Next week we are back in Las Vegas. Busy times ahead with meeting customers, old friends, making new friends, and presenting a few sessions. Next week I will present at Customer Technical Exchange (CTEX), {code}, and host two meet-the-expert sessions. I will also participate as a part-time judge at the {code} hackathon.
Breakout Sessions
45 Minutes of NUMA (A CPU is not a CPU Anymore [CODEB2761LV]
Tuesday, Aug 22, 2:45 PM – 3:30 PM PDT Level 4, Delfino 4003
Yu Wang and I will dive deep into the new Multi-Chip CPU architecture, On-board Accelerators, and Sub-NUMA clustering and highlight cool new vSphere 8 features that will make your life as a Vi-admin easier.
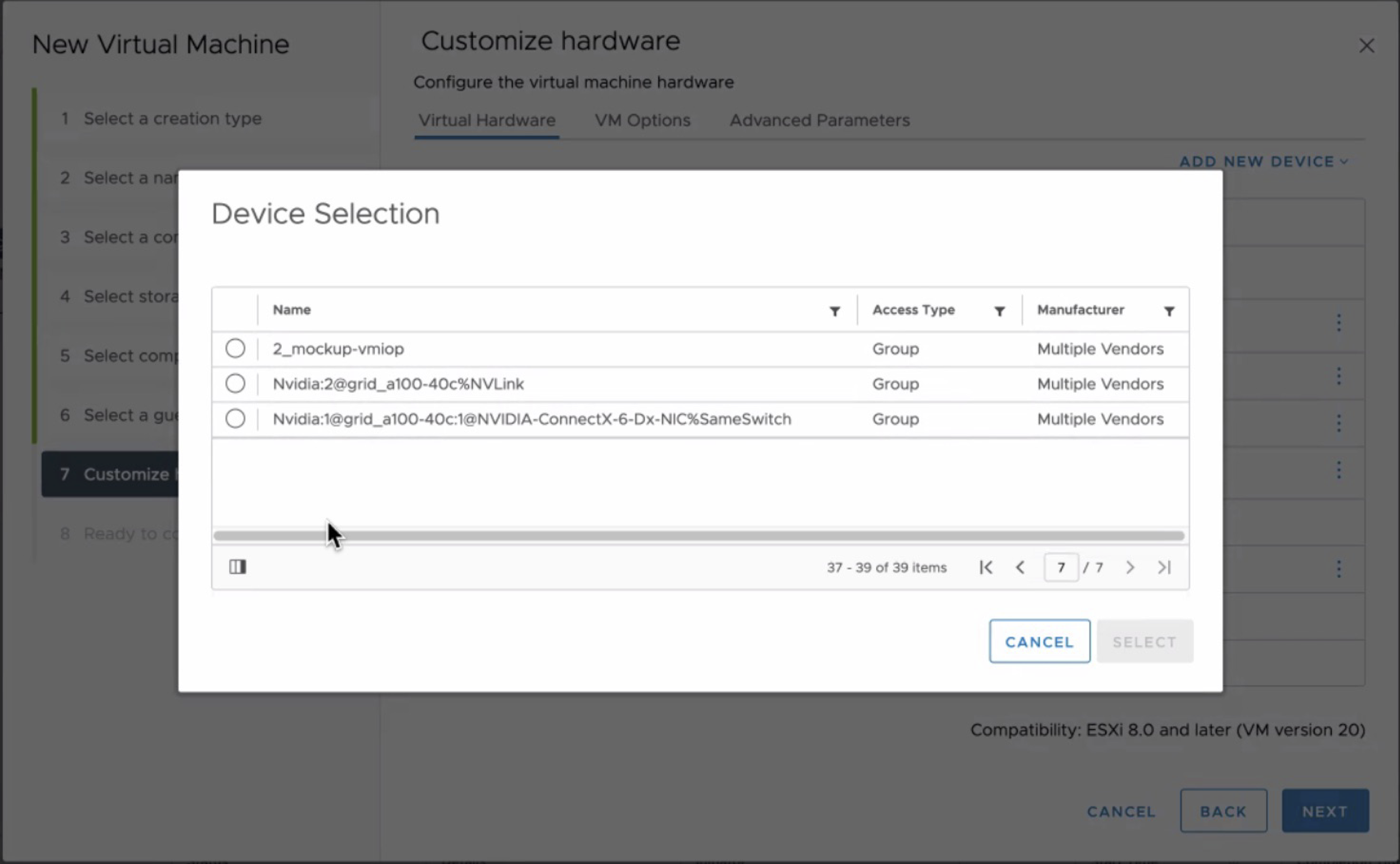
Building an LLM Deployment Architecture – 5 lessons learned [CTEX]
Tuesday, Aug 22, 4:00 PM – 5:00 PM PDT, Zeno 4708
Shawn Kelly and I will go over the details on how to create a deployment architecture for fine-tuning and deploying Large Language Models on your vSphere environment. Shawn and I have been deploying and developing a chatbot application with a data science team within VMware, and we want to share our lessons learned.
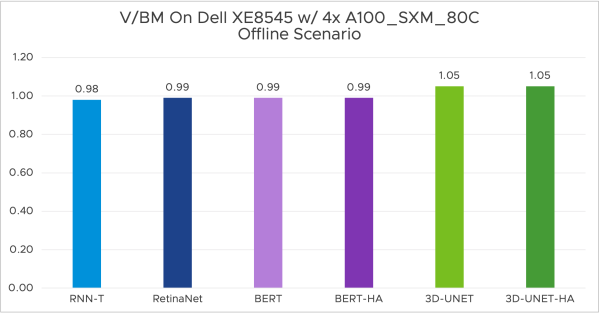
What’s new with VMware+NVIDIA AI-Ready Enterprise Platform [CEIB3051LV]
Thursday, Aug 24, 10:00 AM – 10:45 AM PDT Level 2, Titian 2305
Watch Raghu’s keynote, and then come to this session later next week. Due to NDA rules, we cannot disclose any content in the description of the current Explore Content Catalog. If you are planning to run Machine Learning workloads in your organization, join this session to hear about our latest offering that NVIDIA and VMware have created together.
Meet The Expert Sessions
Machine Learning Accelerator Deep Dive [CEIM1849LV]
Monday, Aug 211:00 PM – 1:30 PM PDTMeet the Experts, Level 2, Ballroom G, Table 7
Wednesday, Aug 2311:00 AM – 11:30 AM PDTMeet the Experts, Level 2, Ballroom G, Table 7
Have questions about your ML workload or are not sure whether vSphere is the platform for ML workload? Sign up for the MtE session, and let’s discuss your challenges.
If you see me walk by, say hi!