
#47 – How VMware accelerates customers achieving their net zero carbon emissions goal
In episode 047, we spoke with Varghese Philipose about VMware’s sustainability efforts and how they help our customers meet...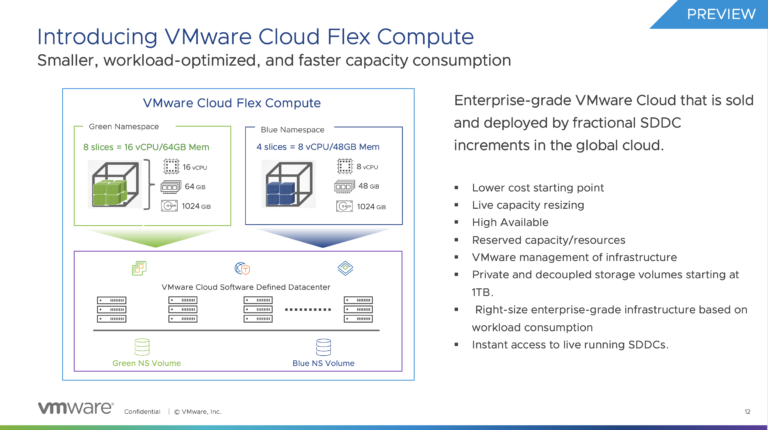
#46 – VMware Cloud Flex Compute Tech Preview
We’re extending the VMware Cloud Services overview series with a tech preview of the VMware Cloud Flex Compute service....
VMware Cloud Services Overview Podcast Series
Over the last year, we’ve interviewed many guests, and throughout the Unexplored Territory Podcast show, we wanted to provide...
Research and Innovation at VMware with Chris Wolf
In episode 042 of the Unexplored Territory podcast, we talk to Chris Wolf, Chief Research and Innovation Officer of...
Gen AI Sessions at Explore Barcelona 2023
