I received a lot of questions about Hyperthreading and NUMA in ESX 4.1 after writing the ESX 4.1 NUMA scheduling article.
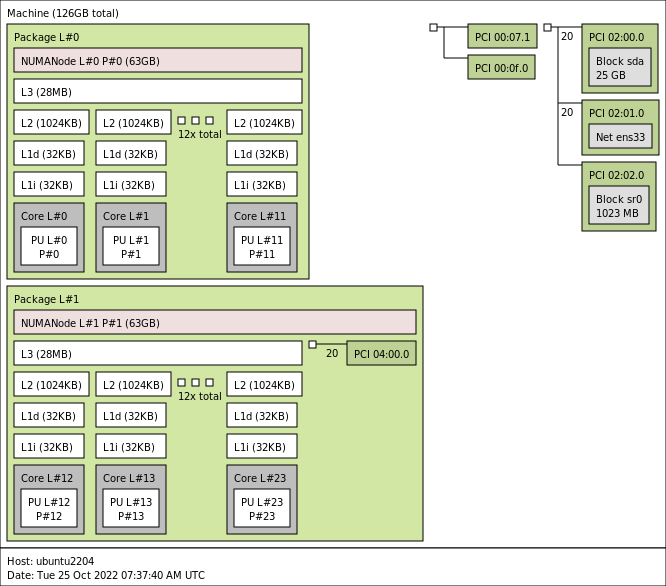
A common misconception is that Hyperthreading is ignored and therefore not used on a NUMA system. This is not entirely true and due to the improved Hyperthreading code on Nehalems, the CPU scheduler is programmed to use the HT feature more aggressively than the previous releases of ESX. The main reason why I think this misconception exists is the way the NUMA load balancer handles vCPU placement of vSMP virtual machine. Before continuing, let’s get our CPU elements nomenclature aligned, I’ve created a diagram showing all the elements:

The Nehalem Hyperthreading feature is officially called Symmetric MultiThreading (SMT), the term HT and SMT are interchangeable.
1. An Intel Nehalem processor often called a CPU or package.
2. An Intel Nehalem processor contains 4 cores in one package.
3. Each core contains 2 threads if Hyperthreading is enabled.
4. A SMT Thread equals a logical processor.
5. A logical processor is translated in esxtop as a PCPU.
6. A vCPU is scheduled on a PCPU.
7. NUMA= Non-uniform Memory Access (Each Processor has its own local memory assigned)
8. LLC= Last Level Cache: Shared by Cores is last on-die cache memory before turning to Local memory.
NUMA load balancer virtual machine placement
During placement of a vSMP virtual machine, the NUMA load balancer assigns a single vCPU per CPU core and “ignores” the availability of SMT threads. As a result a 4-way vSMP virtual machine will be placed on four cores. In ESX 4.1 this virtual machine can be placed on one processor or on two processors, depending on the amount of cores on the processor or if set the advanced option numa.vcpu.maxPerMachineNode.
When a virtual machine contains more vCPUs than the amount of cores the processor, this virtual machine will span across multiple processors (Wide-VM). The default policy is to span the virtual machine across as few processors (NUMA nodes) as possible, but this can be overridden by an advanced option called numa.vcpu.maxPerMachineNode, which defines the maximum amount of vCPUs of a virtual machine per NUMA client. But as always, only use advanced options if you know the full impact of this setting on your environment. But I digress; let’s go back to NUMA and Hyperthreading.
Now the key to understand is that only during placement the SMT threads are ignored by the NUMA load balancer. It is the up to the CPU scheduler to decide in which way it will schedule the vCPUs within the core. It can allow the vCPU to use the full core or schedule it on a SMT thread depending on the workload, resource entitlement, the amount of active vCPUs and available pCPUs in the system.
Because SMT threads share resources within a core will result into lesser performance than running a vCPU on a dedicated singe core. The ESX scheduler is designed in such a way that it will try to spread the load across all the cores in the NUMA node or in the server.
But basically, If the workload is low it will try to schedule the vCPU on a complete core, if that’s not possible, it will schedule the vCPU on a SMT thread.
As mentioned before, running a vCPU on a SMT thread will not offer the same progress than running on a complete core; therefore a different charging scheme is used for each scenario. This charging scheme is used to keep track of the delivered resources and to check if the VM gets it entitled resources, more on this topic can be found in the article “Reservations and CPU scheduling”.
