

#47 – How VMware accelerates customers achieving their net zero carbon emissions goal
In episode 047, we spoke with Varghese Philipose about VMware’s sustainability efforts and how they help our customers meet...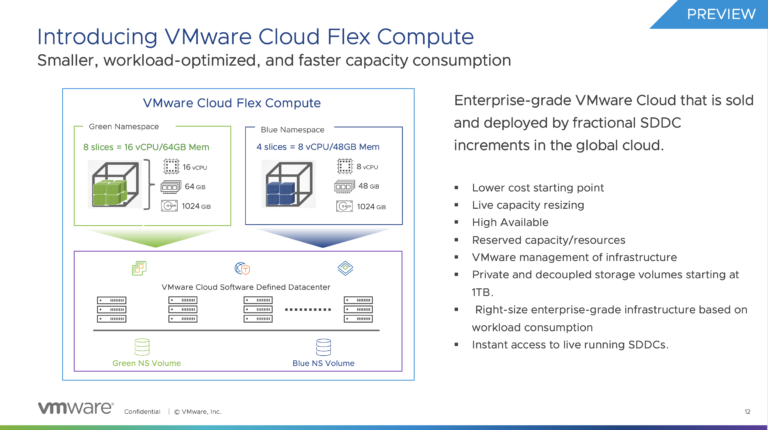
#46 – VMware Cloud Flex Compute Tech Preview
We’re extending the VMware Cloud Services overview series with a tech preview of the VMware Cloud Flex Compute service....
VMware Cloud Services Overview Podcast Series
Over the last year, we’ve interviewed many guests, and throughout the Unexplored Territory Podcast show, we wanted to provide...
Research and Innovation at VMware with Chris Wolf
In episode 042 of the Unexplored Territory podcast, we talk to Chris Wolf, Chief Research and Innovation Officer of...
Gen AI Sessions at Explore Barcelona 2023
I’m looking forward to next week’s VMware Explore conference in Barcelona. It’s going to be a busy week. Hopefully, I will...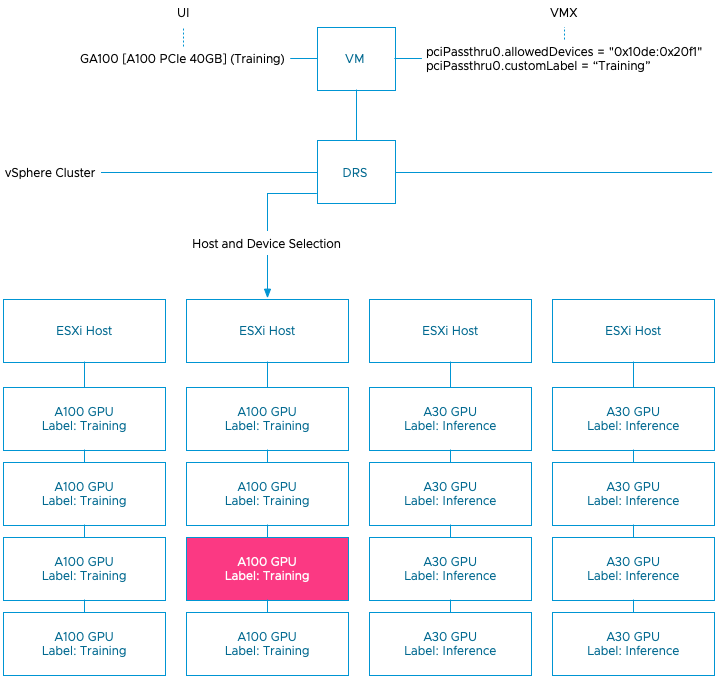
vSphere ML Accelerator Spectrum Deep Dive – Using Dynamic DirectPath IO (Passthrough) with VMs
vSphere 7 and 8 offer two passthrough options, DirectPath IO and Dynamic DirectPath IO. Dynamic DirectPath IO is the vSphere brand...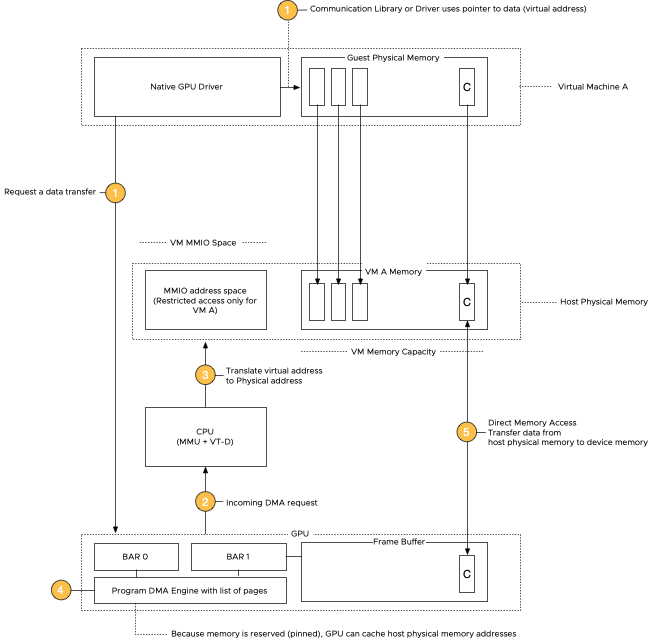
