A couple of months ago I joined the Office of the CTO of the Cloud Platform Business Unit and started reporting directly to the CTO, Kit Colbert. Kit asked me to select a few areas to focus on. One of these areas is running Kubernetes on vSphere.
I’ve increased my focus on Kubernetes, as this architecture becomes increasingly important in the datacenter. When talking to customers, two questions I ask is, what is the current ratio of VMs to containers in your
The standard tool for developers is container-based infrastructure
At VMworld in Las Vegas, Michael Gasch and I presented the session “Deep Dive: The Value of Running Kubernetes on vSphere” (CNA1553BU). If you are not going to VMworld Europe, I recommend watching the video recording, if you are going to VMworld Europe I recommend you to sign up.
One thing you can expect from me is more Kubernetes focused articles. One of the
things that I noticed is that many articles are written by cloud-native natives
for cloud-native natives. I.e. they rely on extensive previous exposure to this
ecosystem. I’m trying to cover some of the challenges I have faced and the
quirks I notice as a “newcomer”.
Help Us Make vMotion Even Better
The vMotion product team is looking for input on how to improve vMotion. vMotion has proven to be a paradigm shift of datacenter management. Workload mobility is a must-have requirement in today’s datacenter operational model. vMotion handles the majority of workload flawlessly. H
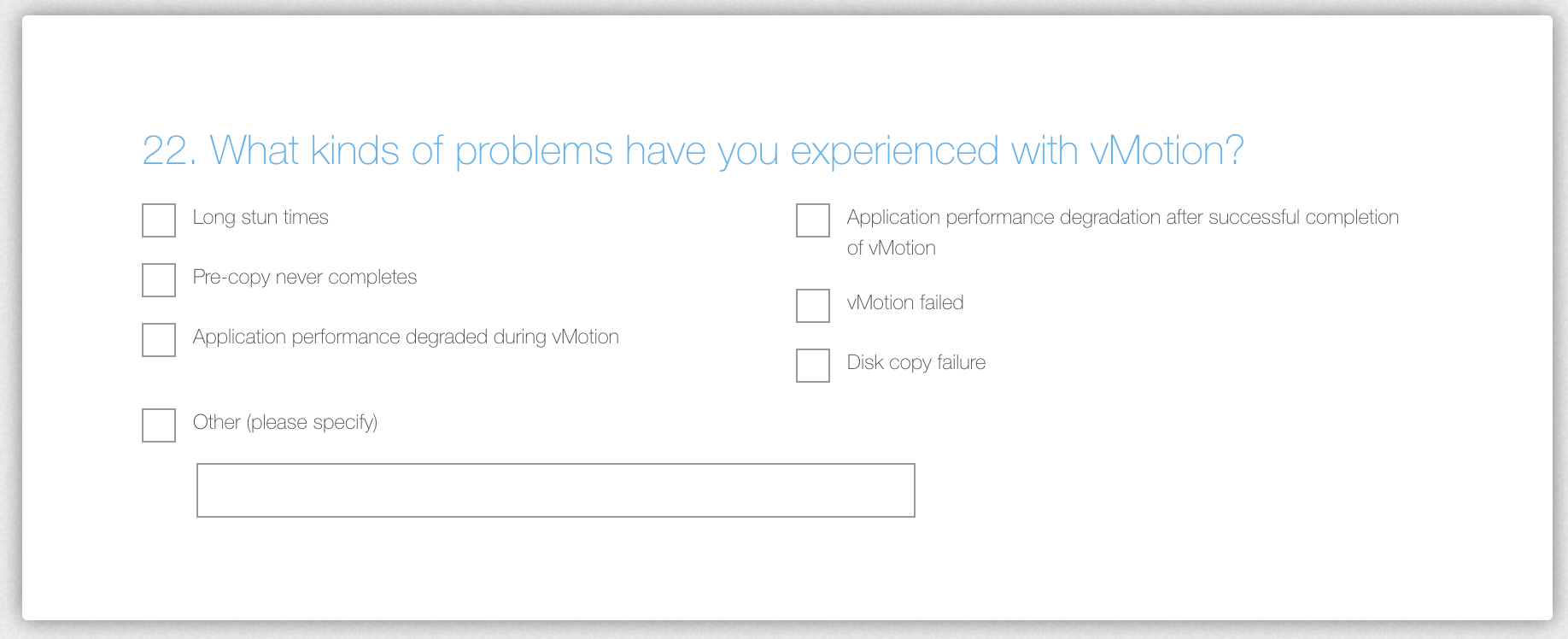
It would be very helpful if you can provide us with some more information to make vMotion even better. Thanks!
