VMware has made some changes to the CPU scheduler in ESX 4.1; one of the changes is the support for Wide virtual machines. A wide virtual machine contains more vCPUs than the total amount of available cores in one NUMA node. Wide VM’s will be discussed after a quick rehash of NUMA.
NUMA
NUMA stands for Non-Uniform Memory Access, which translates into a variance of memory access latencies. Both AMD Opteron and Intel Nehalem are NUMA architectures. A processor and memory form a NUMA node. Access to memory within the same NUMA node is considered local access, access to the memory belonging to the other NUMA node is considered remote access.

Remote memory access is slower, because the instructions has to traverse a interconnect link which introduces additional hops. Like many other techniques and protocols, more hops equals more latency, therefore keeping remote access to a minimum is key to good performance. (More info about NUMA scheduling in ESX can be found in my previous article “Sizing VM’s and NUMA nodes“.)
If ESX detects its running on a NUMA system, the NUMA load balancer assigns each virtual machine to a NUMA node (home node). Due to assigning soft affinity rules, the memory scheduler preferentially allocates memory for the virtual machine from its home node. In previous versions (ESX 3.5 and 4.0) the complete virtual machine is treated as one NUMA client. But the total amount of vCPUs of a NUMA client cannot exceed the number of CPU cores of a package (physical CPU installed in a socket) and all vCPUs must reside within the NUMA node.

If the total amount of vCPUs of the virtual machine exceeds the number of cores in the NUMA node, then the virtual machine is not treated as a NUMA client and thus not managed by the NUMA load balancer.

Because the VM is not a NUMA client of the NUMA load balancer, no NUMA optimization is being performed by the CPU scheduler. Meaning that the vCPUs can be placed on any CPU core and memory comes from either a single CPU or all CPUs in a round-robin manner. Wide virtual machines tend to be scheduled on all available CPUs.

Wide-VMs
The ESX 4.1 CPU scheduler supports wide virtual machines. If the ESX4.1 CPU scheduler detects a virtual machine containing more vCPUs than available cores in one NUMA node, it will split the virtual machine into multiple NUMA clients. At the virtual machine’s power on, the CPU scheduler determines the number of NUMA clients that needs to be created so each client can reside within a NUMA node. Each NUMA client contains as many vCPUs possible that fit inside a NUMA node.
The CPU scheduler ignores Hyper-Threading, it only counts the available number of cores per NUMA node. An 8-way virtual machine running on a four CPU quad core Nehalem system is split into a two NUMA clients. Each NUMA client contains four vCPUs. Although the Nehalem CPU has 8 threads 4 cores plus 4 HT “threads”, the CPU scheduler still splits the virtual machine into multiple NUMA clients.

The advantage of wide VM
The advantage of a wide VM is the improved memory locality, instead of allocating memory pages random from a CPU, memory is allocated from the NUMA nodes the virtual machine is running on.
While reading the excellent whitepaper: “VMware vSphere: The CPU Scheduler in VMware ESX 4.1 VMware vSphere 4.1 whitepaper” one sentence caught my eye:
However, the memory is interleaved across the home nodes of all NUMA clients of the VM.
This means that the NUMA scheduler uses an aggregated memory locality of the VM to the set of NUMA nodes. Call it memory vicinity. The memory scheduler receives a list (called a node mask) of the NUMA node the virtual machine is scheduled on.

The memory scheduler will preferentially allocate memory for the virtual machine from this set of NUMA nodes, but it can distributed pages across all the nodes within this set. This means that there is a possibility that the CPU from NUMA node 1 uses memory from NUMA node 2.
Initially this looks like no improvement compared to the old situation, but fortunately supporting Wide VM makes a big difference. Wide-VM’s stop large VM’s from scattering all over the CPU’s with having no memory locality at all. Instead of distributing the vCPU’s all over the system, using a node mask of NUMA nodes enables the VMkernel to make better memory allocations decisions for the virtual machines spanning the NUMA nodes.

