During a troubleshooting exercise of a problem with vCenter I needed to disable DRS to make sure DRS was not the culprit. However a resource pool tree exisited in the infrastructure and I was not looking forward reconfiguring all the resource allocation settings again and documenting which VM belonged to which resource pool. The web client of vSphere 5.1 has a cool feature that helps in these cases. When deactivating DRS (Select cluster, Manage, Settings, Edit, deselect “Turn ON vSphere DRS”) the user interface displays the following question:
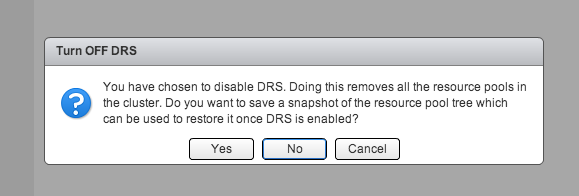
Backup resource pool tree
Click “Yes” to backup the tree and select an appropriate destination for the resource pool tree snapshot file. This file uses the name structure clustername.snapshot and should the file size be not bigger than 1 or 2 KB.
Restore resource pool tree
When enabling DRS on the cluster, the User interface does not ask the question to restore the tree. In order to restore the tree, enable DRS first and select the cluster in the tree view. Open the submenu by performing a right-click on the cluster, expand the “All vCenter Actions” and select the option “Restore Resource Pool Tree…”
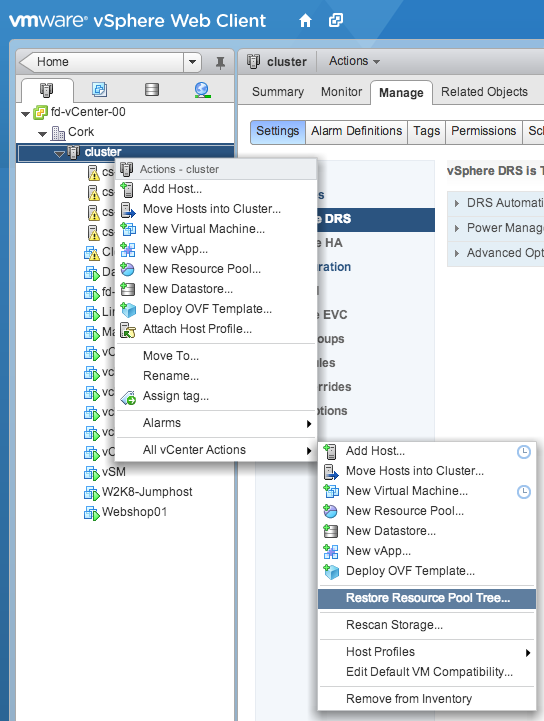
A window appears and click browse in order to select the saved resource pool tree snapshot and click on OK
vCenter restores the tree, the resource pool settings (shares, reservations limits) and moves the virtual machines back to the resource pool they were placed in before disabling DRS.
If you want to save the complete vCenter inventory configuration I suggest you download the fling “InventorySnapshot”.
Update: If you want to use this tool to backup and restore resource pool trees used by vCloud Director, please read this article: Saving a Resource Pool Structure web client feature not suitable for vCD environments
There is a new fling in town: DRMdiagnose
This week the DRMdiagnose fling is published. Produced by the resource management team and just in case you are wondering, DRM stands for Distributed Resource Manager; the internal code for DRS. Download DRMdiagnose at the VMware fling site. Please note that this fling only works on vSphere 5.1 environments
Purpose of DRMdiagnose
This tool is created to understand the impact on the virtual machines own performance and the impact on other virtual machines in the cluster if the resource allocation settings of a virtual machine are changed. DRMdiagnose compares the current resource demand of the virtual machine and suggest changes to the resource allocation settings to achieve the appropriate performance. This tool can assist you to meet service level agreements by providing feedback on desired resource entitlement. Although you might know what performance you want for a virtual machine, you might not be aware of the impact or consequences an adjustments might have on other parts of the resource environment or cluster policies. DRMdiagnose provides recommendations that provides the meets the resource allocation requirement of the virtual machines with the least amount of impact. A DRMdiagnose recommendation could look like this:
Increase CPU size of VM Webserver by 1
Increase CPU shares of VM Webserver by 4000
Increase memory size of VM Database01 by 800 MB
Increase memory shares of VM Database01 by 2000
Decrease CPU reservation of RP Silver by 340 MHz
Decrease CPU reservation of VM AD01 by 214 MHz
Increase CPU reservation of VM Database01 by 1000 MHz
How does it work
DRMdiagnose reviews the DRS cluster snapshot. This snapshot contains the current cluster state and the resource demand of the virtual machines. The cluster snapshot is stored on the vCenter server. These snapshot files can be found:
- vCenter server appliance: /var/log/vmware/vpx/drmdump/clusterX/
- vCenter server Windows 2003: %ALLUSERSPROFILE%\Application Data\VMware\VMware VirtualCenter\Logs\drmdump\clusterX\
- vCenter server Windows 2008: %ALLUSERSPROFILE%\VMware\VMware VirtualCenter\Logs\drmdump\clusterX\
The fling can be run in three modes:
- Default: Given a link to a drmdump, it lists all the VMs in the cluster, and their current demands and entitlements.