Take the survey here
Terminal Affinity Poll
We are looking into the combination of licensed workload and hard-affinity rules (Must run on rule). If you deploy this in your environment right now, how do you deal with this during maintenance hours? Your input helps in shaping future features. (Scroll down in the survey window to access the done button to submit your response)
Six Interesting Kubernetes Sessions at VMworld 2018
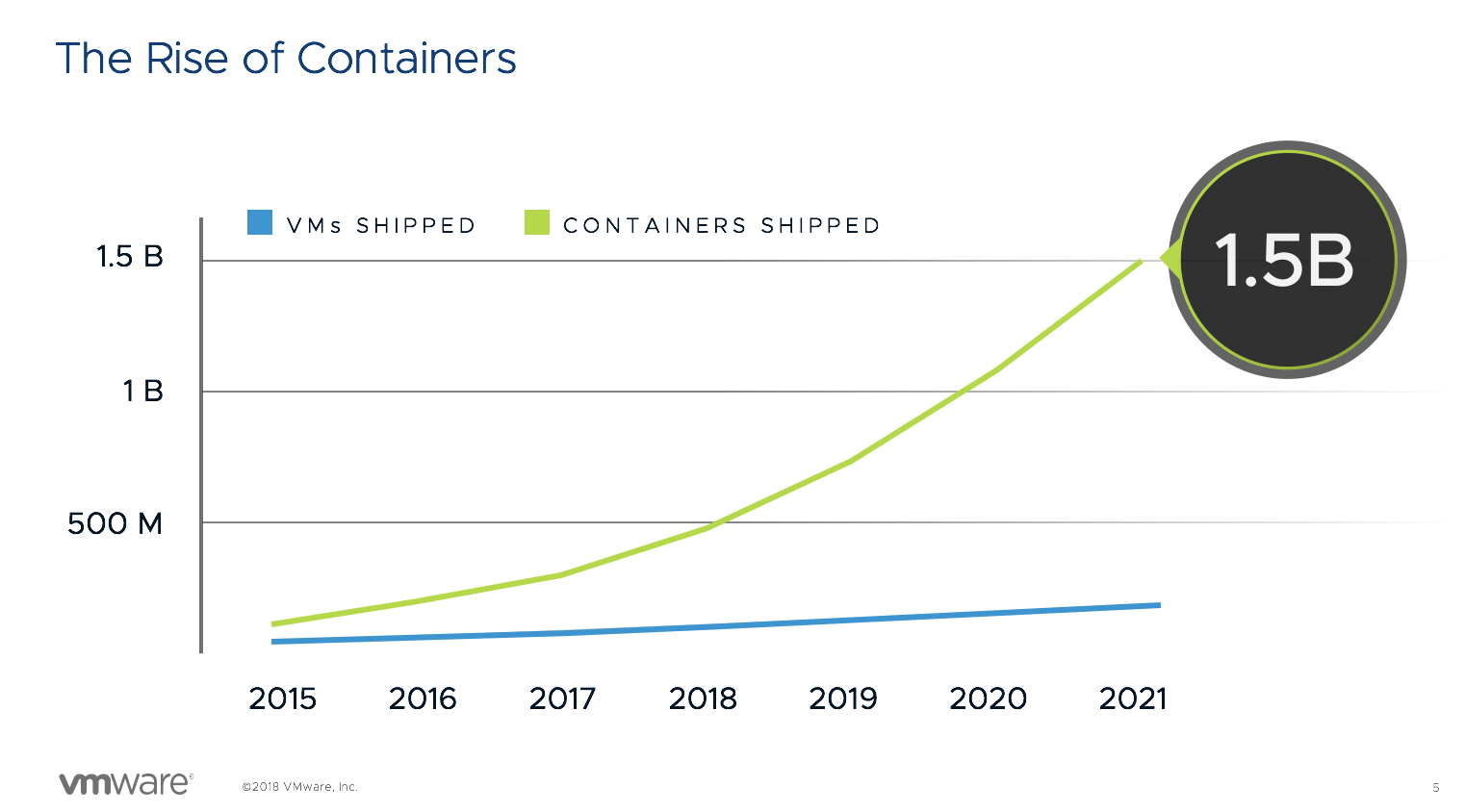
This year VMworld provided a broad selection of talks focusing on various forms of Kubernetes. Which is not surprising at all. Many organizations move away from buying and installing shrink-wrapped software and move towards in-house built custom applications. And what is the modern developer tool of choice? For many, it is the container. It’s expected to have 1.5 Billion containers shipped by the end of 2021.
