Welcome to part 3 of the Virtual Datacenter scaling problems with traditional shared storage series. Last week I published an article about the FAST presentation “A Practical Implementation of Clustered Fault Tolerant Write Acceleration in a Virtualized Environment”. Ian Forbes followed up with the question about the advantages of throughput and latency of host-to-host network versus a traditional SAN when both have similar network speeds.
Part 1: Intro
Part 2: Storage Area Network topology
IOPS distribution amongst ESXi hosts
In the previous part of this series the IOPS provided by the array were equally divided amongst the ESXi hosts. In reality given the nature of applications and their variance it’s the application demand that drives the I/O demand. And due to this I/O demand will not be equally balanced across all the host in the cluster.
The virtual datacenter is comprised of different resource layers each with components that introduce their own set of load balancing algorithms. Back in 2009 Chad published nice diagram depicting all the queues and buffers of a typical storage environment. Go read the excellent article “VMware I/O queues, micro bursting and multipathing”.
How can you ensure that the available paths to the array are load-balanced based on virtual machine demand and importance? Unfortunately for us today’s virtual datacenter lacks load balance functionality that clusters these different layers, reducing hotspots and optimally distributes workloads. Let’s focus on the existing algorithms currently available, and possibly present, in virtual datacenters around the world.
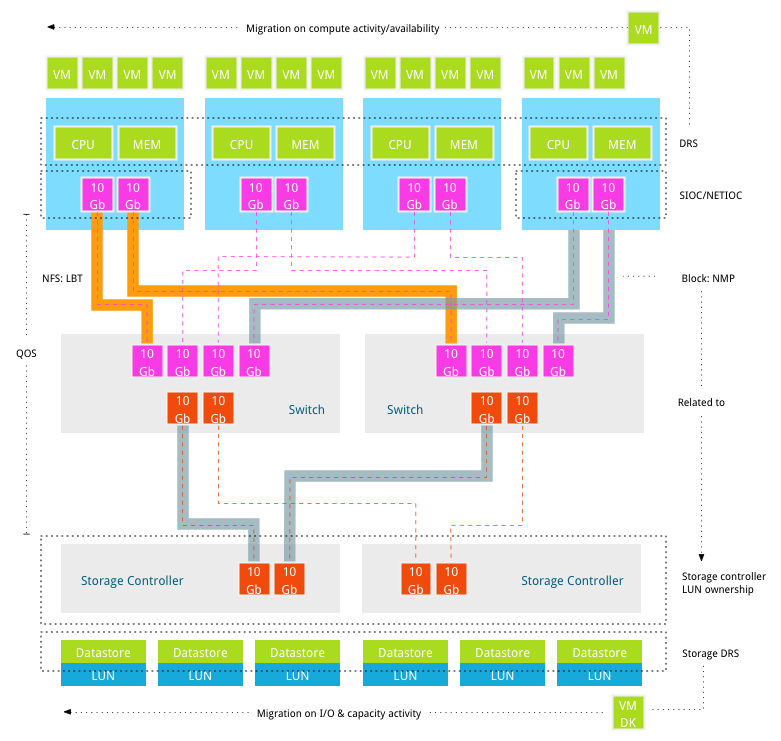
Clustered load balancers
The only cluster-wide load balancing tools are DRS and Storage DRS. Both cluster resources into seamless pools and distribute workload according to their demand and their priority. When the current host cannot provide the entitled resources a virtual machine demands, the virtual machine is migrated to another host or datastore. DRS aggregates CPU and memory resources, Storage DRS tries to mix and match the VM I/O & capacity demand with the datastore I/O and capacity availability.
The layers between compute and datastores are equally important yet network bandwidth and data paths are not managed as a clustered resource. Load balancing occurs within the boundaries of the host; specifically they focus on outgoing data streams.
Data Path load balancing
With IP-based storage networks, multiple options exist to balance the workload across the outgoing ports. With iSCSI, binding of multiple VMkernel NICs can be used to distribute workload, some storage vendors prefer a configuration using multiple VLANS to load balance across storage ports. When using NFS Load Based Teaming (LBT) can be used to load balance data across multiple NICs.