vSphere ML Accelerator Spectrum Deep Dive – ESXi Host BIOS, VM, and vCenter Settings
To deploy a virtual machine with a vGPU, whether a TKG worker node or a regular VM, you must enable some...All Stories

vSphere 8 and vSan 8 Unexplored Territory Podcast Double Header
This week we released two episodes covering the vSphere 8 and vSan 8 releases. Together with Feidhlim O’Leary, we discover all...
Unexplored Territory – VMware Explore USA Special
This week Duncan and I attended VMware Explore to co-present the session “60 Minutes of Virtually Speaking Live: Accelerating Cloud Transformation.”...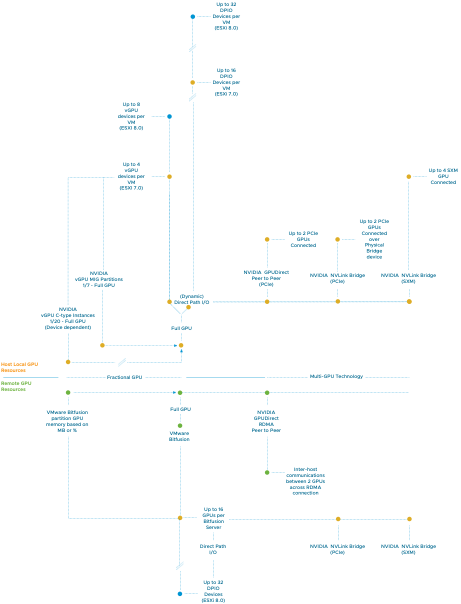
New vSphere 8 Features for Consistent ML Workload Performance
vSphere 8 is full of enhancements. Go to blogs.vmware.com or yellow-bricks.com for more extensive overviews of the vSphere 8 release. In this article, I want...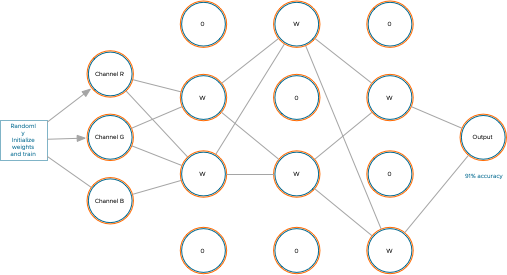
Training vs Inference – Network Compression
This training versus inference workload series provides platform architects and owners insights about ML workload characteristics. Instead of treating deep neural...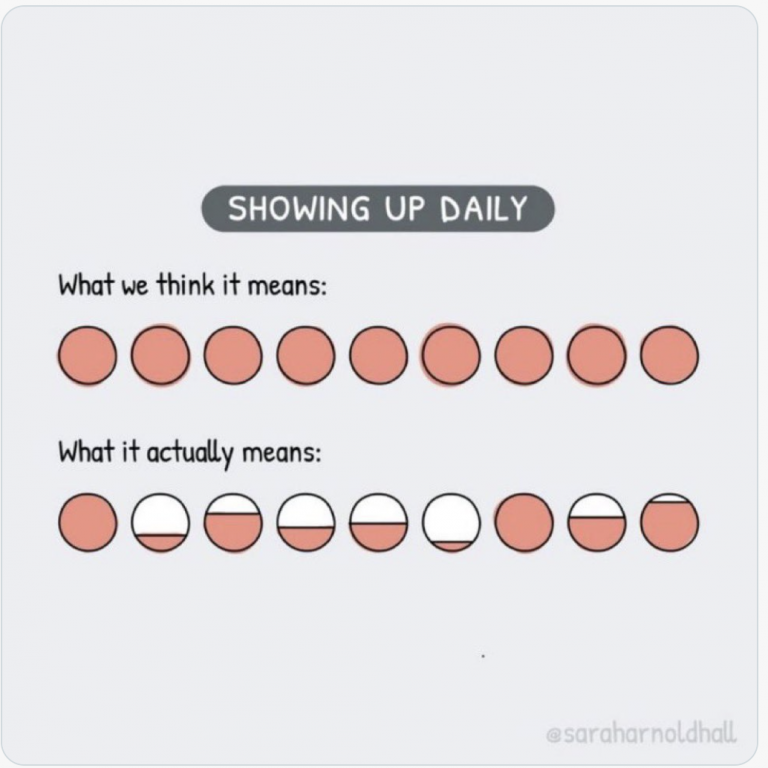