Containers are nothing more than a new format of virtualized workload. Michael Gasch explains it very well in our session Deep Dive: The Value of Running Kubernetes on vSphere (CNA1553BU), where containers are task structs in the Linux kernel, not very different than executing an LS command. Well, a bit more than that as containers require CPU, memory, network, storage, and security.
Containers satisfy the developers’ need for speed, and they remove dependencies on underlying operating systems. When deploying massive amounts of containers, you need a container management platform, and Kubernetes is clearly the defacto standard in the industry.

Source: Cloud Native Computing Foundation
For the infrastructure team, running Kubernetes can provide a way to create an infrastructure agnostic platform. That is, it can run on any cloud. VMware is fully vested in making this happen; you can run containers natively (VIC), containers and Kubernetes in Linux VMs on vSphere. Pivotal Container Service (PKS) on-prem or in-cloud that helps customer deploy and operationalize day 1 and day 2 kubernetes solution and VMware Kubernetes Engine (VKE) (Kubernetes as a Service) for organizations who want to consume Kubernetes without owning, building or operationalizing any infrastructure.
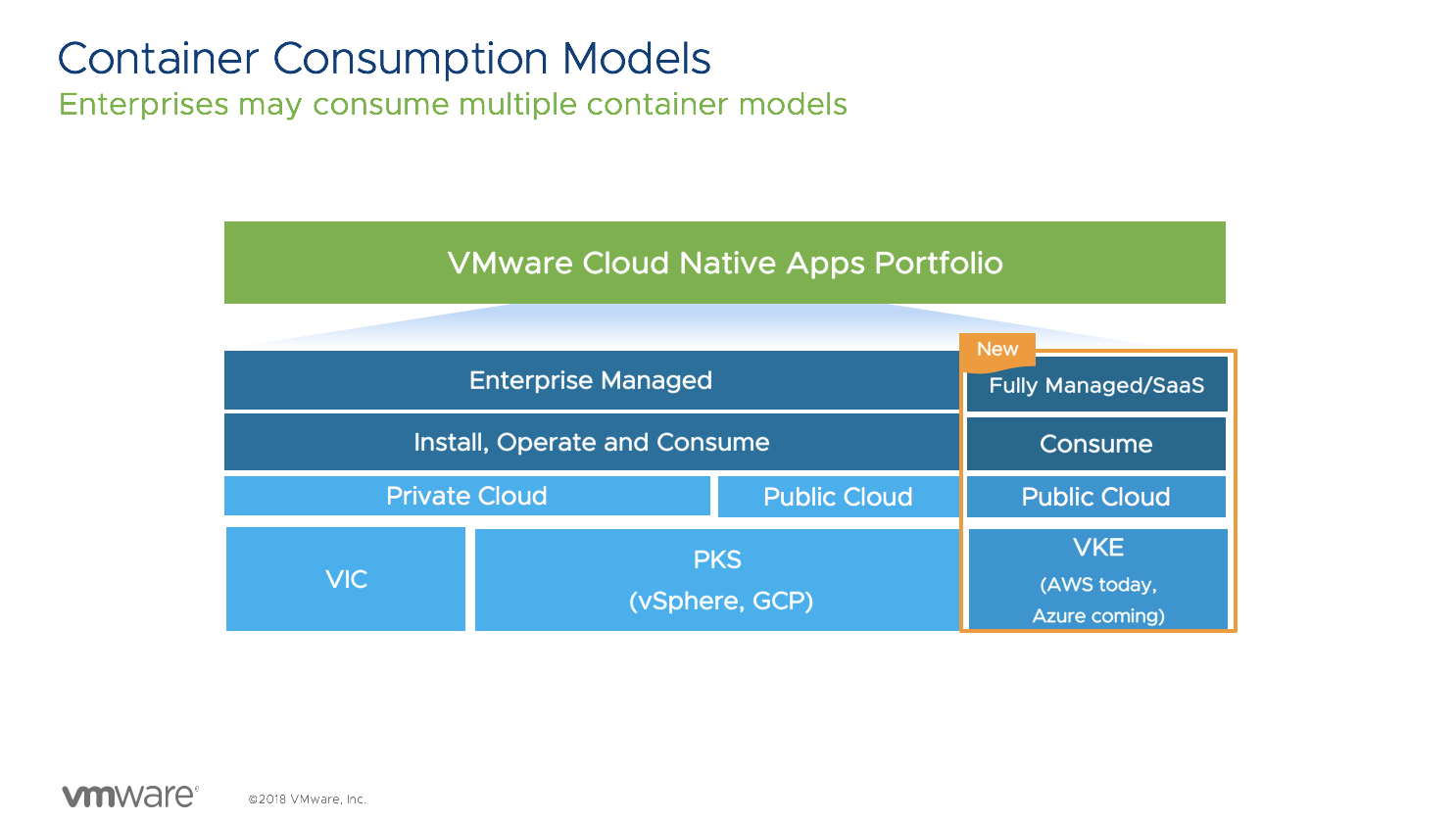
I’ve selected a few VMworld sessions that cover these container consumption models. There are many more, and please check them out at the VMworld On-Demand Video Library.