- Guided: Given a link to a drmdump, and a target allocation for the VM, generates a set of recommendations to achieve it.
- Auto: Given a link to a drmdump, generates a recommendation to satisfy the demand of the most distressed VM (the VM for which the gap between demand and entitlement is the highest).
Two things to note:
One: The fling does not have run on the vCenter server itself. Just install the fling on your local windows or linux system, copy over the latest drmdump file and run the fling. And second the drmdump file is zipped (GZ), unzip the file first to and run DRMdiagnose against the .dump file. A “normal” dumpfile should look like this:
How to run:
Open a command prompt in windows:

This command will provide the default output and provide you a list with CPU and Memory demand as well as entitlement. Instead of showing it on screen I chose to port it to a file as the output contains a lot of data.
A next article will expand on auto-mode and guided-mode use of DRMdiagnose. In the mean time, I would suggest to download DRMdiagnose and review your current environment.
Distribution of resources based on shares in a Resource pool environment
Unfortunately Resource pools seem to have a bad rep, pair them with the word shares and we might as well call death and destruction to our virtual infrastructure while we’re at it. Now in reality shares and resource pools are an excellent way of maintaining a free flow of resource distribution to the virtual machine who require these resources. Some articles, and the examples I use in the book are meant to illustrate the worst-case scenario, but unfortunately those examples are perceived to be the default method of operation. Let me use an example:
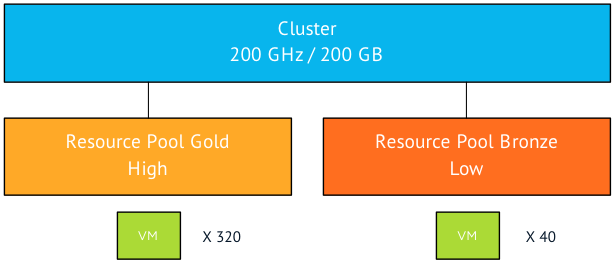
In a cluster two resource pool exist, resource pool gold is used for production and is configured with a high share level. Resource pool bronze is used for development and test and is configured with a low share level. Meaning that the ratio of shares is 4:1. Now this environment contains a 8:1 ratio when it comes to virtual machines. The gold resource pool contains 320 virtual machines and the bronze resource pool contains 40 virtual machines. The cluster contains 200 GB of memory and 200 GHz of CPU, this means that the each virtual machine in the gold resource pool has access to 0.5 MHz and 0.5 GB right? Well yes BUT…. (take a deep breath because this will be one long sentence)… Only in the scenario where all the virtual machines in the environment are 100% utilized (CPU and memory), where the ESXi hosts can provide enough network bandwidth and storage bandwidth to back the activity of the virtual machines, no other operations are active in the environment and where all virtual machines are configured identically in size and operating system than yes that happens. In all other scenarios a more dynamic distribution of resources is happening.
The distribution process
Now let’s deconstruct the distribution process. First of all let’s refresh some basic resource management behavior and determine the distinction between shares and reservations. A share is a relative weight, identifying the priority of the virtual machine during contention. It is only relative to its peers and only relative to other active shares. This means that using the previous scenario, the resource pool shares compete against each other and the virtual machine shares inside a single resource pool compete against each other. It’s important to note that only active shares are used when determining distribution. This is to prevent resource hoarding based on shares, if you do not exercise you shares, you lose the rights to compete in the bidding of resources.
Reservations are the complete opposite, the resource is protected by a reservation the moment you used it. Basically the virtual machine “owns” that resources and cannot be pressured to relinquish it. Therefor reservations can be seen as the complete opposite of shares, a basic mechanism to hoard resources.
Back to the scenario, what happens in most environments?
First of all the demand is driven from bottom to top, that means that virtual machines ask their parent if they can have the resources they demand. The resource pool will ask the cluster for resources.