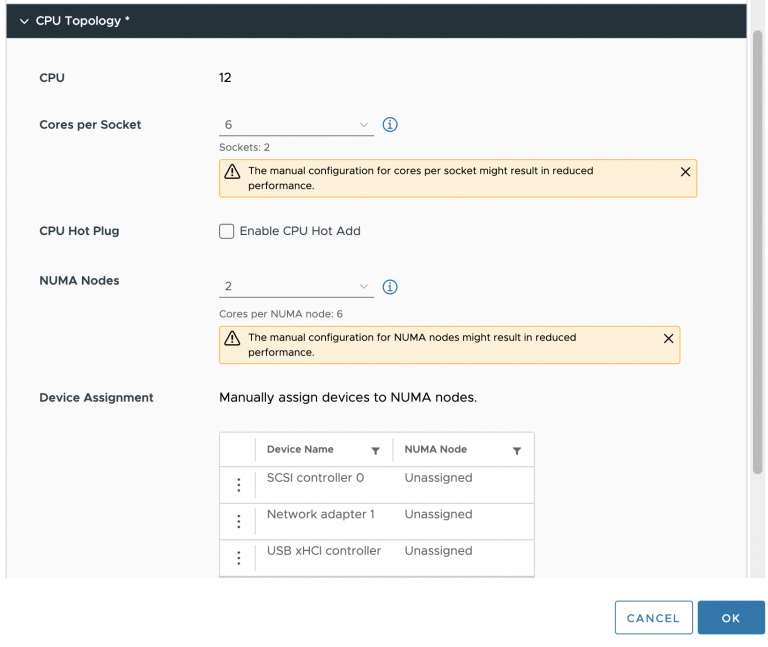
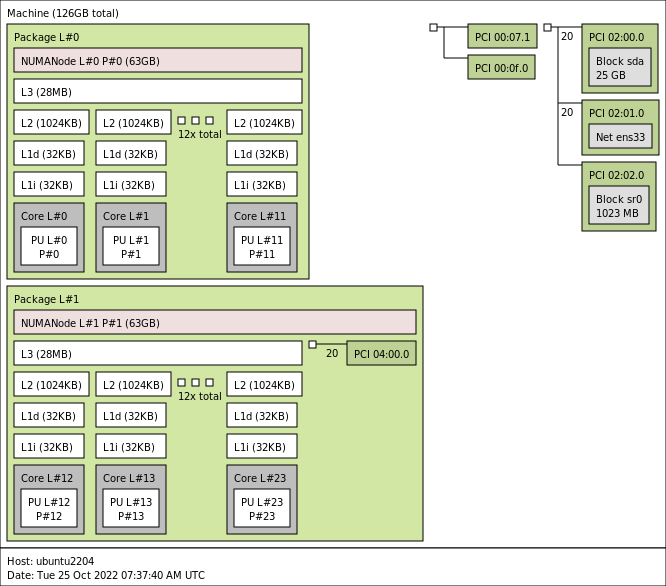
nice article again frank!
nice article again.
Hi Frank,
Very good post!
You say the number of cores and the number of NUMA clients is decided at startup of the VM. When a VM would VMotion from 4 core to 6 core CPU, would this not change the number of NUMA clients?
Gabrie
Hi Gabrie,
Thanks for the compliment.
The NUMA scheduler is a part of the local CPU and Memory scheduler and not of the global (DRS) scheduler, so the local scheduler calculates the amount of NUMA clients and assigns the NUMA nodes to the virtual machine. As the virtual machine is being migrated to the new host, the local CPU scheduler must assign the amount of NUMA clients. The CPU scheduler tries to load as many vCPU in a NUMA client, so my guess is that CPU scheduler creates a NUMA client containing 6 vCPU’s and a 2 vCPU numa client.
Great article Frank.
Just the information I was looking for as I’m looking into deploying 8vcpu vms.
I want to raise one question:
As you said in your article the CPU scheduler determines at boot time the number of NUMA clients.
So let’s asume I have 2 sockets packed with 12 cores each. If I boot up VM1 which has 8vcpu’s it’ll fit inside 1 NUMA client. The same is true for VM2, which also has 8vcpu’s.
Now let’s asume that both vm’s are heavy workloads and are scheduled all the time.
I now boot up VM3 (and VM4, ect,etc) with 8vcpu’s. The CPU scheduler determines the vm will fit into one NUMA client again.
