First rule of Home Lab club, don’t talk about time sync! Or so it seems. When starting your home lab, all hints and tips are welcome. The community is full of wisdom, however sometimes certain topics are taken for granted or are perceived as common knowledge. The Home Lab fundamentals series focusses on these subjects, helping you how to avoid the most common pitfalls that provide headaches and waste incredible amounts of time. A ‘time-consuming’ pitfall is dealing with improper time synchronization between the various components in your lab environment.
Most often, the need for time synchronization is seen as an Enterprise requirement but not really necessary for lab environments. Maybe because most think time synchronization is solely necessary for troubleshooting purposes. In some cases, this is true as ensuring correct time notation allows for proper correlation of events. Interestingly enough, this alone should be enough reason to maintain synchronized clocks throughout your lab, but most home labs are just rebuilt when troubleshooting becomes too time-consuming. However time sync is much more expedite troubleshooting and ignoring time drift is a straight path into the rabbit hole. Time synchronization utilities such as NTP are necessary to correct time drift introduced by hardware time drift and guest operating system timekeeping imprecision. When time differs between systems to much it can lead to installation and authentication errors. Unfortunately, time issues are not always easily identifiable, to provide a great example;
“[400] An error occurred while sending an authentication request to the vCenter Single Sign-On server – An error occurred when processing the metadata during vCenter Single Sign-On setup – null.”
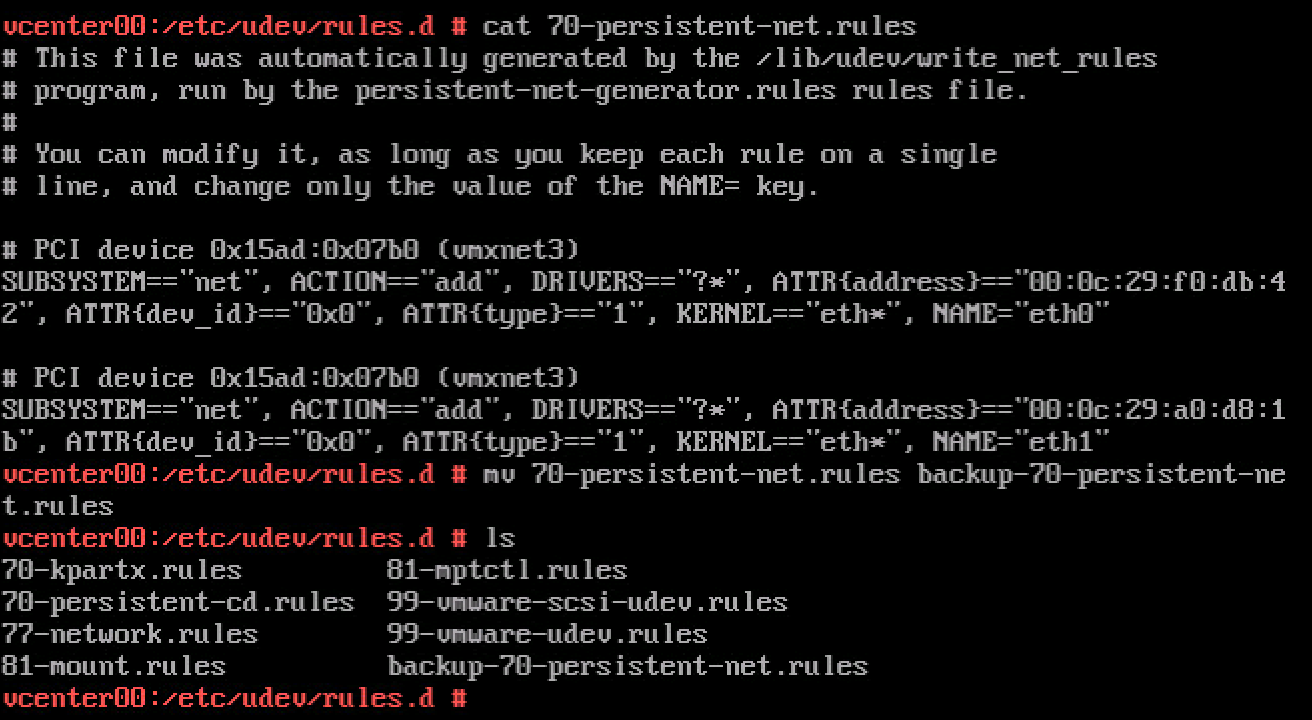
This particular issue occurs due to a time skew between the vCenter Server Appliance 6.0 and the external Platform Service Controller. Here are just a few other examples of what can go wrong in your lab due to time skew issues;