Unfortunately all these solutions don’t take the path behind the first switch port in consideration. Although the existing workload is distributed across the available uplinks as efficiently as possible, no solution exists that pools the connected paths of the hosts in the cluster and distribute the workloads across the hosts accordingly. A solution that distributes virtual machines across host with less congested data paths in a well-informed and automatic manner simply does not exist.
Distributed I/O control
Storage I/O Control (SIOC) is a datastore-wide scheduler, allowing distributing of queue priority amongst the virtual machines located on various hosts that are connected to that datastore. SIOC is designed to deal with situations where contention occurs. If necessary it divides the available queue slots across the hosts to satisfy the I/O requirements based on the virtual machine priority. SIOC measures the latency from the (datastore) device inside the kernel to disk inside the array. It is not designed to migrate virtual machines to other hosts into the cluster to reduce latency or bandwidth limitations incurred by the data path. Network IO Control (NetIOC) is based on similar framework. It allocates and distributes bandwidth across the virtual machines that are using the NICs of that particular host. It has no ability to migrate virtual machines by taking lower utilized links of other hosts in the cluster into account.
Multipathing software
VMware Pluggable Storage Architecture (PSA) is interesting. The PSA allows third party vendors to provide their own native multipathing software (NMP). Within the PSA, Path Selection Plugins (PSPs) are active that are responsible for choosing a physical path for I/O requests. The VMware Native Multipathing Plugin framework supports three types of PSPs; Most Recently Used (MRU), Fixed and Round Robin. The Storage Array Type Plugins (SATP) run in conjunction with NMP and manages array specific operations. SATPs are aware of storage array specifics, such as whether it’s an active/active array or active/passive array. For example, when the array uses ALUA (Asymmetric LUN Unit Access) it determines which paths lead to the ports of the managing controllers.
The Round Robin PSP distributes I/O for a datastore down all active paths to the managing controller and uses a single path for a given number of I/O operations. Although it distributes workload across all (optimized) paths, it does not guarantee that throughput will be constant. There is no optimization on the I/O profile of the host. Its load balance algorithm is based purely on equal numbers of I/O down a given path, without regard to what the block size of I/O type is, it will not be balanced on application workload characteristics or the current bandwidth utilization of the particular path. Similar to SIOC and NetIOC, NMP is not designed to treat data paths as clustered resource and has no ability to distribute workloads across all available uplinks in the cluster.
EMC PowerPath is a third party NMP and has multiple algorithms that consider current bandwidth consumption of the paths and the pending types of I/O. It also integrates certain storage controller statistics to avoid negative affects by continuously switching paths. PowerPath squeezes as much performance (and resilience) out of their storage paths as possible because it can probe the link from host all the way to the back-end of a supported array and make decisions about active links accordingly. However PowerPath hosts do not communicate with each other and balances the I/O load on a host-by-host basis. This paragraph focuses on EMC solution; other storage vendors are releasing their NMP software with similar functionality. However not all vendors are providing their own software, and EMC PowerPath is only supported on a short list of storage vendors other than EMC own products.
Quality of Services on data paths
Quality of Services on data paths (QoS) is an interesting solution if it provides end-to-end QoS; from virtual machine to datastore. The hypervisor is context-rich environment, allowing kernel services to understand which I/O belongs to which virtual machine. However when the I/O exits the host and hits the network, the remaining identification is the address of the transmitting device of the host. There is no differentiation of priority possible other then at host level. Not all applications are equally important to the business, therefor end-to-end QoS is necessary to guarantee that business critical application get the resources they deserve. Scalability limitation on storage controller ports influences the overall impact of QoS. Similar to most algorithms, it does not aim to provide a balanced utilization of all available data paths; it deals with priority control during resource contention.
Storage Array layer
Storage DRS is able to migrate virtual machine files based on their resource demand. Storage DRS monitors the VMobserved latency, this includes the kernel and data path latency. Storage DRS incorporates the latency to calculate the benefit a migration has on the overall change in latency at source and destination datastore. It does not use the different latencies of kernel and data path to initiate a migration at compute level. Storage DRS initiates a self-vMotion to load the new VMX file as it has a different location after the storage vMotion, the virtual machine remains on the same hosts. In other words Storage DRS is not designed to migrate virtual machine at the compute layer or datastore layer to solve bandwidth imbalance.
