to leak kernel data via cache side-channels like before.
You’ll also notice that we need to know address of the target kernel code. With KASLR this isn’t so easy. Project Zero’s writeup explains how KASLR can be defeated using branch prediction and caching as side-channels, so I won’t go into the details here.
https://googleprojectzero.blogspot.co.uk/2018/01/reading-privileged-memory-with-side.html
What makes this extra powerful is that it works across VM boundaries too. Instead of a traditional indirect jump (e.g. jmp eax), we can use the vmcall instruction to speculatively execute code within the VM host’s kernel in the same way we would our VM’s kernel.
Finally, there’s the third approach. This involves a flush+reload cache attack against kernel memory, similar to the first variant of the attack but without requiring kernel code execution – it can all be done from usermode.
The idea is that we try to read kernelspace memory using a mov instruction, then perform a secondary memory read with an address based on the value that was read. If you’re thinking the first mov will fail because we’re in usermode and can’t read kernel addresses, you’re right.
The trick is that the microarchitectural implementation of mov contains the memory page privilege level check, which itself is a branch instruction. The processor may speculatively execute that branch like any other.
So, if you can outrun the interrupt, you can speculatively execute some other instruction that loads data into cache based on the value read from kernelspace. This then becomes a cache attack like the previous tricks.
And that’s just about it.
For full details I recommend checking out the two papers, as well as the Project Zero writeup I linked above.
https://spectreattack.com/spectre.pdf
https://meltdownattack.com/meltdown.pdf
Thanks Graham for this excellent explanation!
Free vSphere 6.5 Host Resources Deep Dive E-Book
In June of this year, Niels and I published the vSphere 6.5 Host Resources Deep Dive, and the community was buzzing. Twitter exploded, and many community members provided rave reviews.
This excitement caught Rubriks attention, and they decided to support the community by giving away 2000 free copies of the printed version at VMworld. The interest was overwhelming, before the end of the second signing session in Barcelona we ran out of books.

A lot of people reached out to Rubrik and us to find out if they could get a free book as well. This gave us an idea, and we sat down with Rubrik and the VMUG organization to determine how to cater the community.
We are proud to announce that you can download the e-book version (PDF only) for free at rubrik.com. Just sign up and download your full e-book copy here.
Spread the word! And if you like, thank @Rubrik and @myVMUG for their efforts to help the VMware community advance.
What if the VM Memory Config Exceeds the Memory Capacity of the Physical NUMA Node?
This week I had the pleasure to talk to a customer about NUMA use-cases and a very interesting config came up. They have a VM with a particular memory configuration that exceeds the ESXi host NUMA node memory configuration. This scenario is covered in the vSphere 6.5 Host Resources Deep Dive, excerpt below.
Memory Configuration
The scenario described happens in multi-socket systems that are used to host monster-VMs. Extreme memory footprint VMs are getting more common by the day. The system is equipped with two CPU packages. Each CPU package contains twelve cores. The system has a memory configuration of 128 GB in total. The NUMA nodes are symmetrically configured and contain 64 GB of memory each.

However, if the VM requires 96 GB of memory, a maximum of 64 GB can be obtained from a single NUMA node. This means that 32 GB of memory could become remote if the vCPUs of that VM can fit inside one NUMA node. In this case, the VM is configured with 8 vCPUs.

The VM fits from a vCPU perspective inside one NUMA node, and therefore the NUMA scheduler configures for this VM a single virtual proximity domain (VPD) and a single a load-balancing group which is internally referred to as a physical proximity domain (PPD).
Example Workload
Running a SQL DB on this machine resulted in the following local and remote memory consumption. The VM consumes nearly 64 GB on its local NUMA node (clientID shows the location of the vCPUs) while it consumes 31 GB of remote memory.

In this scenario, it could be beneficial to the performance of the VM to rely on the NUMA optimizations that exist in the guest OS and application. The VM advanced setting numa.consolidate = FALSE instructs the NUMA scheduler to distribute the VM configuration across as many NUMA nodes as possible.