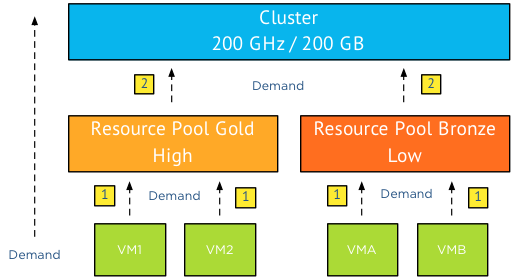
The distribution is going in the opposite direction; top to bottom and that’s where activity and shares come in to play. If both resource pools are asking for more resources than the cluster can supply, then the cluster needs to decide which resource pool gets the resources. As resource pool (RP) Gold contains a lot more virtual machines its safe to assume that RP Gold is demanding more resources than RP Bronze. The total demand of the virtual machines in RP Gold is 180 GB while the virtual machines in RP Bronze demand a total of 25GB. In total the two RP’s demand 205GB while the cluster can only provide 200GB. Notice that I split up demand request into two levels, VMs to RP, RP to cluster.
The cluster will take multiple passes to distribute the resources. In the first pass the resources are distributed according to the relative share value, in this case 4:1 that means that RP Gold is entitled to 160GB of memory (4/5 of 200) and RP Bronze 40GB (1/5 of 200).
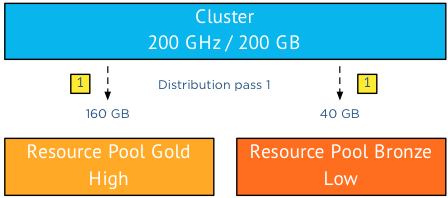
While RP Bronze gets awarded 40GB, it is only requesting 25GB, returning the excessive 15GB of memory to the cluster. (Remember if you don’t use it, you lose it)
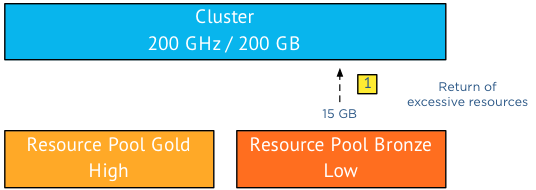
As the cluster has a “spare” 15GB to distribute it executes a second distribution pass and since there are no other resource consumers in the cluster it awards these 15GB of memory resources to the claim of RP Gold.
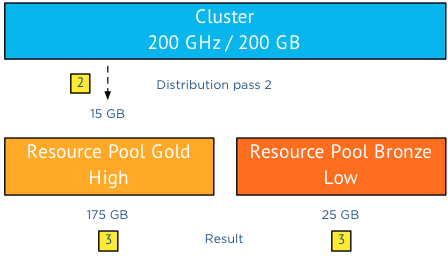
This leads to a distribution of 175GB to Resource Pool Gold and 25GB of memory of Resource Pool Bronze. Please note that in this scenario I broke down the sequence into multiple passes, in reality these multiple passes are contained within a (extremely fast) single operation. The moment resource demand changes, a new distribution of resources will occur. Allowing the cluster resources to satisfy the demand in the most dynamic way.
The same sequence is happening in the resource pool itself; virtual machines receive their resources based on their activity and their share value. Hereby distributing the resources “owned” by the resource pool to the most important and active virtual machines within the pool
If no custom share values are configured on the virtual machine itself, the virtual machine CPU and memory configuration along with the configured share level will determine the amount of shares the virtual machine posses. For example a virtual machine configured with a normal share value and a configuration of 2vCPU and 2GB will posses 2000 shares of CPU and 20480 shares of memory. For more info about share calculation please consult the VMware vSphere 5.1 resource management guide, table 2-1 page 12. (share values have not been changed since the introduction, therefor it’s applicable to ESX and all vSphere versions)
Key takeaway
I hope that by using this scenario it’s clear that shares do not hoard resources. The most important thing to understand that it all comes down to activity. Supply is to meet its demand, whenever demand changes new distribution of resources are executed. And although the number of the virtual machines might not be comparable to the share ratio of the resource pools, it’s the activity that drives the dynamic distribution.
Mixing multiple resource allocation settings
In theory an unequal distribution of resources is possible, in reality the presences of more virtual machines equal more demand. Now architecting an environment can be done in many ways, a popular method is to design for worst-case scenario. Great designs usually do not rely on a single element and therefor a configuration with the use of multiple resource allocation settings (reservations, shares and limits) might provide the level of performance throughout the cluster.
