A new round of VCDX defenses will kickoff soon and I want to wish everyone that participates in the panel session good luck. Usually when VCDX panels are near, I receive questions on how to prepare for a panel. And one recommendation I usually provide is
“Know why you used a specific configuration of a feature and especially know why you haven’t used the available alternatives”.
Let’s have some fun with this and go through a “defend clinic”. The point of this clinic is to provide you an exercise model than you can use for any configuration, not only for a vMotion configuration. It helps you to understand the relationship of information you provide throughout your documentation set and helps you explain how you derived through every decision to come to this design.
To give you some background, when a panel member is provided the participants documentation set, he enters a game of connecting the dots. This set of documents are his only view into the your world while creating the design and dealing with your customer. He needs to take your design and compare it to the requirements of the customer, the uncertainties you dealt with in the form of assumptions and the constraints that were given. Reviewing the design on technical accuracy is only a small portion of the process. That’s just basically checking to see if you are using your tools and material correctly, the remaining part is to understand if you build the house to the specification of the customer while dealing with regional laws and the available space and layout of the land. Building a 90.000 square feet single floor villa might provide you the most amount of easily accessible space, but if you want to build that thing in downtown Manhattan you’re gonna have a bad time. 😉
Structure of the article
This exercise lists the design goals and its influencers, requirements, constraints and assumptions. The normal printed text is architects (technical) argument while the paragraphs are displayed in Italic can be seen as questions or thoughts of a reviewer/panel member.
Is this a blue print on how to beat the panel? No! It’s just an exhibition on how to connect and correlate certain statement made in various documents. Now let’s have some fun exploring and connecting the dots in this exercise.
Design goal and influencers
Your design needs to contain a vMotion network as the customer wants to leverage DRS load balancing, maintenance mode and overall enjoy the fantastic ability of VM mobility. How will you design your vMotion network?
In your application form you have stated that the customer want to see a design that reduces complexity, increases scalability, prefers to have the best performance available as possible. Financial budget and the amount of IP-addresses are constraints and the level of expertise of the virtualization management team is an assumption.
Listing the technical requirements
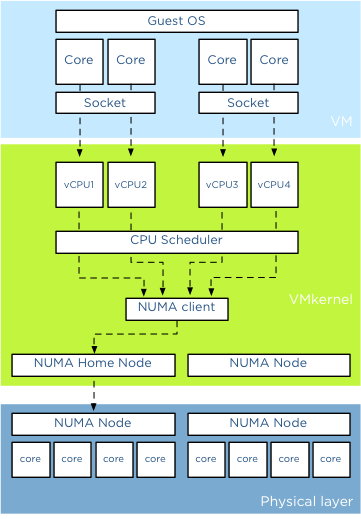
Since you are planning to use vSphere 5.x you have the choice to create a traditional single vMotion-enabled VMKnic, Multi-NIC vMotion setup or use vMotion configuration that uses “Route based on physical NIC load” load balance algorithm (commonly known as LBT) to distribute vMotion traffic amongst multiple active NICs. As the customer does not prefer to use link aggregation, IP-hash based / EtherChannel configurations are not valid.
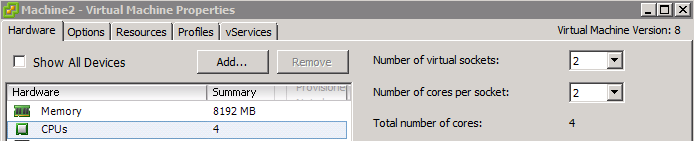
First let’s review the newer vMotion configurations and how they differentiate from the traditional vMotion configuration, where you have one single VMKnic, a single IP address, connected to a single Portgroup which is configured to use an active and standby NIC?