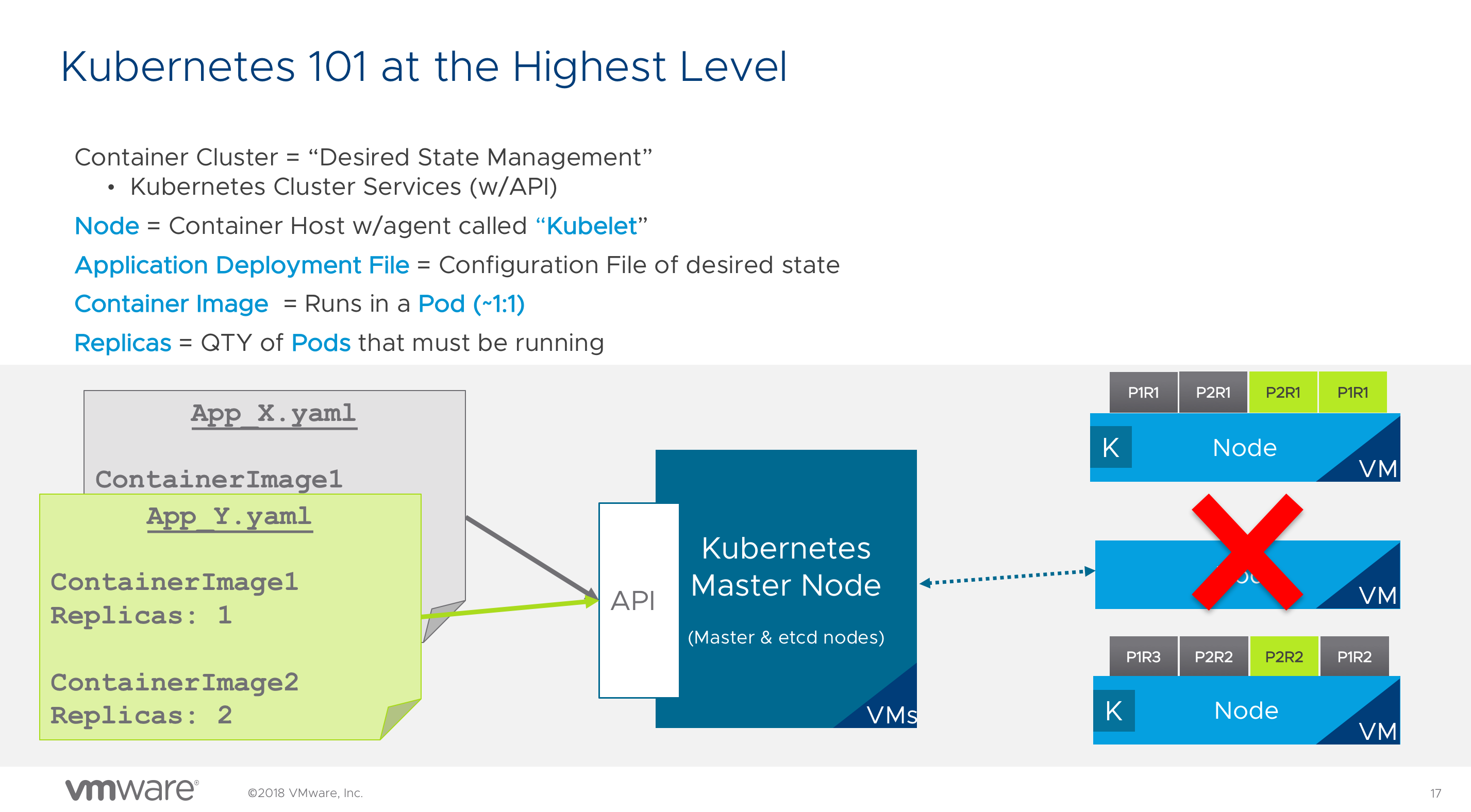
Container and Kubernetes 101 for vSphere Admins (CNA1564BU)
A very popular session at VMworld was the 101 session for vSphere Admins. Nathan Ness and Sachin Thatte go over the basics of Container, Kubernetes and Pivotal Container Services. A very helpful primer for the rest of the listed videos. (Watch here)
Running Kubernetes on vSphere Deep Dive: The Value of Running Kubernetes on vSphere (CNA1553BU)
Michael Gasch (Resident Kubernetes Expert at VMware) and I go over the reasons why vSphere and Kubernetes are better together. We provide guidelines on how to successfully run your Kubernetes environment.