If you are using a cluster design as described in the scenario and you want to ensure that load and smoke testing do not interfere with the performance levels of the virtual machines in RP Gold, than a mix of resource pool reservations and shares might be a solution. Determine the amount of resources that need to be permanently available to your production environment and configure a reservation on RP Gold. Hereby creating a pool of guaranteed resources and a pool for burstability. Allowing the remaining resources to be allocated by both resource pools on a dynamic and opportunistic basis. You can even further restrict the use of physical resources to the RP bronze by setting a limit on the resource pool.
Longing for SDDC? Start with resource pools!
Its too bad resource pools got a bad rep and maybe I have been a part of it by only describing worst-case scenarios. When understanding resource pool one recongnizes that resource pools are a crucial element in the Software Defined Datacenter. By using the correct mix of resource allocation settings you can provide an abstraction layer that is able to isolate resources for specific workloads or customers. Resources can be flexibly added, removed, or reorganized in resource pools as per changing business needs and priorities. All this is available to you without the need for tinkering with low-level settings on virtual machines or using power-cli scripts to adjust the shares on resource pools.
Do you use vApps?
We’re interested in learning more about how you use vApps for workload provisioning today and how you envision it evolving in the future.
If you have a couple of spare minutes, please fill out these 15 questions: http://www.surveymethods.com/EndUser.aspx?FFDBB7AEFDB5AAAAFB
Thanks!
Implicit anti-affinity rules and DRS placement behavior
Yesterday I had an interesting conversation with a colleague about affinity rules and if DRS reviews the complete state of the cluster and affinity rules when placing a virtual machine. The following scenario was used to illustrate to question:
The following affinity rules are defined:
1. VM1 and VM2 must stay on the same host
2. VM3 and VM4 must stay on the same host
3. VM1 and VM3 must NOT stay on the same host
If VM1 and VM3 is deployed first, everything will be fine. Because VM1 and
VM3 will be placed on 2 different hosts, and VM2 and VM 4 will also be
placed accordingly
However, if VM1 is deployed first, and then VM4, there isn’t an explicit
rule to say these two need to be on separate hosts, this is implied by
looking into dependencies of the 3 rules created above. Would DRS be
intelligent enough to recognize this? Or will it place VM1 and VM4 on the
same host, but by the time VM3 needs to be placed, there is a clear
deadlock.
The situation where its not logical to place VM4 and VM1 on the same host can be deemed as a implicit anti-affinity rule. It’s not a real rule, but if all virtual machines are operational, VM4 should not be on the same host as VM1. DRS doesn’t react to these implicit rules. Here’s why:
When provisioning a virtual machine, DRS sorts the available hosts on utilization first. Then it goes through a series of checks such as the compatibility between the virtual machine and the host. Does the host have a connection to the datastore? Is the vNetwork available at the host? And then it will check to see if placing the virtual machine violates any constraints. A constraint could be a VM-VM affinity/anti-affinity rule or a VM-Host affinity/anti-affinity rule.
In the scenario where VM1 is running, DRS is safe to place VM4 on the same host as it does not violate any affinity rule. When DRS wants to place VM3, it determines that placing VM3 on the same host VM4 is running violates the anti-affinity rule VM1 and VM3. Therefor it will migrate VM4 the moment VM3 is deployed.
During placement DRS only checks the current affinity rules and determines if placement violates any affinity rules. If not, then the host with the most connections and the lowest utilization is selected. DRS cannot be aware of any future power-on operations, there is no vCrystal bowl. The next power-on operation might be 1 minute away or might be 4 days away. By allowing DRS to select the best possible placement, the virtual machine is provided an operating environment that has the most resources available at that time. If DRS took al the possible placement configurations into account, it could either end up in gridlock or place the virtual machine on a higher utilized host for a long time in order to prevent a vMotion operation of another virtual machine to satisfy the affinity rule. All that time that virtual machine could be performing beter if it was placed on a lower utilized host. On the long run, dealing with constraints the moment they occur is far more economical.
Similar behavior occurs when creating a rule. DRS will not display a warning when creating a collections of rules that create a conflict when all virtual machines are turned on. As DRS is unaware of the intentions of the user, it cannot throw a warning. Maybe the virtual machines will not be powered on in the current cluster state. Or maybe this ruleset is in preparation for the new hosts that will be added to the cluster shortly. Also understands that if a host is in maintenance mode, this host is considered to be external to the cluster. It does not count as an valid destination and the resources are not used in the equation. However we as users still see the host part of the cluster. If those rule sets are created while a host is in maintenance mode, than according to the previous logic DRS must throw an error, while the user assumes the rules are correct as the cluster provides enough placement options. As clusters can grow and shrink dynamically, DRS deals only with violations when the rules become active and that is during power-on operations (DRS placement).