- Adding a host in vCenter Server fails with the error: Failed to configure the VIM account on the host (1029863) Time skew between ESXi host hardware clock and vCenter Server system time. https://kb.vmware.com/kb/1029863
- After joining the Virtual Center Server Appliance to a domain you cannot see domain when adding user permissions (2011965): This issue occurs when the time skew between the Virtual Center Server Appliance(VCSA) and a related Domain Controller is greater than 5 minutes. https://kb.vmware.com/kb/2011965
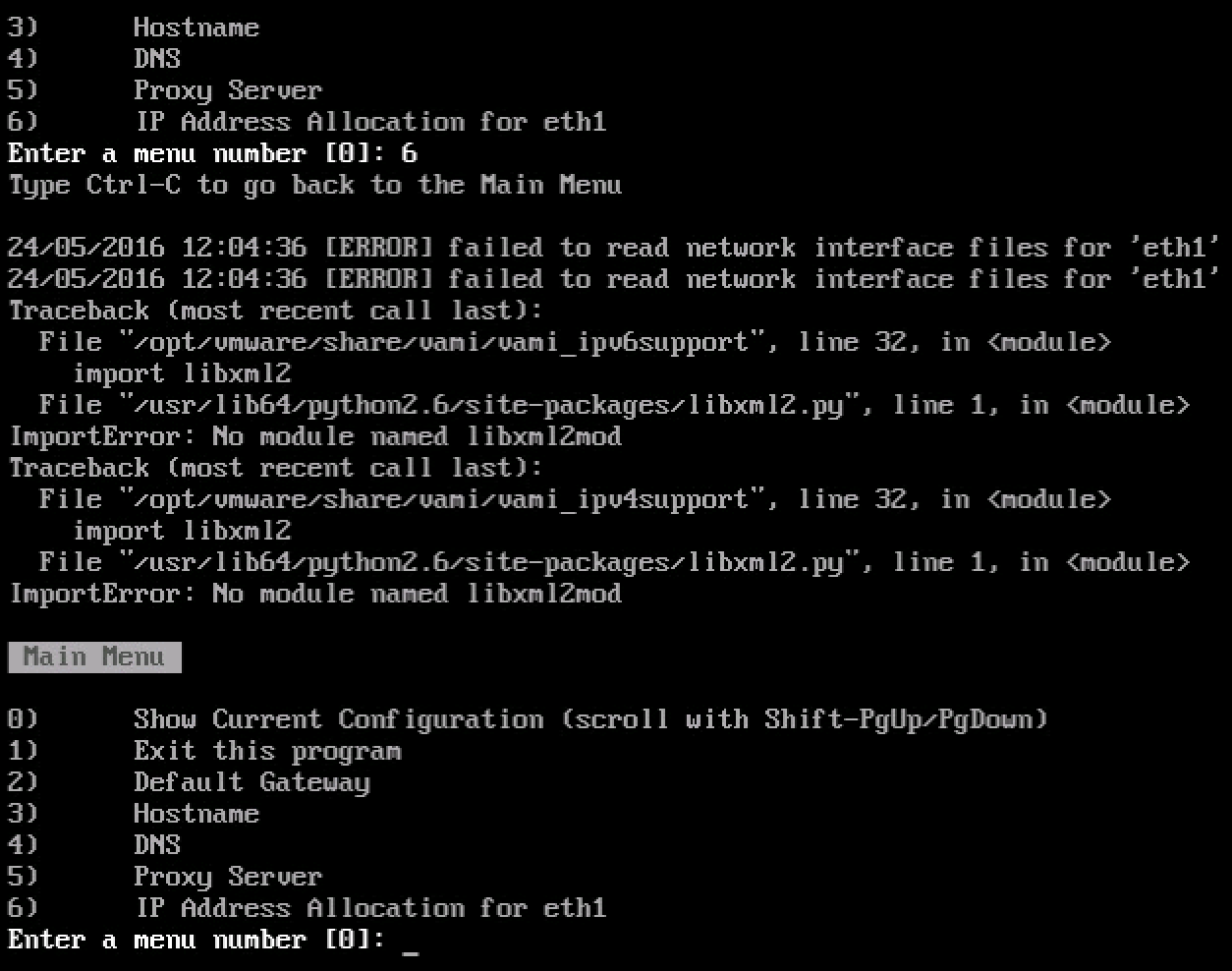
- Cluster level performance graphs show the most recent value as 0: This metric is susceptible to clock skew between the vSphere Client, vCenter Server, and ESX hosts. If any of the hosts have a skewed clock, the entire cluster shows as 0. https://kb.vmware.com/kb/2009550
- The vCenter Server Appliance installation fails when connecting to an External Platform Services Controller: This issue occurs when the system time on the system hosting the PSC does not match the time of the system where vCenter Server is installed. https://kb.vmware.com/kb/2128811
- Configuring the NSX SSO Lookup Service fails (2102041): Connectivity issues between the NSX Manager to vCenter Server due to time skew between NSX Manager and vCenter Server. https://kb.vmware.com/kb/2102041
- Authentication Errors are Caused by Unsynchronized Clocks: If there is too great a time difference between the KDC and a client requesting tickets, the KDC cannot determine whether the request is legitimate or a replay. Therefore, it is vital that the time on all of the computers on a network be synchronized in order for Kerberos authentication to function properly. https://technet.microsoft.com/en-us/library/cc780011(v=ws.10).aspx
Timekeeping best practices by VMware