(Watch Here)

A Deep Dive on Why Storage Matters in a Cloud-Native World (HCI1813BU)
7 out of 10 applications that run in containers are stateful applications (source: Datadog), you want to provide persistent storage. Myles and Tushar talk about project Hatchway and provide a preview of the upcoming Cloud Native Storage (CNS) Control plane.
(Watch Here)
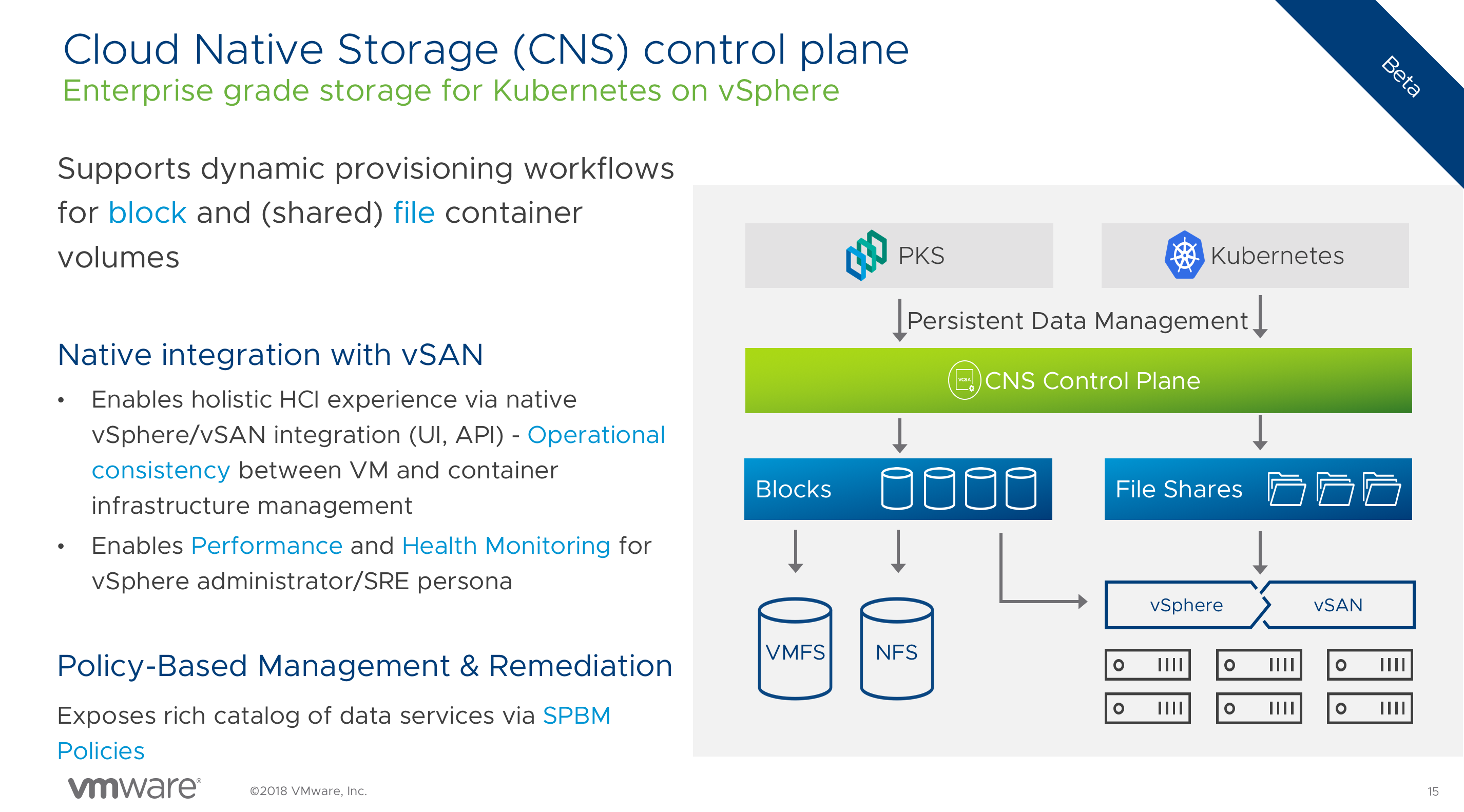
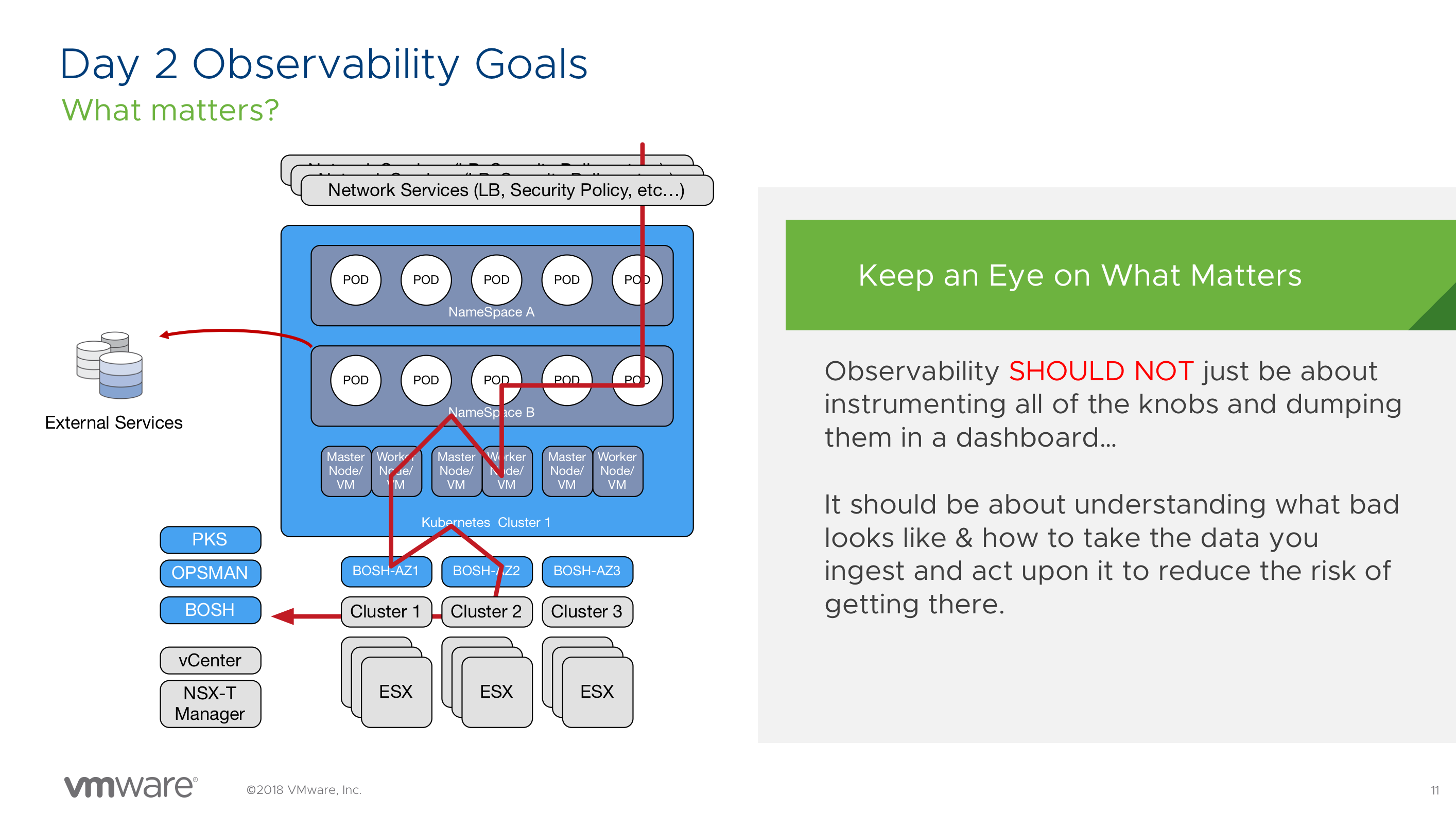
Operating and Managing Kubernetes on Day 2 with PKS (CNA1075BU)
If you are planning to run large-scale kubernetes deployments on-prem, you should consider Pivotal Container Service (PKS). PKS allows you to deploy multiple kubernetes clusters quite easily. Thomas Kraus and Merlin Glynn show how to tackle day 2 operations and review SDDC products, such as vRealize and Wavefront, that integrates with PKS.
