In the article “Migrating datastore clusters by changing storage profiles in a vCloud“ I closed with the remark that vCD is not providing an option to migrate virtual machines between compute clusters that are part of an elastic vDC. Fortunately my statement was not correct. Tomas Fojta pointed out that vCD does provide this functionality. Unfortunately this feature is not exposed in the vCloud organization portal but in the system portal of the vCloud infrastructure itself. In other words, to be able to use this functionality you need to have system administrator privileges.
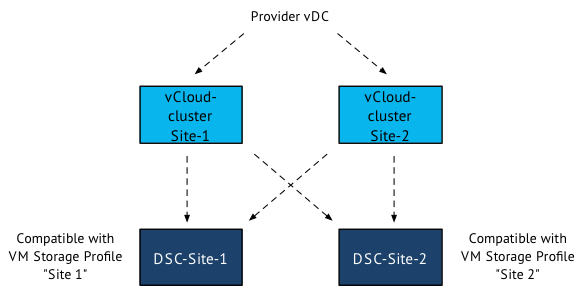
In the previous article, I created the scenario where you want to move virtual machines between two sites. Site 1 contains compute cluster “vCloud-Cluster1” and datastore cluster “ DSC-Site-1”. Site 2 contains “vCloud-Cluster2” and datastore cluster “DSC-Site-2” . By changing the VM storage profile from Site-1 to Site-2, we have vCD instruct vSphere to storage vMotion the virtual machine disk files from one datastore cluster to another. Now at this point we need to migrate the compute state of the virtual machine.
Migrate virtual machine between clusters
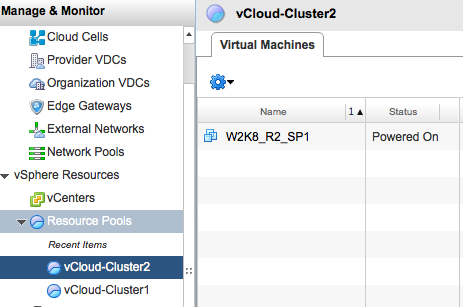
Please note that vCD refers to clusters as resource pools. To migrate the virtual machine between clusters, log into the vCloud director and select the system tab. Go to the vSphere resources and select Resource Pools menu option.
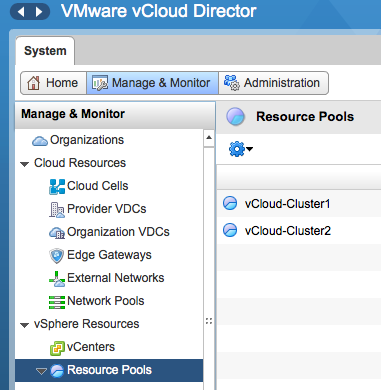
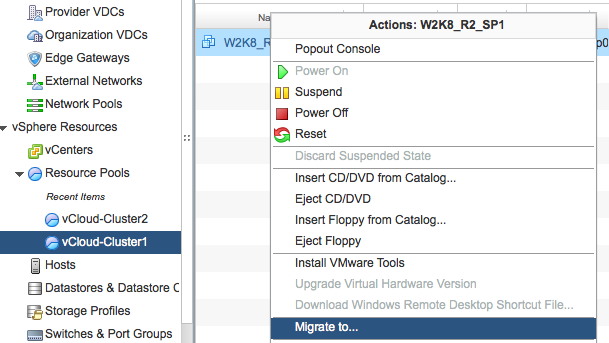
The UI displays the clusters that are a part of the Provide vDC. Select the cluster a.k.a. resource pool in which the virtual machine resides. Select the virtual machine to migrate, right click the virtual machine to have vCD display the submenu and select the option “Migrate to…”
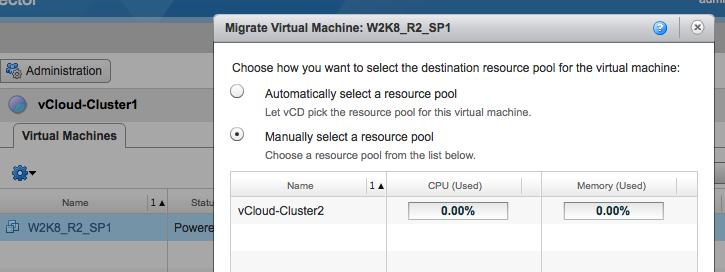
The user interface allows you to choose how you want to select the destination resource pool for the virtual machine: Either automatic and let vCD select the resource pool for you, or select the appropriate resource pool manually. When selecting automatic vCD selects the cluster with the most unreserved resources available. If the virtual machine happens to be in the cluster with the most unreserved resources available vCD might not move the virtual machine. In this case we want to place the virtual machine in site 2 so that means we need to select the appropriate cluster. We select vCloud-Cluster2 and click on OK to start the migration process.
vCD instructs vSphere to migrate the virtual machine between clusters with the use of vMotion. In order to use vMotion, both clusters need to have access to the datastore on which the virtual machine files reside. vCD does not use “enhanced’ vMotion where it can live migrate between host without being connected shared storage. Hopefully we see this enhancement in the future. When we log into vSphere we can verify if the life migration of the virtual machine was completed.