Simply put, when weird behavior during setup or authentication occurs, check the time between the various components first. VMware released multiple knowledge Base articles and technical documents that contain detailed information and instructions on timekeeping within the various components of the virtual datacenter:
- Timekeeping in Vmware virtual Machines: http://www.vmware.com/files/pdf/Timekeeping-In-VirtualMachines.pdf
- Timekeeping best practices for Windows, including NTP (1318): https://kb.vmware.com/kb/1318
- Timekeeping best practices for Linux guests (1006427): https://kb.vmware.com/kb/1006427
- ESX and ESXi host time keeping Best Practices: https://kb.vmware.com/kb/2004453
VMware doesn’t provide a separate time keeping best practices document for vCenter, but provides multiple guidelines in the vCenter Server Appliance configuration guide. When installing vCenter on a Windows machine it’s recommended to sync to the PDC emulator within the Active Directory domain. In general, VMware recommends to use native time synchronization software, such as Network Time Protocol (NTP) with the various vSphere components. NTP is typically more accurate than VMware Tools periodic time synchronization and is therefore preferred.
Time synchronization design
There are multiple schools of thoughts when it comes to time sync in a virtual data center. One of the most common ones is to synchronize the virtual datacenter infrastructure components such as ESXi hosts and the VCSA to a collection of external NTP server. Typically provided by http://www.pool.ntp.org/en/ or the US Naval observatory: http://tycho.usno.navy.mil/NTP/. Windows virtual machines sync their time to the Active Directory domain controller running the PDC emulator FSMO role: Time Synchronization in Active Directory Forests http://social.technet.microsoft.com/wiki/contents/articles/18573.time-synchronization-in-active-directory-forests.aspx It’s recommended to point the ESXi hosts to the same time source as the PDC emulator of the active directory. When running Linux best practice is to sync these systems with an NTP server.