Most popular arrays provide asymmetric LUN unit access. All ports on the Storage controllers accept incoming read and write operations, however the controller owning the LUN always manages read operations. Distributing LUNs across controllers are crucial as imbalance of CPU utilization or port utilization of the storage controllers can be easily introduced. LUNs can be manually transferred to improve CPU utilization, however this is not done dynamically unfortunately. Manual detection and management is as good as people watching it and not many organizations watch the environment at that scrutiny level all the time. Some might argue that arrays transfer the LUNs automatically, but that’s when a certain amount of “proxy reads” are detected. This means that the I/O’s are transmitted across the non-optimized paths, and likely either the PSP is not doing a great job, or all your active optimized paths are dead. Both not hallmarks of an healthy – or –properly architected environment.
Is oversizing a solution?
Oversizing bandwidth can help you so far, as its difficult to predict workload increase and intensity variation. Introduction of radically new application landscape impact current designs tremendously. When looking at the industry developments, its almost certain that most datacenters will be forced to absorb these new application landscapes, can current solutions applied in a traditional storage stack provide and guarantee the services they require and are they able to scale to provide the resources necessary?
Non-holistic load balancer available
In essence, the data-path between the compute layer and datastore layer is not treated as a clustered resource. Virtual machine host placement is based on compute resource availability and entitlement, disregarding the data path towards storage layer. This can potentially lead to hotspots inside the cluster, where some hosts saturate their data paths, while data paths of other hosts are underutilized. Data path saturation impacts application performance.
Unfortunately there is no mechanism available today that takes the various resource demands of a virtual machine into account. No solution at this time has the ability to intelligently manage these resources without creating other bottlenecks or impracticalities.
This article is not a stab at the current solutions. It is a very difficult problem to solve, especially for an industry that relies on various components of various vendors, expecting everything to integrate and perform optimally aligning. And think about moving forward and attempt to incorporate new technology advancements from all different vendors when they are available. And don’t forget about backward compatibility, world peace might be easier to solve.
With this problem in mind, the existence of uncontrollable data paths, oversubscribed inter-switch links and its inability to be application aware, many solutions nowadays move away from the traditional storage architecture paradigm. Deterministic performance delivery and Policy-driven management are the future and when no centralized control plane is available that stitching these disparate components together a different architecture arises. PernixData FVP, VMware VSAN and Hyper-converged systems rely on point-to-point network architectures of the crossbar switch architecture to provide consistent and non-blocking network performance to cater their storage performance and storage service resiliency needs.
Leveraging point-to-point connections and being able to leverage the context-aware hypervisor allows you not only to scale easily, it allows you to create environments that provide consistent and deterministic performance levels. The future datacenter is one step closer!
Part 4 focusses on the storage controller architecture and why leveraging host-to-host communication and host resource availability remove scalability issues.
Part 3 – Data path is not managed as a clustered resource
6 min read
Hi Frank.
Another great article.
However I would like to confirm one fact you wrote … “Most popular arrays provide asymmetric LUN unit access. All ports on the Storage controllers accept incoming read and write operations, however the controller owning the LUN always manages read operations.”
Are you sure ALUA works like that? I’m sure you wrote similar article in the past about ALUA TPGs and I think that I/O is flowing only to storage controller ports in the same TPG therefore to the controller owning the LUN.
ALUA controller owning the LUN always manages all I/O operations. If I/O is delivered over active/non-optimized path to controller not owning the LUN the I/O has to be redirected to owning controller and therefore it is asymmetric (non-optimized).
Do I miss something or just misunderstood something?
I believe the previous poster is correct as regards ALUA. Hitachi moved somewhat away from traditional ALUA with their “virtual distribution” front end and full access to all storage by both controllers in HUS some years ago, I believe. However, at the end of the day you still have a limited number of ports on the storage system configured in a static manner.
That is what IMHO makes EMC DSSD potentially quite interesting. With ongoing industry NVMe developments and size and price directions for NAND this could be a winner if EMC doesn’t botch it. I am sure they will charge and arm and a leg for it, but if you need what it might do once it sees the light of day then you will have to pay. For the rest of us keeping write acks to a single non-oversubscribed switch port hop to the next door neighbor host’s RAM or NAND should continue to meet our cost/performance needs for some time to come. As long as the back end array can keep up with the ultimate de-stage of the blocks before local cache is exhausted you should be golden.