Select the destination cluster, in this case that would be vCloud-Cluster2, go to menu option Monitor, select tasks and click on the entry “Migrate virtual machine”
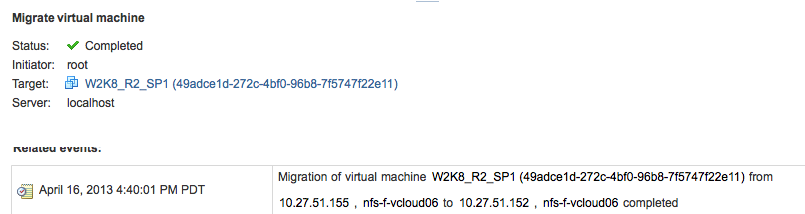
In the lower part of the screen, you get more detailed information of the Migrate-virtua-machine entry. As you can seem the virtual machine W2K8_RS_SP1 is migrated between servers 10.27.51.155 and 10.27.51.152. As we do not change anything to the storage configuration, the virtual machine files remains untouched and stay on the same datastore.
To determine if vCD has updated the current location of the virtual machine, log into vCD again, go to the menu option “Resource Pools” and select the cluster chosen as destination as the previously org cluster.
3 common questions about DRS preferential VM-Host affinity rules
On a regular basis I receive questions about the behavior of DRS when dealing with preferential VM to Host affinity rules. The rules configured with the rule set “should run on / should not run on” are considered preferential. Meaning that DRS prefers to satisfy the requirements of the rules, but is somewhat flexible to run a VM outside the designated hosts. It is this flexibility that raises questions; lets see how “loosely” DRS can operate within the terms of conditions of a preferential rule:
Question 1: If the cluster is imbalanced does DRS migrate the virtual machines out of the DRS host group?
DRS only considers migrating the virtual machines to hosts external to the DRS host group if each host inside the group is 100% utilized. And if the hosts are 100% utilized, then DRS will consider virtual machines that are not part of a VM-Host affinity rule first. DRS will always avoid violating an affinity rule
Question 2: When a virtual machine is powered on, will DRS start the virtual machine on a host external to the DRS host group?
By default DRS will start the virtual machine on hosts listed in the associated Host DRS group. If all hosts are 100% utilized – or – if they do not meet the virtual machine hardware requirements such as datastore or network connectivity, then DRS will start the virtual machine on a host external to the Host DRS group.
Question 3: If a virtual machine is running on a host external to the associated host DRS group, shall DRS try to migrate the virtual machine to a host listed in the DRS host group?
The first action DRS triggers during an invocation is to determine if an affinity rules is violated. If a virtual machine is running on a host external to the associated Host DRS group then DRS will try to correct this violation. This move will have the highest priority ensuring that this move is carried out during this invocation.
Migrating datastore clusters by changing storage profiles in a vCloud
vCloud director 5.1 supports the use of both storage profiles and Storage DRS. One of the coolest features and unfortunately relatively unknown is the ability to live migrate virtual machines between datastore clusters by changing the storage profile in the vCloud director portal.
In my lab I’ve set up a provider vDC that contains two compute clusters. Each compute cluster connects to two datastore clusters. Datastore Cluster “vCloud-SDC-Gold” is compatible with the VM storage profile “vCloud-Gold-Storage”, while Datastore Cluster “vCloud-SDC-Silver” is compatible with the VM storage profile “vCloud-Silver-Storage”.
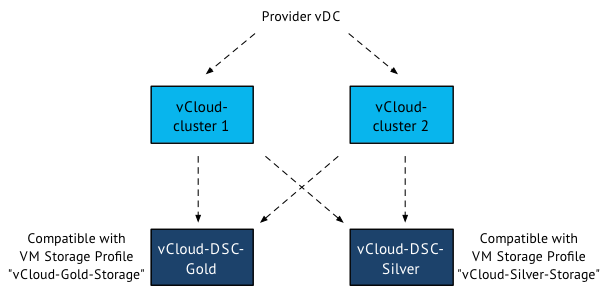
When creating a vApp the default storage profile of the organization vDC is applied to the vApp and all its virtual machines. In this case, the VM storage profile Gold is applied to all the virtual machines in the vApp.
