The two last parts reviewed the capabilities of the platform. vSphere can offer fractional GPUs to Multi-GPU setups, catering to the workload’s needs in every stage of its development life cycle. Let’s look at the features and functionality of each supported GPU device. Currently, the range of supported GPU devices is quite broad. In total, 29 GPU devices are supported, dating back from 2016 to the last release in 2023. A table at the end of the article includes links to each GPUs product brief and their datasheet. Although NVIDIA and VMware form a close partnership, the listed support of devices is not a complete match. This can lead to some interesting questions typically answered with; it should work. But as always, if you want bulletproof support, follow the guides to ensure more leisure time on weekends and nights.
VMware HCL and NVAIE Support
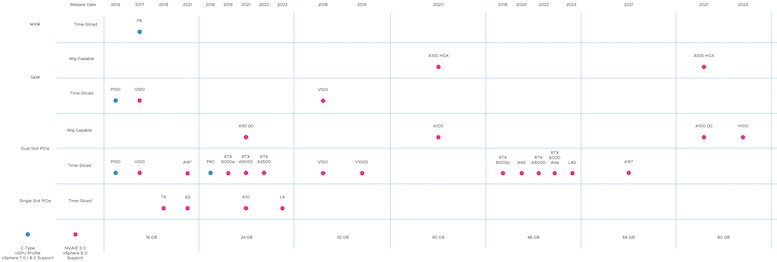
The first overview shows the GPU device spectrum and if NVAIE supports them. The VMware HCL supports every device listed in this overview, but NVIDIA decided not to put some of the older devices through their NVAIE certification program. As this is a series about Machine Learning, the diagram shows the support of the device and a C-series vGPU type. The VMware compatibility guide has an AI/ML column, listed as Compute, for a specific certification program that tests these capabilities. If the driver offers a C-series type, the device can run GPU-assisted applications; therefore, I’m listing some older GPU devices that customers still use. With some other devices, VMware hasn’t tested the compute capabilities, but NVIDIA has, and therefore there might be some discrepancies between the VMware HCL and NVAIE supportability matrix. For the newer models, the supportability matrix is aligned. Review the table and follow the GPU device HCL page link to view the supported NVIDIA driver version for your vSphere release.
The Y axis shows the device Interface type and possible slot consumption. This allows for easy analysis of whether a device is the “right fit” for edge locations. Due to space constraints, single-slot PCIe cards allow for denser or smaller configurations. Although every NVIDIA device supported by NVAIE can provide time-shared fractional GPUs, not all provide spatial MIG functionality. A subdivision is made on the Y-axis to show that distinction. The X-axis represents the GPU memory available per device. It allows for easier selection if you know the workload’s technical requirements.
The Ampere A16 is the only device that is listed twice in these overviews. The A16 device uses a dual-slot PCIe interface to offer four distinct GPUs on a single PCB card. The card contains 64GB GPU memory, but vSphere shall report four devices offering 16G of GPU memory. I thought this was the best solution to avoid confusion or remarks that the A16 was omitted, as some architects like to calculate the overall available GPU memory capacity per PCIe slot.

NVLink Support
If you plan to create a platform that supports distributed training using multi-GPU technology, this overview shows the available and supported NVLinks bandwidth capabilities. Not all GPU devices include NVLink support, and the ones with support can wildly differ. The MIG capability is omitted as MIG technology does not support NVLink.

NVIDIA Encoder Support
The GPU decodes the video file before running it through an ML model. But it depends on the process following the outcome of the model prediction, whether to encode the video again and replay it to a display. With some models, the action required after, for example, an anomaly detection, is to generate a warning event. But if a human needs to look at the video for verification, a hardware encoder must be available on the GPU. The Q-series vGPU type is required to utilize the encoders. What may surprise most readers is that most high-end datacenter does not have encoders. This can affect the GPU selection process if you want to create isolated media streams at the edge using MIG technology. Other GPU devices might be a better choice or investigate the performance impact of CPU encoding.

NVIDIA Decoder Support
Every GPU has at least one decoder, but many have more. With MIG, you can assign and isolate decoders to a specific workload. When a GPU is time-sliced, the active workload utilizes all GPU decoders available. Please note that the A16 list has eight decoders, but each distinct GPU on the A16 exposes two decoders to the workload.