(Watch Here)
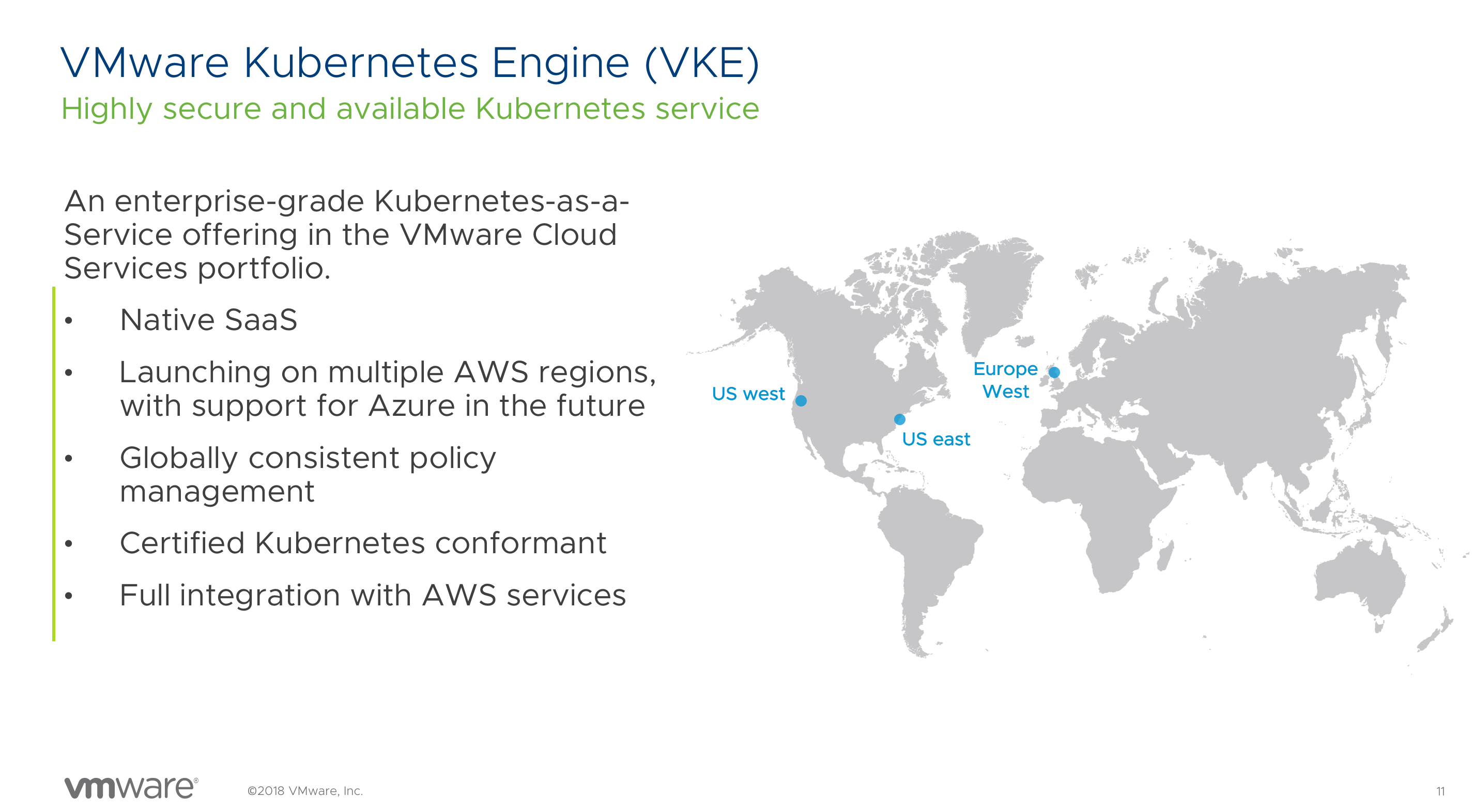
VMware Kubernetes Engine
VMware Kubernetes Engine (VKE) offers a turn-key solution of managed Kubernetes clusters that run natively on AWS. Not in VMware Cloud on AWS, not on vSphere, pure native EC2! Plans are to run VKE at multiple cloud providers, allowing you to create environments that no-other cloud provider themselves can provide. Think about an HA cluster spanning both AWS and Azure. However, we are not that far right now, but it is interesting to take a look at what VKE is and how Smart Clusters will change the way you will operate Kubernetes.