You can determine which VM Storage Profile is associated with the virtual machine by selecting the properties of the virtual machine in the “My Cloud” tab. Please note that vCloud Director does not show the VM Storage Profile at the vApp level!
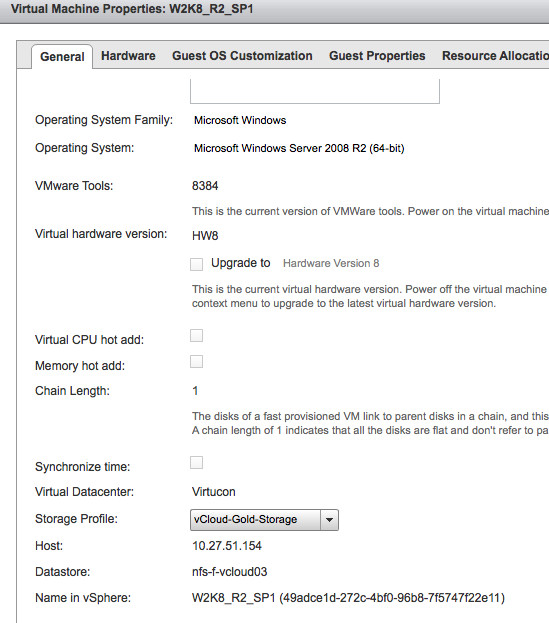
By selecting the drop-down box, all storage profiles that are associated with the organization vCD are displayed.
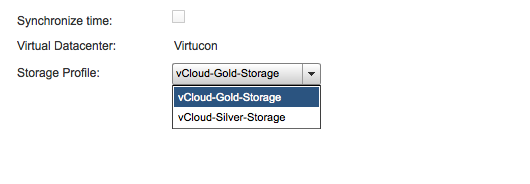
By selecting the Storage Profile “vCloud-Silver-Storage” vCloud Director determines that the virtual machine is stored on a datastore that is not compatible with the associated storage profile. In other words the current configuration is violating the storage level policy.
To correct this violation, vCloud director instructs vSphere to migrate the virtual machine via Storage vMotion to a datastore that is compatible with the VM storage Profile. In this case the datastore cluster “vCloud-DSC-Silver” is selected as the destination. Storage DRS determines the most suitable datastore by using its initial placement algorithm and selects the datastore that has the most amount of free space and the lowest I/O load.
To demonstrate the feature, I selected the virtual machine “W2K8_R2-SP1”. The VM storage profile “vCloud-Gold-Storage” is applied and Storage DRS determined that the datastore “nfs-f-vcloud03” of the datastore cluster “vCloud-DSC-Gold” was the most suitable location.
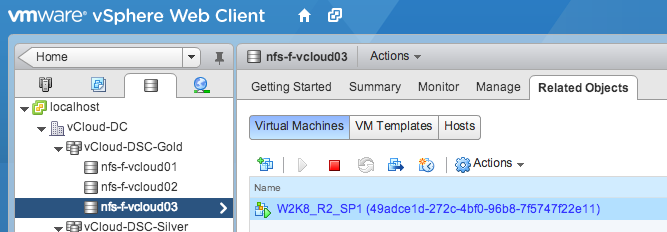
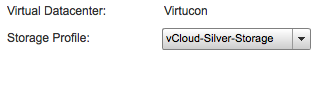
By changing the Storage Profile to “vCloud-Silver-Storage” vCloud director instructed vSphere to migrate it to the datastore cluster that is compatible with the newly associated VM storage profile.
When logging into the vCenter server managing the ESXi hosts the following task is running:
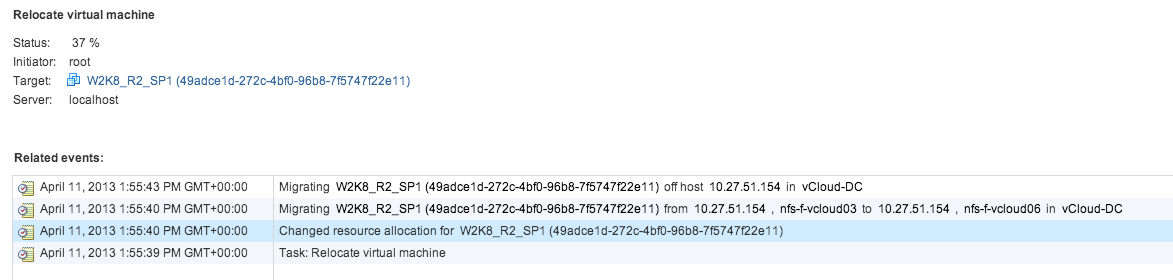
After the task is complete, vCenter shows that the virtual machine is now stored on datastore “nfs-f-vcloud06” in the datastore cluster “vCloud-DSC-Silver”.