Another widely adopted design is to sync ESX servers to the to the Active Directory domain controller running the PDC emulator FSMO role. VCSA time keeping configuration provide two valid options; NTP and hosts. In this scenario, select the host option to ensure time between the host and VCSA is in sync. If the VCSA is using a different time source other than the ESX host, a race condition can occur between time sync operations and can lead to failing the vpxd.

Source: VMware vCenter Server 6.0 Update 1b Release Notes: http://pubs.vmware.com/Release_Notes/en/vsphere/60/vsphere-vcenter-server-60u1b-release-notes.html
But the most interesting thing I witnessed that can easily become a wild-goose chase is the VM tools time synchronization when time on an ESXi host is incorrect. As described earlier, enabling VMware tools time sync on virtual machines was a best practice for a long time. Shifting towards native time synchronization software led VMware to disable the periodic time synchronization option by default. The keyword in the last sentence is PERIODIC. By default VMware tools synchronizes time with the host during the following options:
- Resuming a suspended virtual machine
- Migrating a virtual machine using vMotion
- Taking a snapshot
- Restoring a snapshot
- Shrinking the virtual disk
- Restarting the VMware tools service inside the VM
- Rebooting the virtual machine
The time synchronization checkbox controls only whether time is periodically resynchronized while the virtual machine is running. Even if this box is unselected, by default VMware Tools synchronizes the virtual machine’s time to the ESXi host clock after the listed events. If the ESXi host time is incorrect it is likely that “unexplainable” errors will occur. I experienced this behavior after migrating a VM with vMotion. I couldn’t log on to a windows server as the time skew prevented me from authenticating.
You can either disable these options by adding rules to the VMX file of each VM or just ensure that the ESXi host is syncing the time with a proper external time source. For more information: Disabling Time Synchronization (1189) https://kb.vmware.com/kb/1189.
No time zone for ESXi