Multi-NIC vMotion
• Multiple VMKnics required
• Multiple IP-addresses required
• Consistent configuration of NIC failover order required
• Multiple physical NICs required
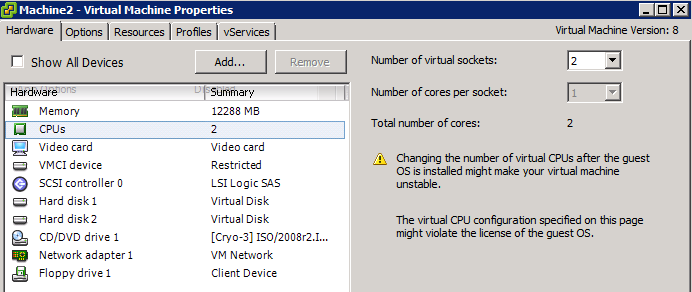
Route based on physical NIC load
• Distributed vSwitch required
• Multiple physical NICs required
It goes without saying that you want to provide the best performance possible that leads you into considering using multiple NICs to increase bandwidth. But which one will be better? A simple performance test will determine that.
VCDX application form: Requirements
In your application document you stated that one of the customer requirements was “Reducing complexity”. Which of the two configurations do you choose now, what are your arguments? How do you balance or prioritize performance over complexity reduction?
If Multi-NIC vMotion beats LBT configuration in performance, leading to faster maintenance mode operations, better DRS load balance operations and overall reduction in lead time of a manual vMotion process, would you still choose the simpler configuration over the complex one?
Simplicity is LBTs forte, just enable vMotion on a VMKnic, add multiple uplinks, set them to active and your good to go. Multi-NIC vMotion exists of more intricate steps to get a proper configuration up and running. Multiple vMotion-enabled VMKnics are necessary, each with their own IP-range configuration, secondly vMotion requires deterministic path control, meaning that it wants to know which path is selects to send traffic across.
As the vMotion load balancing process is higher up in the stack, NIC failover orders are transparent for vMotion. It selects a VMKnic and assumes it resembles a different physical path then the other available VMKnics. That means its up to the administrator to provide these unique and deterministic paths.
Are they capable of doing this? You mentioned the level of expertise of the admin team as an assumption, how do you guarantee that they can execute this design, properly manage it for a long period and expand the design without the use of external resources?
Automation to the rescue
Complexity of technology by itself should not pose a problem, its how you (are required to) interact with it that can lead to challenges. As mentioned before Multi-NIC vMotion requires multiple IP-addresses to function. On a side note this could put pressure on the IP-ranges as all vMotion enabled VMKnics inside the cluster requires being a part of the same network. Unfortunately routed vMotion is not supported yet. Every vMotion VMKnic needs to be configured properly, Pair this with availability requirements and the active and standby NIC configuration of each VMKnic can cause headaches if you want to have a consistent and identical network configuration across the cluster. Power-CLI and Host Profiles can help tremendously in this area.
Supporting documents
Now have you included these scripts in your documentation? Have you covered the installation steps on how to configure vMotion on a distributed switch? Make sure that these elements are included in your supporting documents!
What about the constraints and limitations?
Licensing
Unfortunately LBT is only available in distributed vSwitches, resulting in a top-tier licensing requirement if LBT is selected. The LBT configuration might be preferred over Multi-NIC vMotion configuration because it provides the least amount of complexity increase over the traditional configuration.
How does this intersect with the listed budget constraint and the customer is not able –or willing – to invest in enterprise licenses?
IP4 pressure
One of the listed constraints in the application form is the limited amount of IP addresses in the available IP range destined for the virtual infrastructure. This could impact your decision on which configuration to select. Would you “sacrifice” the amount of IP-s to get a better vMotion performance and all the related improvements on the remaining dependent features or is scalability and future expansion of your cluster more important? Remember scalability is also listed in the application form as a requirement.
Try this at home!
These are just an example of questions that can be asked during a defense. Try to find these answers when preparing for you VCDX panel. When finalizing the document set, try to do this exercise. Even better to find a group of your peers and try to review each others design while reviewing the application form and the supporting set of documents. At the Nordic VMUG Duncan and I spoke with a group of people that are setting up a VCDX study group, I think this is a great way of not only preparing for a VCDX panel but to learn and improve your skill set you can use in your daily profession.