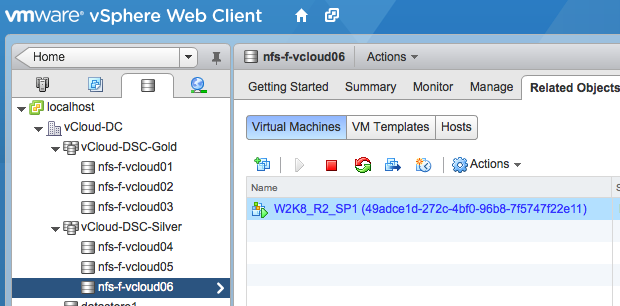
The power of abstraction
The abstraction layer of vCloud Director makes this possible. When changing the storage profile directly on the vSphere layer, nothing happens. vSphere will not migrate the virtual machine to the appropriate datastore cluster that is compatible with the selected VM storage profile.
Useful for stretched clusters?
The reason why I was looking into this feature in my lab is due to an conversation with my esteemed colleagues Lee Dilworth and Aidan Dalgleish. We were looking to an alternative scenario for a stretched cluster. By leveraging the elastic vDC feature of vCloud director, a seperate DRS cluster is created in each site. Due to the automatic initial placement engine on the compute level, we needed to find a construct that can provide us a more deterministic method of virtual machine placement. We immediately thought of the VM profile storage feature. Create two datastore clusters, one per site and associate a profile storage based on site name to the respective datastore clusters.
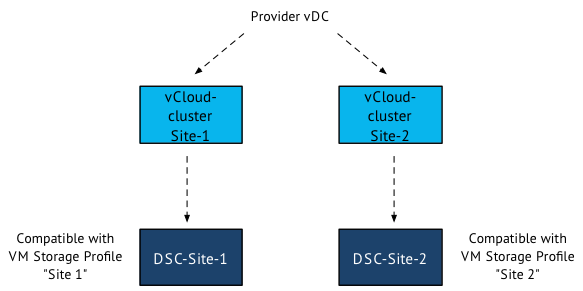
When creating the vApp, just select the site-related Storage Profile to place the virtual machine in a specific site. Due to the compatibility check, vCloud Director determines that in order to be compliant with the storage profile it places the virtual machine on the compute cluster in the same site. For example, if you want to place a virtual machine in site 1, select the VM storage Profile “site 1”. vCloud director determines that the virtual machine needs to be stored in datastore cluster “DSC-Site-1”. The compute cluster Site-1 is the only compute cluster connected to the datastore cluster, therefor both the compute and storage configuration of the virtual machine is stored in Site 1.
This configuration works perfect if you want to simplify initial placement if you have multiple sites/locations and you always want to keep the virtual machine in the same site. However this solution might not be optimal for a Stretched cluster configuration where failover to another site is necessary.
Connectivity to all datastores necessary
As this feature uses storage vMotion instead of cross-host/datastore vMotion, means that the cluster needs to be connected to both datastore clusters.
When selecting the different storage profile, the storage state is migrated to another datastore cluster. However it doesn’t move the compute state of the virtual machine. This means that storage is moved to site B, while the compute state is still in Site A. vCloud director does not provide an option to migrate the virtual machine to a different compute cluster within the provider vDC. You can either solve it by logging into the vCenter server that manages the ESXi hosts and manually vMotion the virtual machines to cluster in Site B, or power-off the virtual machine in vCloud Director, then change the storage profile and power-on the virtual machine. Both “solutions” are not very enterprise-level scenario’s therefor I think this is not yet suitable as a stretched cluster configuration
VMworld 2013 – Call of Papers deadline ends today
Just a reminder here on submitting VMworld sessions. The deadline is coming up quickly.
If you haven’t submitted yet, you have still some hours left to submit a Session Proposal for VMworld 2013.
Submit your session today!
vMotion over layer 3?
This question regularly pops up on twitter and the community forums. And yes it works but VMware does not support vMotion interfaces in different subnets.
The reason is that this can break functionality in higher-level features that rely on vMotion to work.
If you think Routed vMotion (vMotion interfaces in different subnets) is something that should be available in the modern datacenter, please fill out a feature request. The more feature requests we receive; the more priority can be applied to the development process of the feature.