In this scenario, the NUMA scheduler creates 2 load-balancing domains (PPDs) and allows for a more symmetrical configuration of 4 vCPUs per node.
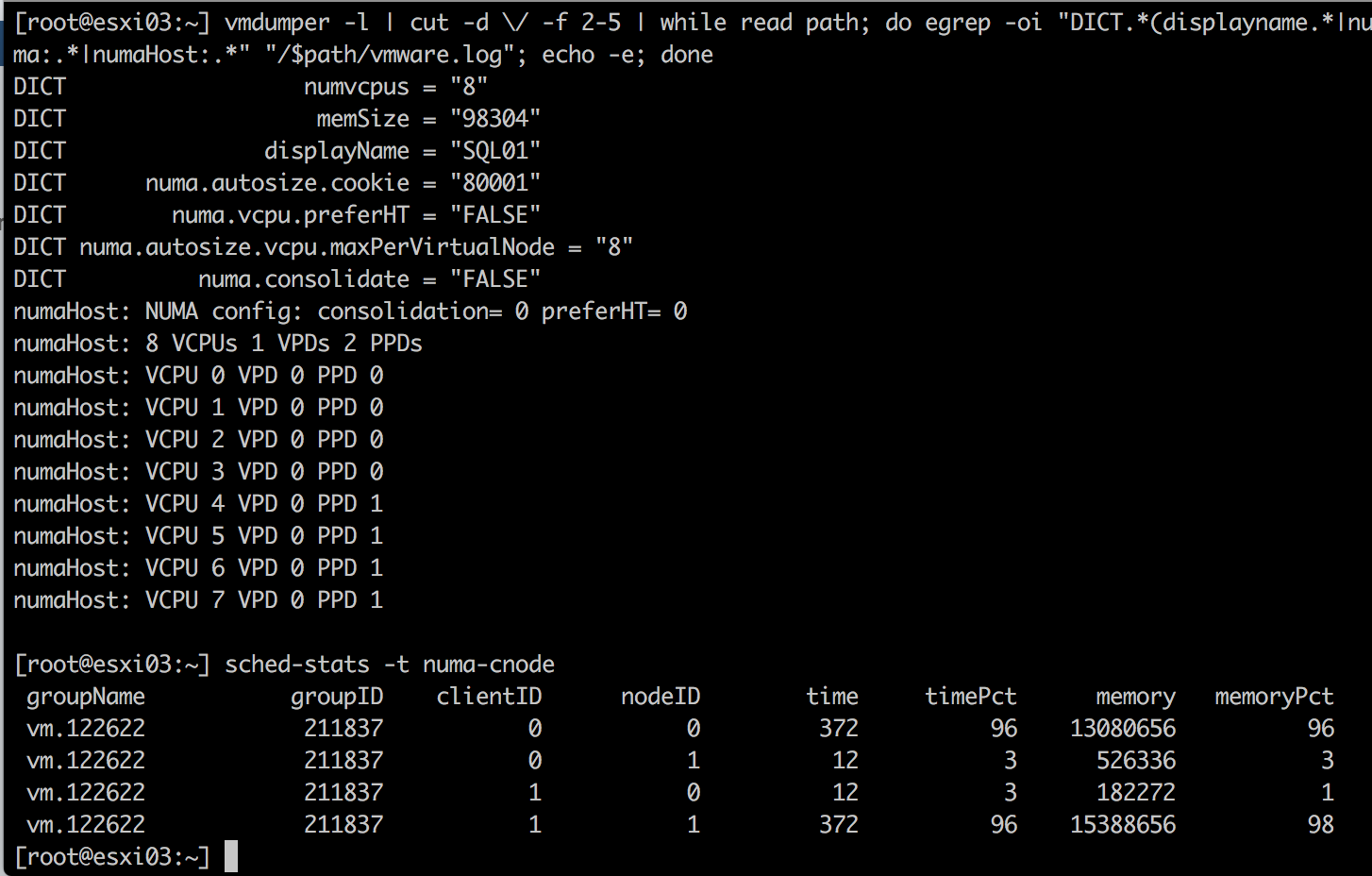
Please note that a single VPD (VPD0) is created and as a result, the guest OS and the application only detect a single NUMA node. Local and remote memory optimizations are (only) applied by the NUMA scheduler in the hypervisor.
Whether or not the application can benefit from this configuration depends on its design. If it’s a multi-threaded application, the NUMA scheduler can allocate memory closes to the CPU operation. However, if the VM is running a single-threaded application, you still might end up with a lot of remote memory access, as the physical NUMA node hosting the vCPU is unable to provide the memory demand by itself.
Test the behavior of your application before making the change to create a baseline. As always, use advanced settings only if necessary!