Be aware that as of vSphere 4.1 ESXi hosts are set to Universal Time Coordinated (UTC) time. UTC is interesting as its the successor of Greenwich Mean Time (GMT) but UTC itself is not a time zone, but a time standard. There are plenty of articles about UTC, but the key thing to understand is that it never observes Daylight Saving Time. As UTC is not a time zone, you cannot change the time notation in ESXi itself. The vSphere client, web client and HTML5 client automatically display the time in your local time zone and will take into account the UTC setting on the host. This isn’t bad behavior, just be aware of this so you don’t freak out when you check the time via the command line.

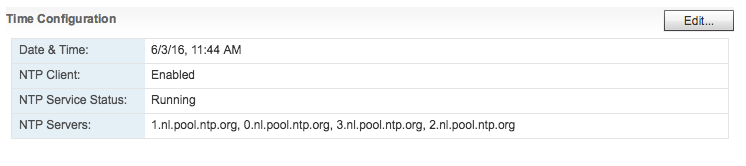
CMOS clock
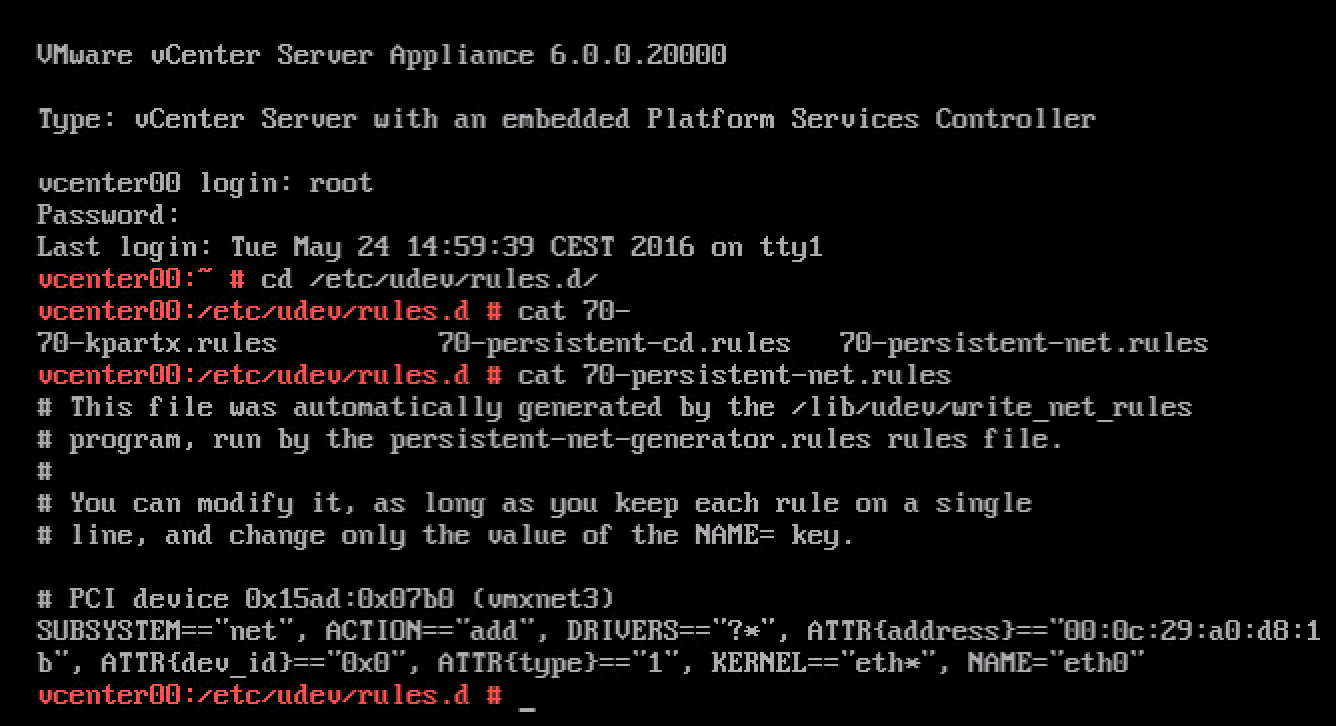
ESXi synchronizes its system time with the hardware clock (CMOS/BIOS/ACPI)of the server if the NTP service is not running on the ESXi host. SuperMicro boards allow for NTP synchronization, but most home lab motherboards just provide the time as being configured in the BIOS. When the NTP daemon is started on the ESXi host it synchronizes its system time to the external time source AND it updates the hardware clock as well. I ran a test to verify this behavior. At the time of testing it was 12:37 (GMT+1 | UTC 10:37), NTP turned off and set the time in the BIOS to 6:37 UTC time. After booting the machine the command esxcli system time get confirmed ESX system time retrieved the time from the hardware clock. After starting the NTP Services, the system time was set to the correct time: 10:37.The command esxcli hardware clock get demonstrated that NTP also corrected the BIOS time. A quick BIOS check confirmed esxcli hardware clock get was displaying the BIOS configuration.

If your lab is not connected to the internet, confirm the BIOS time with the command esxcli hardware clock get and if necessary use the command esxcli hardware clock set -d (Day) -H (Hour) -m (Minute) -M (Month) -s (Second) -y (Year) to set the correct time.
Please note that ESXCLI reports time with the Z (Zulu) notation, this is the military name for UTC.
Raspberry Pi as a Stratum-1 NTP Server
When having a home lab, you usually face the age old dilemma common sense vs ‘exciting new stuff that you might not need but you would like to have’. You can update your CMOS clock manually or scripted, you can connect to an array of external NTP servers or you can build your own Stratum-1 NTP server using a Raspberry PI with a GPS add-on board .
Up next in this series:Home Lab fundamentals: Reverse DNS