How to Write a Book – Show Up Daily
During the Belgium VMUG, I talked with Jeffrey Kusters and the VMUG leadership team about the challenges of writing a book....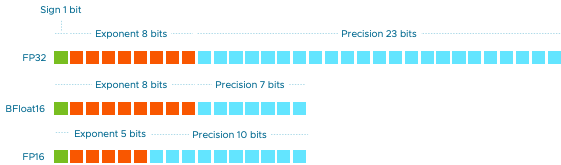
Training vs Inference – Numerical Precision
Part 4 focused on the memory consumption of a CNN and revealed that neural networks require parameter data (weights) and input data...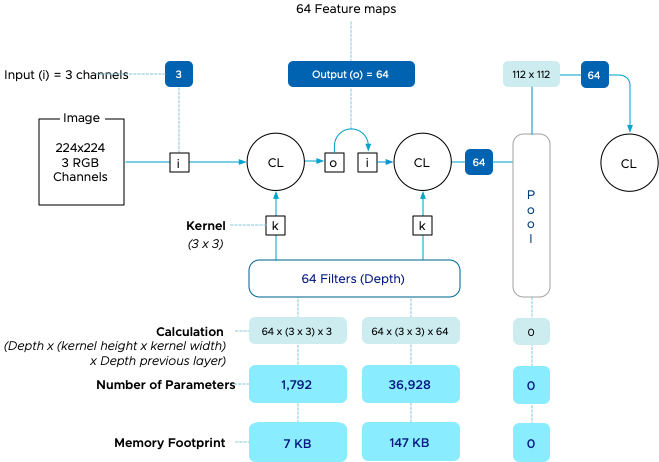
Training vs Inference – Memory Consumption by Neural Networks
This article dives deeper into the memory consumption of deep learning neural network architectures. What exactly happens when an input is...
Unexplored Territory Podcast Episode 19 – Discussing NUMA and Cores per Sockets with the main CPU engineer of vSphere
Richard Lu joined us to talk basics of NUMA, Cores per Socket, why modern windows and mac systems have a default...
Machine Learning on VMware Platform – Part 3 – Training versus Inference
Machine Learning on VMware Cloud Platform – Part 1 covered the three distinct phases: concept, training, and deployment, part 2 explored the...