GPUDirect RDMA Support
GPUDirect RDMA is supported on all time-sliced and MIG-backed C-series vGPUs on GPU devices that support single root I/O virtualization (SR-IOV). Please note that Linux is the only supported Guest OS for GPUDirect technology. Unfortunately, MS Windows isn’t supported.

Power Consumption
When deploying at an edge location, power consumption can be a constraint. This table list the specified power consumption of each GPU device.

Supported GPUs Overview
The table contains all the GPUs depicted in the diagrams above. Instead of repeating non-descriptive labels like webpage or PDFs, the table shows the GPU release date while linking to its product brief. The label for the datasheet indicates the amount of GPU memory, allowing for easy GPU selection if you want to compare specific GPU devices. Please note that VMware has not conducted C-series vGPU type tests on the device if the HCL Column indicates No. However, the NVIDIA driver does support the C-series vGPU type.
| Architecture | GPU Device | HCL/ML Support | NVAIE 3.0 Support | Product Brief | Datasheet |
| Pascal | Tesla P100 | No | No | October 2016 | 16GB |
| Pascal | Tesla P6 | No | No | March 2017 | 16GB |
| Volta | Tesla V100 | No | Yes | September 2017 | 16GB |
| Turing | T4 | No | Yes | October 2018 | 16GB |
| Ampere | A2 | Yes | No | November 2021 | 16GB |
| Pascal | P40 | No | Yes | November 2016 | 24GB |
| Turing | RTX 6000 passive | No | Yes | December 2019 | 24GB |
| Ampere | RTX A5000 | No | Yes | April 2021 | 24GB |
| Ampere | RTX A5500 | N/A | Yes | March 2022 | 24GB |
| Ampere | A30 | Yes | Yes | March 2021 | 24GB |
| Ampere | A30X | Yes | Yes | March 2021 | 24GB |
| Ampere | A 10 | Yes | Yes | March 2021 | 24GB |
| Ada Lovelace | L4 | Yes | Yes | March 2023 | 24GB |
| Volta | Tesla V100(S) | No | Yes | March 2018 | 32GB |
| Ampere | A100 (HGX) | N/A | Yes | September 2020 | 40GB |
| Turing | RTX 8000 passive | No | Yes | December 2019 | 48GB |
| Ampere | A40 | Yes | Yes | May 2020 | 48GB |
| Ampere | RTX A6000 | No | Yes | December 2022 | 48GB |
| Ada Lovelace | RTX 6000 Ada | N/A | Yes | December 2022 | 48GB |
| Ada Lovelace | L40 | Yes | Yes | October 2020 | 48GB |
| Ampere | A 16 | Yes | Yes | June 2021 | 64GB |
| Ampere | A100 | Yes | Yes | June 2021 | 80GB |
| Ampere | A100X | Yes | Yes | June 2021 | 80GB |
| Ampere | A100 HGX | N/A | Yes | November 2020 | 80GB |
| Ada Lovelace | H100 | Yes | Yes | September 2022 | 80GB |
Other articles in the vSphere ML Accelerator Spectrum Deep Dive
- vSphere ML Accelerator Spectrum Deep Dive Series
- vSphere ML Accelerator Spectrum Deep Dive – Fractional and Full GPUs
- vSphere ML Accelerator Spectrum Deep Dive – Multi-GPU for Distributed Training
- vSphere ML Accelerator Spectrum Deep Dive – GPU Device Differentiators
- vSphere ML Accelerator Spectrum Deep Dive – NVIDIA AI Enterprise Suite
- vSphere ML Accelerator Spectrum Deep Dive – ESXi Host BIOS, VM, and vCenter Settings
- vSphere ML Accelerator Spectrum Deep Dive – Using Dynamic DirectPath IO (Passthrough) with VMs
- vSphere ML Accelerator Spectrum Deep Dive – NVAIE Cloud License Service Setup



2 Replies to “vSphere ML Accelerator Spectrum Deep Dive – GPU Device…”
Comments are closed.