I’m looking forward to next week’s VMware Explore conference in Barcelona. It’s going to be a busy week. Hopefully, I will...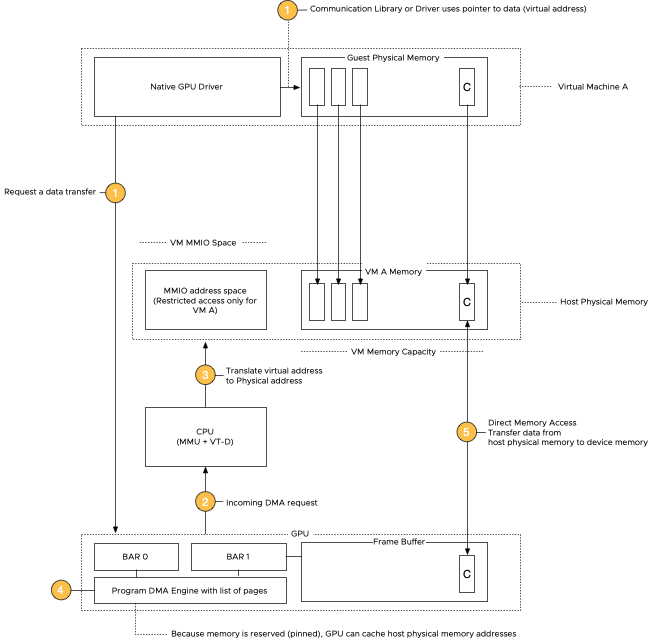
vSphere ML Accelerator Spectrum Deep Dive – ESXi Host BIOS, VM, and vCenter Settings
To deploy a virtual machine with a vGPU, whether a TKG worker node or a regular VM, you must enable some...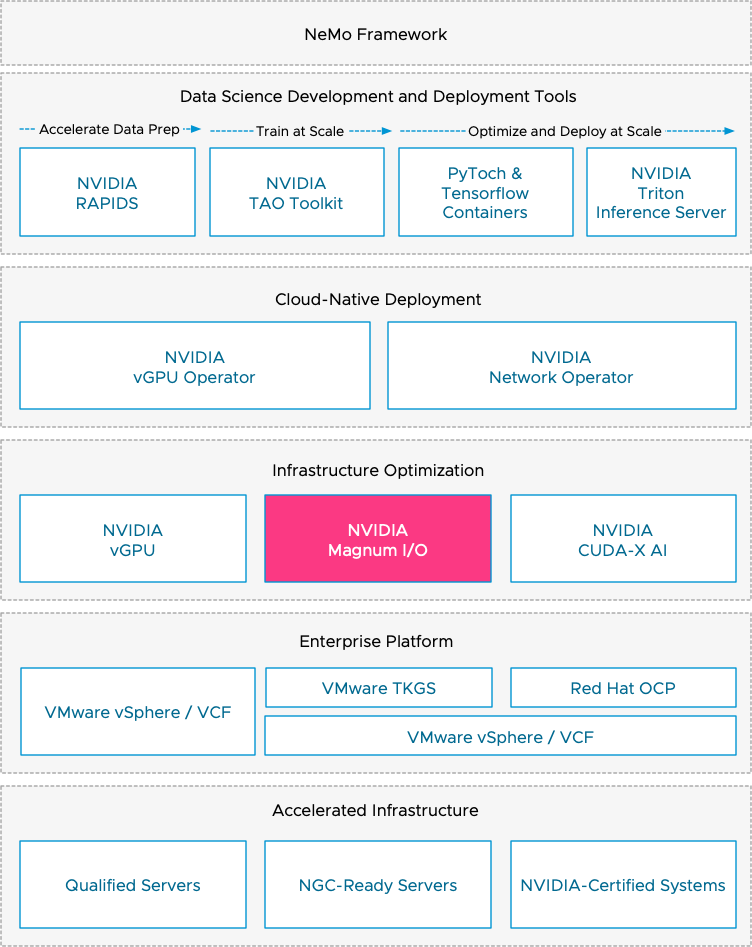
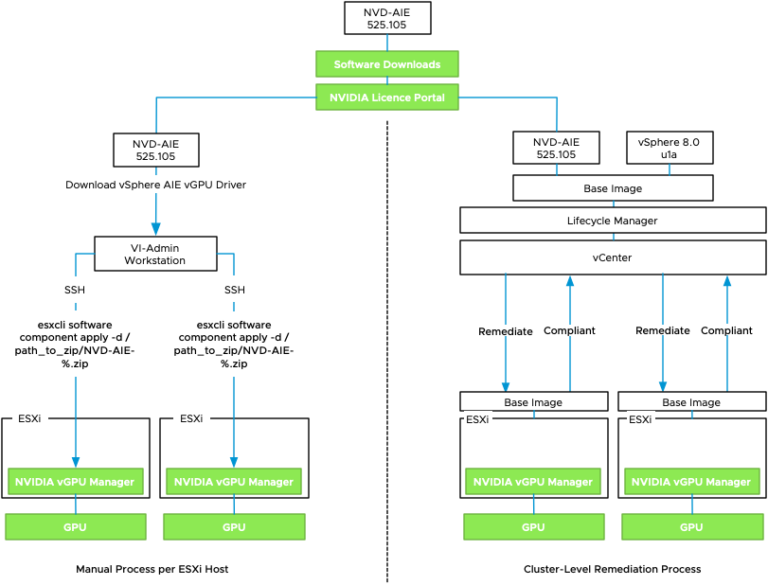
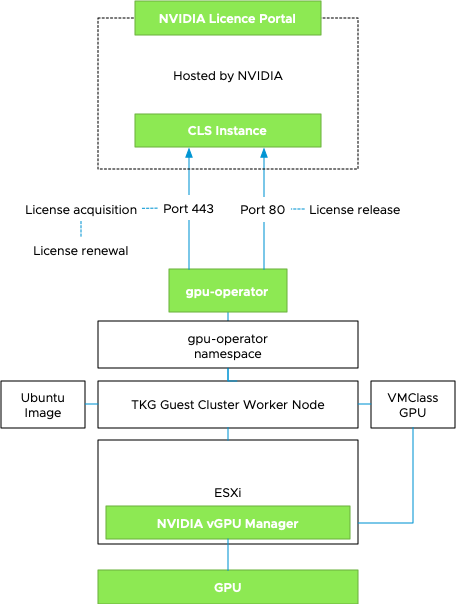
vSphere ML Accelerator Spectrum Deep Dive –NVIDIA AI Enterprise Suite
vSphere allows assigning GPU devices to a VM using VMware’s (Dynamic) Direct Path I/O technology (Passthru) or NVIDIA’s vGPU technology. The...All Stories
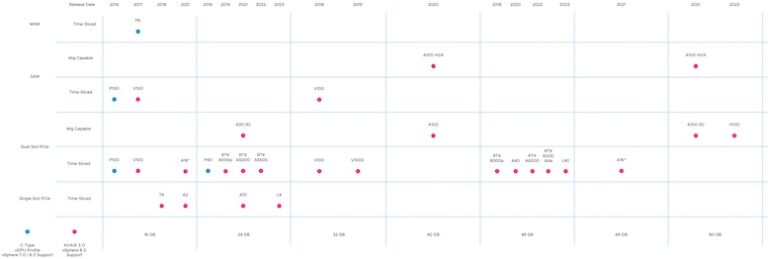
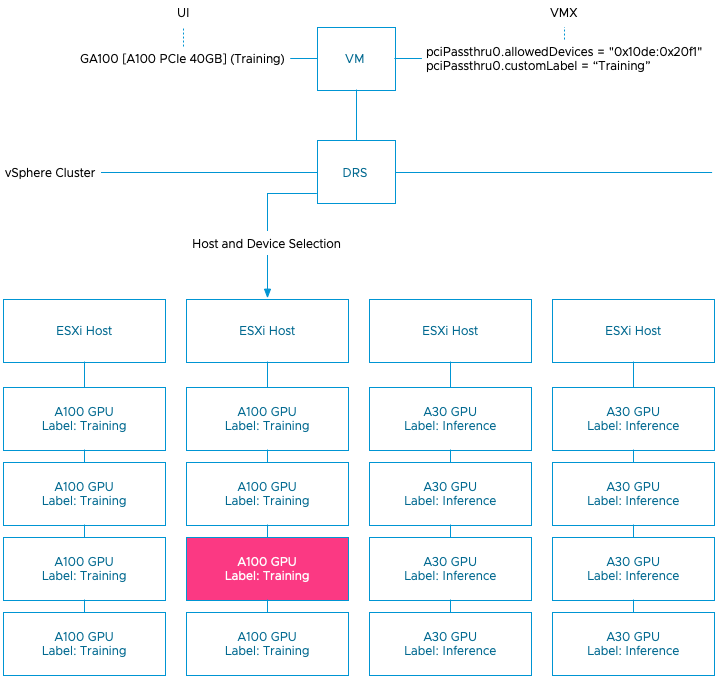
vSphere ML Accelerator Spectrum Deep Dive – GPU Device Differentiators