When the CPU scheduler now wants to schedule this VM3 it cannot be scheduled together with VM1 and VM2 since I only have 2x 4 cores unoccupied. Does VM3 just need to wait for VM1 or VM2 to finish before it can be scheduled or will the CPU scheduler split this VM3 into 2 NUMA client (2x 4vcpu) so it can be scheduled simultaneously?
When the CPU scheduler only determines the number of NUMA clients at startup, I’m concluding that I won’t benefit from a 12core system over an 8core system if I only want to run 8vcpu machines! Is this correct?
Thanks for sharing.
-Arnim
Frank – great article! I had two questions for follow-up, one really more of a question/feature request.
1) Have you noticed that ESX seems to heavily favor NUMA nodes 0 and 1? I’ve seen in 4 socket environments (4 x 6 core, 128GB per host) that NUMA nodes 0 and 1 have almost no memory left in them while nodes 2 and 3 have nearly all of their memory available. I thought ESX performed migrations between NUMA nodes if that situation occurred but I’ve seen the behavior on at least 5 different ESX hosts.
2) Any idea when DRS will become NUMA aware and migrate VMs based on whether it could improve memory locality by moving VMs to another host? Seems like it would be easy enough to do. Then again I think we’ve all been waiting for a CPU Ready aware DRS so having one that is also NUMA aware is a pipe dream.
Keep up the great work…
Really nice article indeed ! About vmotion, my guess is the NUMA clients “split” is decided at VMM start rather that at the VM start so for each vmotion, NUMA clients are recalculated again. Am I right Frank ?
Just to be clear then: ESX 4.1 lessens but does not eliminate the performance penalty of having a VM wider than a single NUMA node.
If you have 4 NUMA nodes and your VM needs two of them, with ESX 4.1 the probability that any given CPU access to memory will be to a NUMA-local address is 1/2 instead of 1/4. (In practice there are probably factors that change those odds but that’s the first-order estimate.) For example, say the VM sits on nodes A and B but not C or D. When vCPU0 running on node A accesses memory, the memory could be on A or B (either equally likely) but–with 4.1–not on C or D.
Agreed?
Craig,
Totally! The memory can be supplied from one of the nodes listed in the node mask of the virtual machine. In your example, the node mask contains CPU A and B. C and D are not listed in the node mask and therefore the Memory scheduler uses a “soft” affinity rule for memory allocation in node A and node B.
its a soft affinity rule, because in the case of memory “shortage” in both nodes, the memory scheduler still can allocate remote memory. Remote memory is slower than local memory but still “way” better than ballooning, compressing or swapping.
Superb article Frank, clarifies a lot of my fears around a 3rd party vendor asking us to implement 8-vCPU SQL and application VMs on 2 x 6 core westmere. What’s worse is their application is heavily memory driven to reduce latency so I have highlighted this particular issue to them as it could be a major problem.
When I asked them why the 8-vCPU machine, their answer was “because you have Enterprise Plus Licensing and you can”. Needless to say I have since put them directly in touch with the VMware ISV certification team as I think they have a bit of learning to do about the downside of insisting on 8-vCPU machines.
Great work as always Frank
Cheers
Craig
Great article, sorry for hijacking..
@Matt Liebowitz – On a 4 NUMA Node box (AMD) I have seen the issue of NUMA nodes 0 and 1 being heavily loaded (high cpu ready time) when nodes 2 and 3 are almost unused. I have logged NUMEROUS SR’s with VMware with no luck (they KNOW there is an issue). My best option was to actually reduce the amount of memory in my servers, thus making the NUMA nodes smaller, which then made the scheduler use nodes 2/3 more.
There is a command line, which changes the default behaviour of the scheduler, whereby it will round robin initially placement of VM’s, however I don’t find that this command line works that well to be honest.
Now that Intel boxes are NUMA, im sure they will get A LOT more complaints about how poor the NUMA scheduler is when compared to NON NUMA scheduling, eg you dont get HOT CPU’s on old school Intel boxes, all CPU’s run very evenly.
@Arnim – I was pondering this same question recently (albeit with reference to Westmere CPU’s (6 cores each) and 3 x 4 vCPU VM’s heavily loaded with a properly multithreaded application.