Intro to VMware Kubernetes Engine-Managed K8s Service on Public Cloud (CNA2084BU)
Tom and Valentina go over the concepts and customer value of VKE, including a nice demo. (Watch Here)
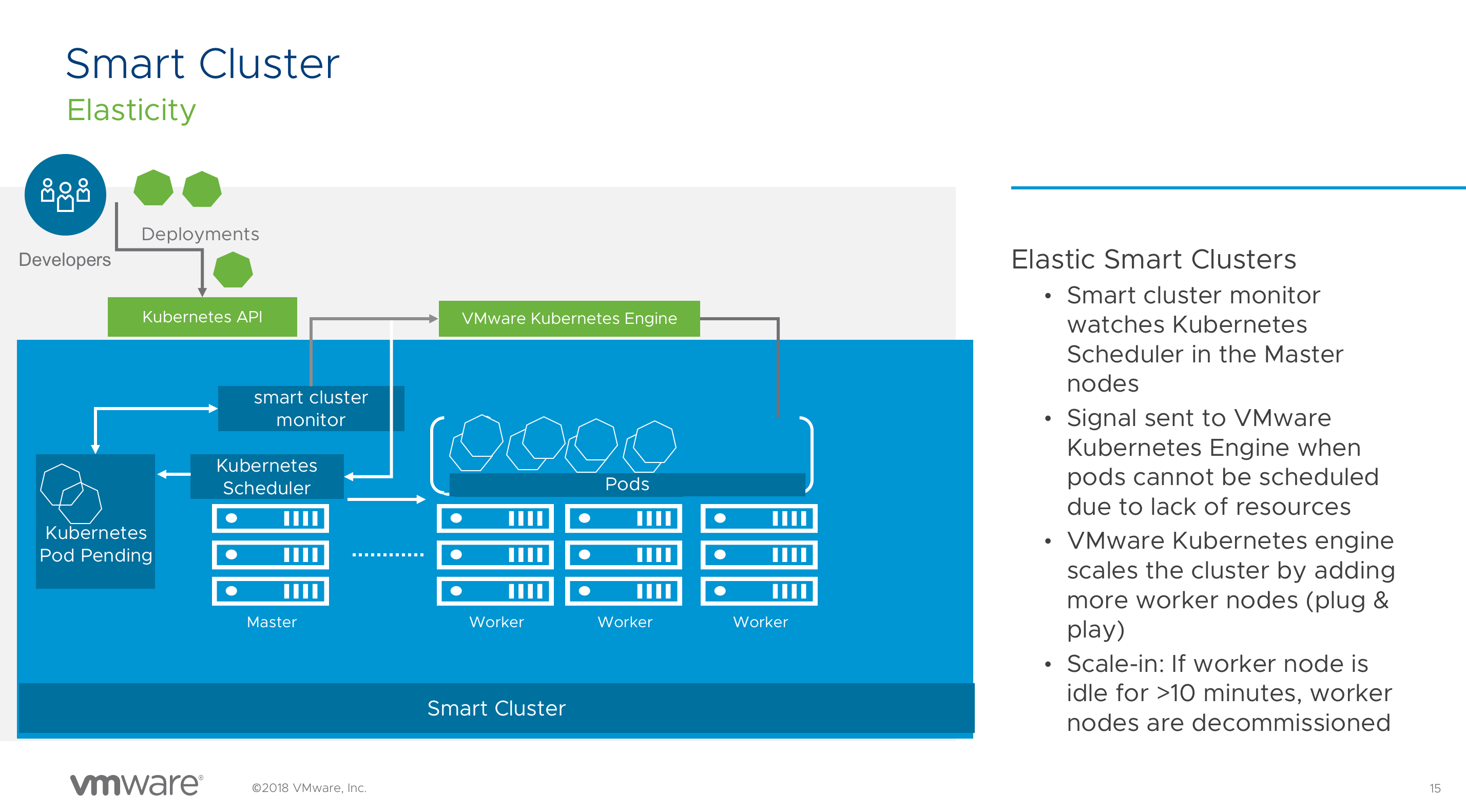
Deep Dive: VMware Kubernetes Engine-K8s as a Service on Public Cloud (CNA3124BU)
After getting familiar with VKE, I recommend to watch the session of Tom and Alain. They dive deeper into the concept of Smart Clusters. (Watch Here)
I hope you enjoy watching these sessions, please leave a comment about sessions you think are worth watching.
Tech Paper DRS Enhancements in vSphere 6.7
During VMworld, the DRS performance team released a new tech paper covering the DRS Enhancements in vSphere 6.7. It’s a short white paper uncovering the interesting improvements made to DRS. Download it here.