VMware

Simulating NUMA Nodes for Nested ESXi Virtual Appliances
To troubleshoot a particular NUMA client behavior in a heterogenous multi-cloud environment, I needed to set up an ESXi7.0 environment. Currently,...DRS Migration Threshold in vSphere 7
DRS in vSphere 7 is equipped with a new algorithm. The old algorithm measured the load of each host in the...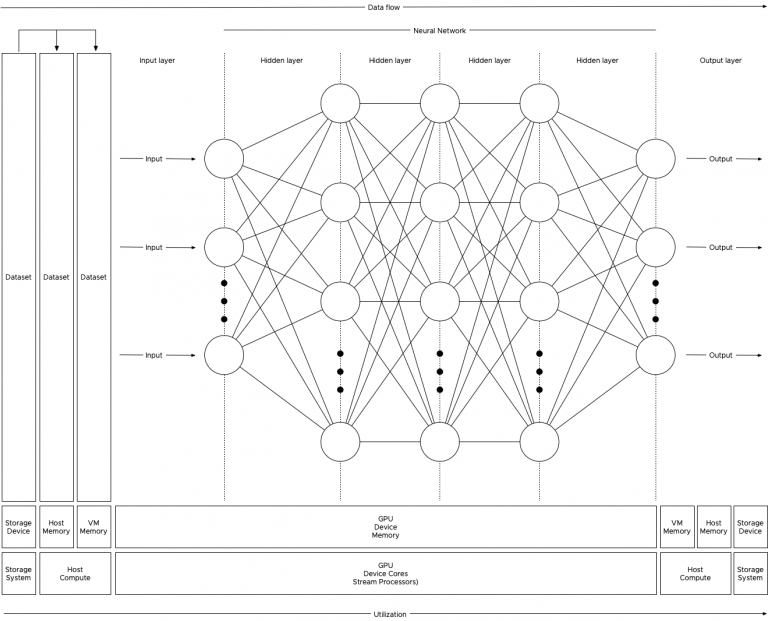
Machine Learning Workload and GPGPU NUMA Node Locality
In the previous article “PCIe Device NUMA Node Locality” I covered the physical connection between the processor and the PCIe device...