Prior to ESX 4.0, with the cell scheduler, if you leave the default cell size of 4 (on a 6-core CPU) then as detailed in http://kb.vmware.com/kb/1007361 you would get 2 VM’s running entirely within a node and 1 VM split across nodes.
But as we all know (thanks in no small part to posts like this from Frank), the cell scheduler is gone in 4.x. Since all the VM’s in this scenario would be identified as NUMA clients, I guess several questions are raised:
1) Is the decision to run a VM as a NUMA client based purely on number of vCPU’s of the VM, or is system load taken into account? I’m leaning towards purely vCPU, otherwise you would get different behaviour depending on whether all 3 were powered on simultaneously or if 2 were powered on and under load before the 3rd was powered on.
2) Is the NUMA scheduler so strict that it will only schedule a client within a node, even though it would result in an unbalanced system load? From everything I have read, this appears to be the case.
3) Can a running VM be migrated from one scheduler to another? This capability would provide a solution, however I have no idea if that’s what happens or even if it’s technically possible.
Depending on the answer, you may find you’d actually be better off creating VM’s with 3vCPUs when you have 6-core CPUs. Don’t be fooled into thinking that a 3vCPU machine is not SMP – the ‘S’ in SMP simply denotes that all CPU’s have access to the same resources, not that there needs to be an even number of CPUs :). An ASMP system is denoted by specific CPUs doing specific things.
Finding the answer to this should keep Frank busy at VMworld, although it wouldnt surprise me if he knew if off the top of his head 😉
Bump, wondering if anybody have any updates at all, have things improved in 4.1 in regards to NUMA boxes and poor VM distribution between NUMA nodes? Ive moved on to an Intel only site (old intel no NUMA), but am about to deploy some 48 core AMD boxes, so would be interested to know if the situation has changed
@Brandon – we’re experiencing the same issue. HP BL460c blades (Nehalem) and one NUMA node is at 99% memory utilisation whereas the other is only 25%. The memory locality of one VM is at only 54% even though there’s enough free memory on the other node for it to be migrated but it never does. We’re only on v4.0u1 admittedly – upgrading and trying the round robin fix are my next steps.
Hi Frank,
Really useful article indeed =)
I just want to know, can we know how many vCPU will we have in a host? Let’s say I have a Xeon X5675 host (has 6 core, 12 threads) and a X5570 (4 core, 8 threads). How many vCPU available that can be assigned to a single VM?
Many thanks in advance
We have had lots of issues with poor NUMA balancing on Four CPU 12-core AMD hosts (48 cores). I have been up and down with our TAM and GSS and they have discovered why the nodes aren’t being rebalanced. During vMotion the world is not entirely initialized on the destination host, so the NUMA round-robin isn’t invoked and most/all VMs keep getting placed in NUMA node 0/1. They recognize the issue but getting answers on when its getting fixed has been difficult.
Frank,
First of all – great article. I’ve done quite a reading recently about this topic and by observing my production environment (4.1 U1, HP BL460 G6, 2 QC CPUs, 96GB of RAM – 48GB on each CPU) got questions I could not find answers yet:
For example – I have bunch of VMs running on that host. Number of VCPUs of any particular VM does not exceed number of cores: I have mostly 2 and some 4 VCPU VMs, RAM of VMs fit entirely into NUMA node – most of VMs have 4GB or 6GB of RAM, however there are couple of 16GB VMs.
Yet I see that some VMs display very poor memory locality (less than 30% – one memory intensive VM with 16GB of RAM has 13% of local memory access according to esxtop) but at the same time ESX server is not memory overcommited and there is enough memory available on each NUMA node.
Why does this happen and why CPU/NUMA schedule does not try to improve memory locality? Also, according to esxtop there was no migration of the VM on another NUMA node despite the fact that other node has enough free memory available.
vSphere 4.1 Resource Management Guide, page 20 says following:
—
In undercommitted systems, the ESX CPU scheduler spreads load across all sockets by default. This improves performance by maximizing the aggregate amount of cache available to the running virtual CPUs. As a result, the virtual CPUs of a single SMP virtual machine are spread across multiple sockets (unless each socket is also a NUMA node, in which case the NUMA scheduler restricts all the virtual CPUs of the virtual machine to reside on the same socket.)