The two last parts reviewed the capabilities of the platform. vSphere can offer fractional GPUs to Multi-GPU setups, catering to the...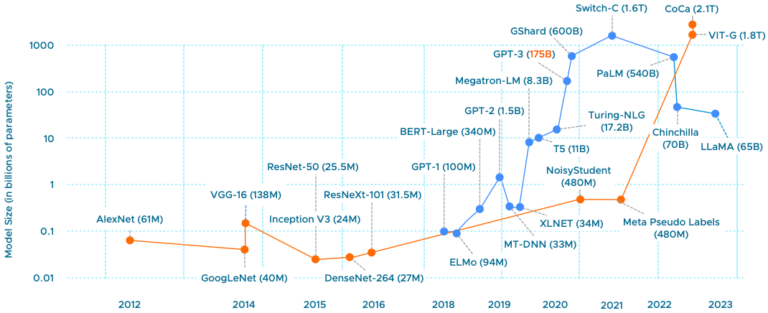
vSphere ML Accelerator Spectrum Deep Dive for Distributed Training – Multi-GPU
The first part of the series reviewed the capabilities of the vSphere platform to assign fractional and full GPU to workloads....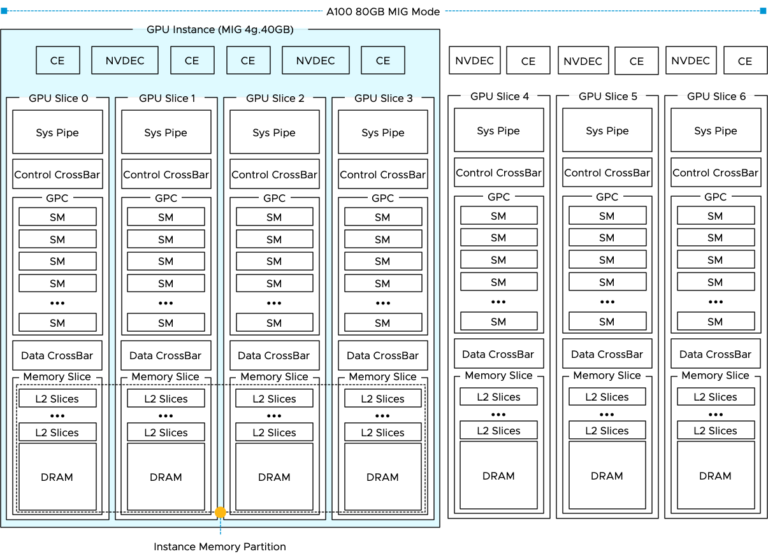
vSphere ML Accelerator Deep Dive – Fractional and Full GPUs
Many organizations are building a sovereign ML platform that aids their data scientist, software developers, and operator teams. Although plenty of...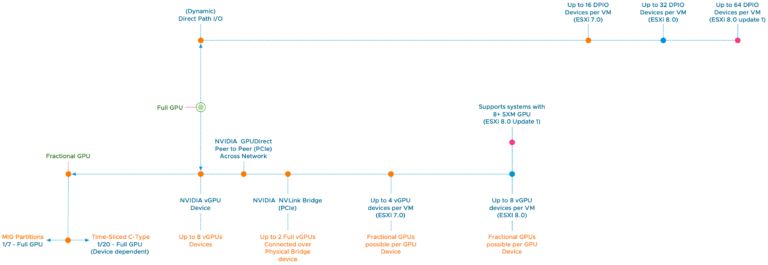
vSphere ML Accelerator Spectrum Deep Dive Series
The number of machine learning workloads is increasing in on-prem data centers rapidly. It arrives in different ways, either within the...
vSphere 8.0 Update 1 Enhancements for Accelerating Machine Learning Workloads
Recently vSphere 8 Update 1 was released, introducing excellent enhancements, ranging from VM-level power consumption metrics to Okta Identity Federation for...
My Picks for NVIDIA GTC Spring 2023
This week GTC Spring 2023 kicks off again. These are the sessions I look forward to next week. Please leave a...
Discover what’s new in vSphere 8.0 U1 and vSAN 8.0 U1
We (the Unexplored Territory team) work with the vSphere release team to get you the latest information about the new releases...
Simulating NUMA Nodes for Nested ESXi Virtual Appliances
To troubleshoot a particular NUMA client behavior in a heterogenous multi-cloud environment, I needed to set up an ESXi7.0 environment. Currently,...
Sapphire Rapids Memory Configuration
The 4th generation of the Intel Xeon Scalable Processors (codenamed Sapphire Rapids) was released early this year, and I’ve been trying...