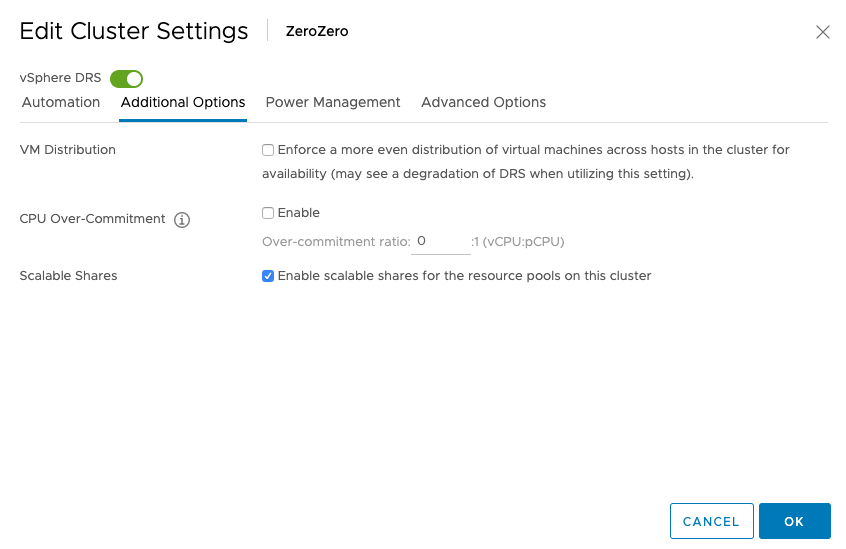
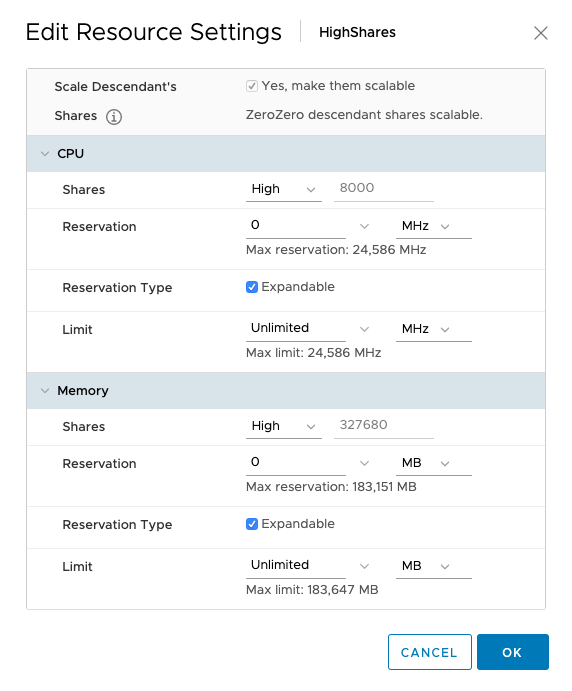
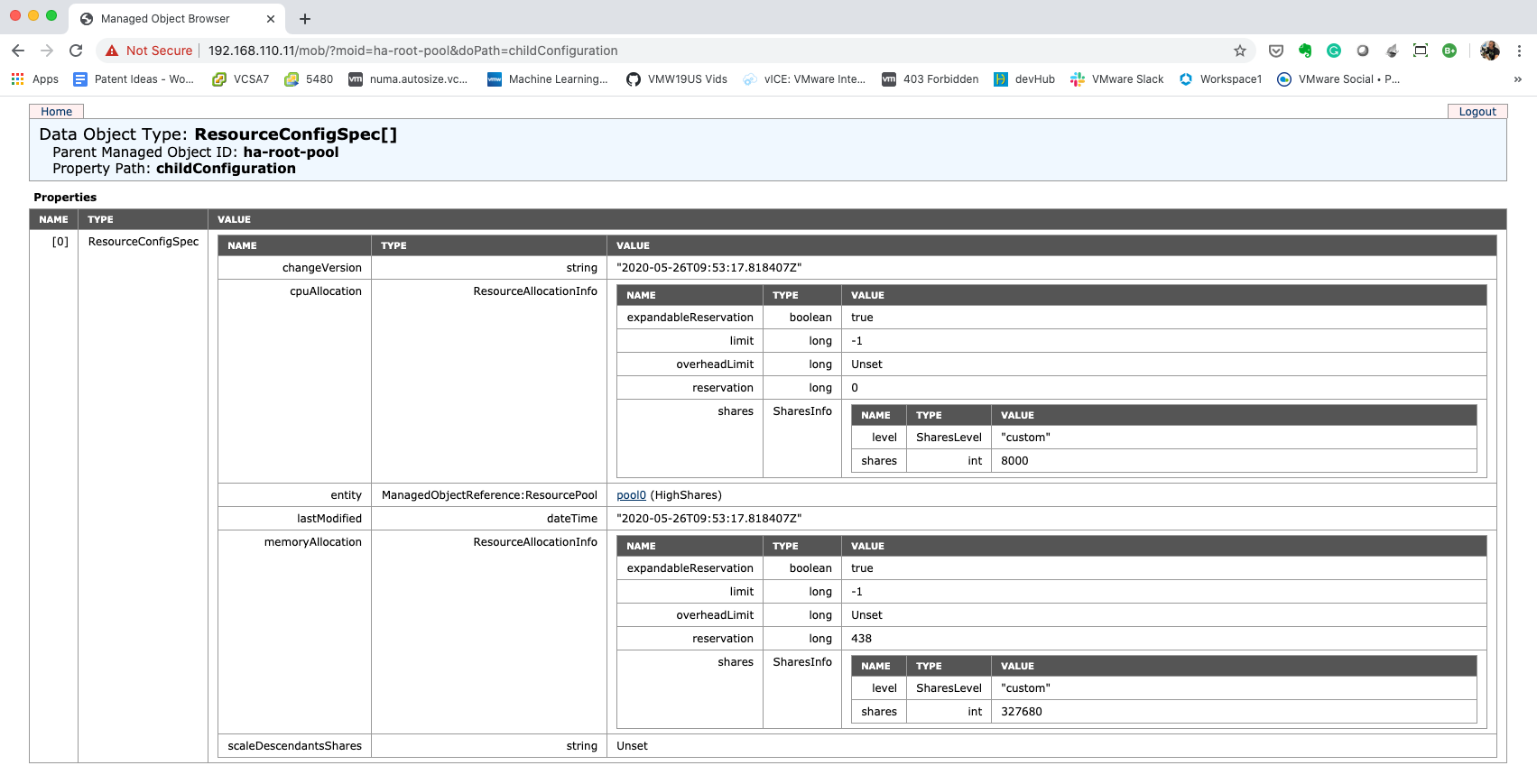
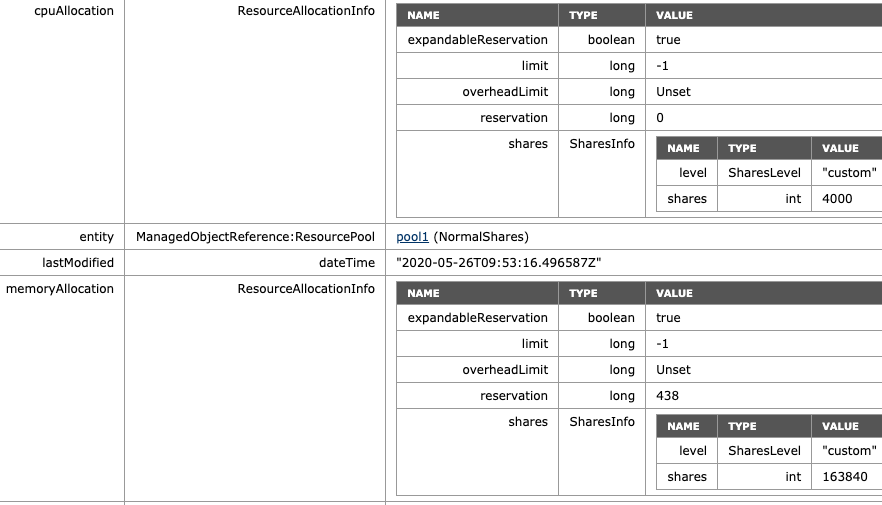
vSphere 7.0 introduces DRS 2.0 and its new load balancing algorithm. In essence, the new DRS is completely focused on taking care of the needs of the VMs and does this at a more aggressive pace than the old DRS. As a result, DRS will resort to vMotioning a virtual machine faster than the previous DRS. And this is something that a lot of customers are noticing. In highly consolidated clusters, you might see a lot of vMotions occur. I perceive this as an infrastructural service. However, some customers might see this as a turbulent or nervous environment and rather see fewer vMotions. As a result, these customers like to dial down the DRS threshold, which is the right thing to do. But please be aware, if you still want DRS to have load-balancing functionality, do not slide the threshold all the way to the left.