NUMA.preferHT=One NUMA node to rule them all?
Although the CPU scheduler can decide how to schedule the vCPU within the core, it will only schedule one vCPU of a vSMP virtual machine onto one core. Scott Drummonds article about numa.preferHT might offer a solution. Setting the advanced parameter numa.preferHT=1 allows the NUMA load balancer to assign vCPU to SMT thread and if possible “contain” one vSMP VM into a single NUMA node. However the amount of vCPU must be less or equal than the amount of pCPUs within the NUMA node.
By placing all vCPUs within a processor a virtual machine with a “intensive-cache-footprint” workload can benefit from a “warmed-up” cache. The vCPUs can fetch the memory from Last Level Cache instead of turning to local memory resulting in less latency. And this is exactly why this setting might not be beneficial to most environments.
The numa.preferHT setting is a CPU scheduler wide setting, that means that the NUMA load balancer will place every vSMP virtual machine inside a processor i.e. both intensive cache workloads and low-cache footprint workloads. Currently the ESX 4.1 CPU scheduler does not detect different workloads so it cannot distinguish virtual machines from each other and select an appropriate placement method i.e. place the virtual machine within one processor and use SMT threads or use wide-VM numa placement and “isolate” a vCPU per core.
It is crucial to know that by placing all vCPU on one processor doesn’t guarantee it to have all its memory in local memory, the main goal is to use LLC as much as possible, but if there is a cache miss (memory not available in cache) it will fetch it from local memory. The VMkernel tries to keep memory as local as possible but if there is not enough room inside local memory, it will place the memory into remote memory. Storing memory in remote memory is still faster than swapping it out to disk but inter-socket communication is noticeable slower than intra-socket communications.
This brings me to migration of virtual machines between NUMA nodes, if a virtual machines home node is more heavily loaded than other NUMA nodes, it will be migrated to a less loaded NUMA node. During the migration phase, local memory turns into remote memory. This newly remote memory is moved gradually because moving memory has high overhead.
By using the numa.preferHT option forces you to scope the maximum amount of memory assigned to a virtual machine and the consolidation ratio. Having multiple virtual machine traverse the quick path interlink to fetch memory stored in remote memory defeats the purpose of containing the virtual machines inside a processor.

Frank, excellent article, thank you!
Hi Frank, excellent article. You seem to have some mighty wiki hidden in your pocket where you pull all this info from 🙂
The only little typo I’m wondering about is (third paragraphs from the bottom, last sentence):
“it will place the memory into remote memory. Storing memory in remote memory is still faster than swapping it out to disk but inter-socket communication is notable slower than inter-socket communications.”
Is that a typo? Did you mean “…but inter-socket communication is notable slower than intRA-socket communications.” ?
Jelle
Yes its a typo, thanks for the heads up.
Fixed!
Thanks for the detailed explanation Frank. So what I takeaway from this is using the config option numa.preferHT should be considered only where you have a detailed understanding on the workload characteristics of the specific VM’s that will run on an individual host where you enable this setting. I would probably want to apply this only where I have a static workload on a host (no drs)(like when you could pin a VM;s vcpu to a hosts pcpu). It sounds like this setting is applied per physical ESX host and will apply to all cores on that host.
So if I had an environment that was DRS enabled, and workloads floated around the individual hosts, I could end up with a hard to diagnose performance problem, especially if this was not enabled on all the hosts (and probably even then, but at least it would be “more” consistent).
Is that a fair characterization?
Hi Rob,
numa.preferHT is a Numa config option of the scheduler and not a .vmx setting so this setting is active at ESX level.
It is regarded best practise to configure all host with identical settings in the cluster, if you activate this option only on one host in the cluster you can expect some variance in diagnosing data.
Be aware that this is a local scheduler setting, so it applies on ESX host level and not DRS level. CPU scheduling decisions are left to the local CPU scheduler, the DRS scheduler only divvies cluster resources to the virtual machines.
Migrating a virtual machine from a host with this setting activated to a host with this setting disabled will not create any problems, you “only” will encounter different performance signatures.
A non-uniform cluster is a sure recipe for headaches and long nights of diagnosing performance data.
good article and add my knowledge about the progress of science technology in the world