In some cases, such as when an SMP virtual machine exhibits significant data sharing between its virtual CPUs, this default behavior might be sub-optimal. For such workloads, it can be beneficial to schedule all of the virtual CPUs on the same socket, with a shared last-level cache, even when the ESX/ESXi host is undercommitted. In such scenarios, you can override the default behavior of spreading virtual CPUs across packages by including the following configuration option in the virtual machine’s .vmx configuration file: sched.cpu.vsmpConsolidate=”TRUE”.
To find out if a change in this parameter helps with performance, please do proper load testing.
—–
Does sched.cpu.vsmpConsolidate=”TRUE” setting has any effect on NUMA systems and memory locality?
Further down in the document, page 86:
—
When memory is allocated to a virtual machine, the ESX/ESXi host preferentially allocates it from the home node.
The NUMA scheduler can dynamically change a virtual machine’s home node to respond to changes in system load. The scheduler might migrate a virtual machine to a new home node to reduce processor load imbalance. Because this might cause more of its memory to be remote, the scheduler MIGHT MIGRATE the virtual machine’s memory dynamically to its new home node to improve memory locality.
—
I highlighted the interesting point above in all caps. One more quote – page 87:
—
Unless a virtual machine’s home node changes, it uses only local memory, avoiding the performance penalties associated with remote memory accesses to other NUMA nodes.
Rebalancing is an effective solution to maintain fairness and ensure that all nodes are fully used. The rebalancer might need to move a virtual machine to a node on which it has allocated little or no memory. In this case, the virtual machine incurs a performance penalty associated with a large number of remote memory accesses.
ESX/ESXi can eliminate this penalty by transparently migrating memory from the virtual machine’s original node to its new home node:
1 The system selects a page (4KB of contiguous memory) on the original node and copies its data to a page in the destination node.
2 The system uses the virtual machine monitor layer and the processor’s memory management hardware to seamlessly remap the virtual machine’s view of memory, so that it uses the page on the destination node for all further references, eliminating the penalty of remote memory access.
—
So my questions are:
What are factors influencing the decision of scheduling of the particular VM on the particular NUMA node and migration of a VM between NUMA nodes?
Do other settings on ESX server affect memory locality? I disabled large pages on ESX server to improve TPS ratio (memory utilization on ESX server declined from 70% to 40%) could it play a role into poor locality?
VM’s home node has never changed (NMIG=0 for all VMs) yet some VMs are using remote memory and at the same time there is enough free memory available on the home NUMA node. Even when VM is using remote memory, the percentage of that remote memory usage has not declined after time – above mentioned 4KB page copying mechanism does not work. Why?
On page 114 there is mentioning of VM’s advanced setting:
numa.mem.interleave – Specifies whether the memory allocated to a virtual machine is statically interleaved across all the NUMA nodes on which its constituent NUMA clients are running. By default, the value is TRUE.
If I put FALSE on that setting will that mean that VM won’t use remote memory?
Here – http://download.virtuallyghetto.com/hidden_vmx_params.html I also found some other NUMA related undocumented parameters:
numa.mem.firstAccess
numa.mem.nextAccess
I would be interested if anyone can comment on these.
——————–
Anyway, why I wrote this essay – most of our apps are memory intensive and performance depends on it. I have not yet seen what performance penalties are associated with the remote memory access, but two academic research papers I found give quite a serious thought base:
Measuring NUMA effects with the STREAM benchmark
http://arxiv.org/PS_cache/arxiv/pdf/1103/1103.3225v1.pdf
A Case for NUMA-aware Contention Management on Multicore Systems
http://www.sfu.ca/~sba70/files/atc11-blagodurov.pdf
Hello, I’m new here, but I’m surprised about how good is your work Frank. So, let me ask you a question. If I have a server with 4 sockets and 6 cores per socket, and heavy loaded CPU Virtual Machines, what is the best? 4 VM with 6 vCPU or 3 with 8 vCPU. Please I need to know this. Thanks you very much.
Hi Frank
can you pls share your thoughts on vNUMA with by defualt enabled on more than 8 cores VM.
Rgds
Vishal