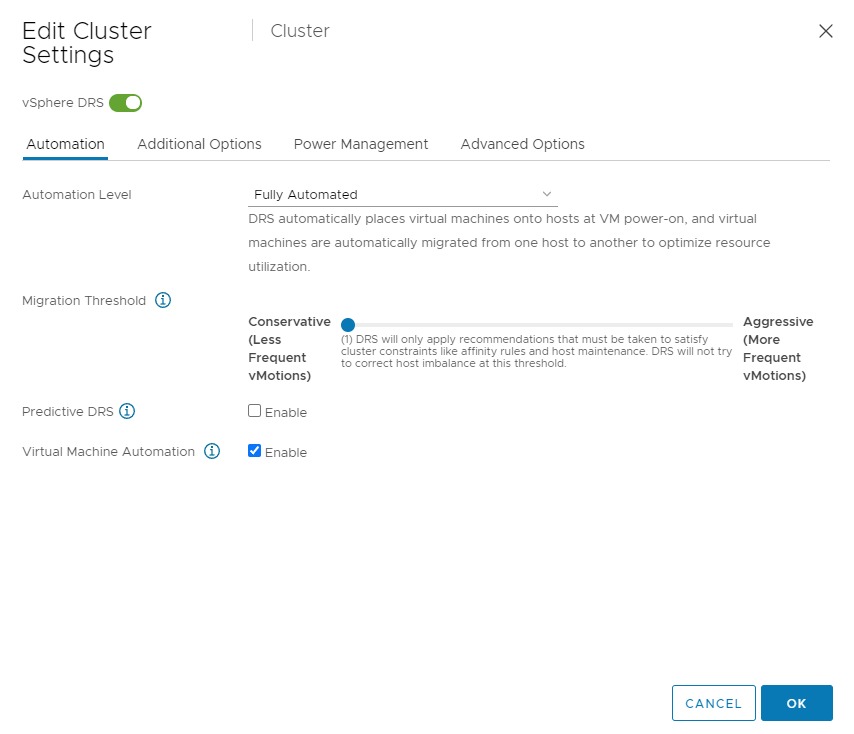
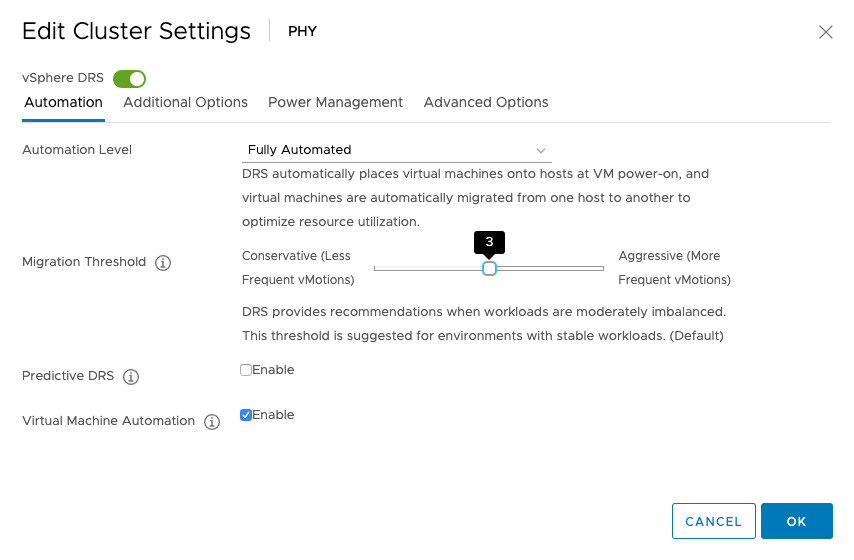
Using the setting “Conservative (1)”, DRS only triggers migrations for solving cluster constraints and violations. Meaning that if you put an ESXi host into maintenance mode, DRS moves the VMs out of that host. Or if due to a maintenance mode migration, or HA event, an anti-affinity rule is violated, DRS moves that particular VM to solve that problem. But that’s it. No moves to solve any VM happiness or host imbalance. If you want to reduce the number of vMotions and still like DRS to get the best resources for the virtual machines, do not set DRS to the utmost left setting but set it to setting 2.