

#47 – How VMware accelerates customers achieving their net zero carbon emissions goal
In episode 047, we spoke with Varghese Philipose about VMware’s sustainability efforts and how they help our customers meet...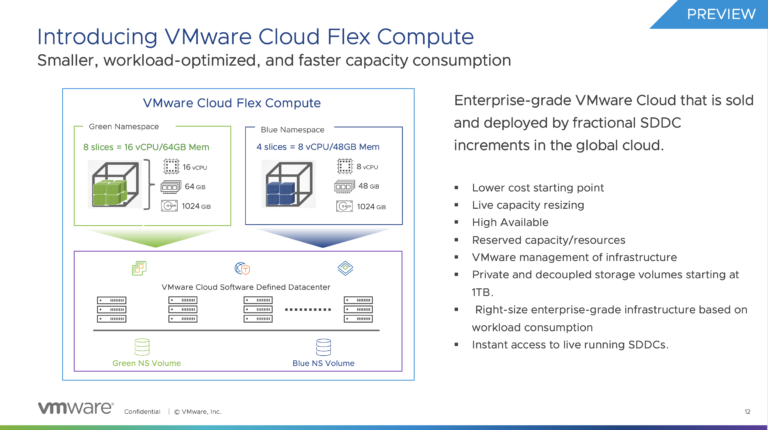
#46 – VMware Cloud Flex Compute Tech Preview
We’re extending the VMware Cloud Services overview series with a tech preview of the VMware Cloud Flex Compute service....
VMware Cloud Services Overview Podcast Series
Over the last year, we’ve interviewed many guests, and throughout the Unexplored Territory Podcast show, we wanted to provide...
Research and Innovation at VMware with Chris Wolf
In episode 042 of the Unexplored Territory podcast, we talk to Chris Wolf, Chief Research and Innovation Officer of...
Gen AI Sessions at Explore Barcelona 2023
I’m looking forward to next week’s VMware Explore conference in Barcelona. It’s going to be a busy week. Hopefully, I will...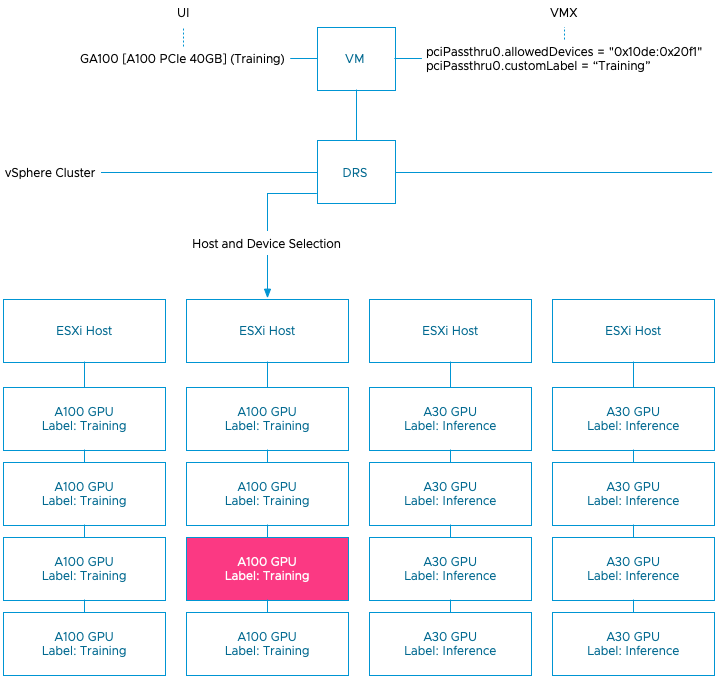
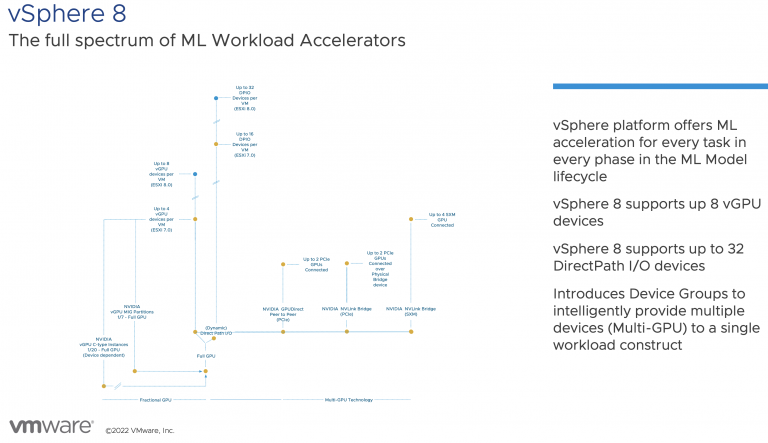
vSphere ML Accelerator Spectrum Deep Dive – Using Dynamic DirectPath IO (Passthrough) with VMs
vSphere 7 and 8 offer two passthrough options, DirectPath IO and Dynamic DirectPath IO. Dynamic DirectPath IO is the vSphere brand...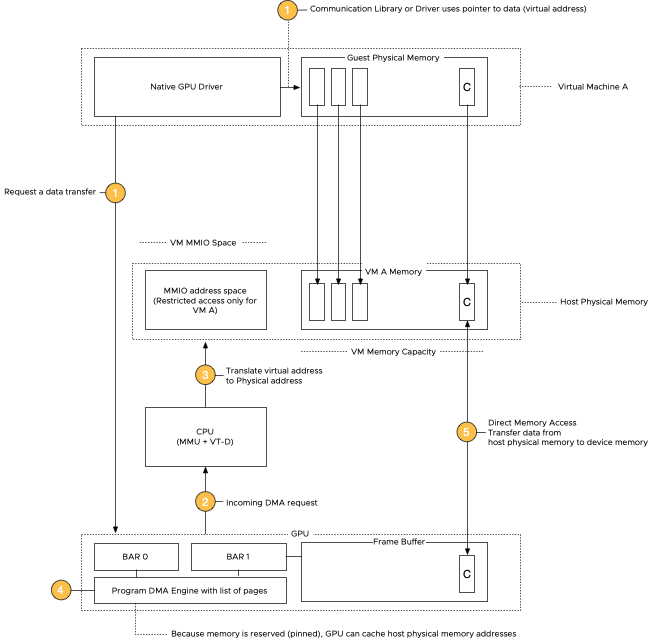
vSphere ML Accelerator Spectrum Deep Dive – ESXi Host BIOS, VM, and vCenter Settings
To deploy a virtual machine with a vGPU, whether a TKG worker node or a regular VM, you must enable some...All Stories
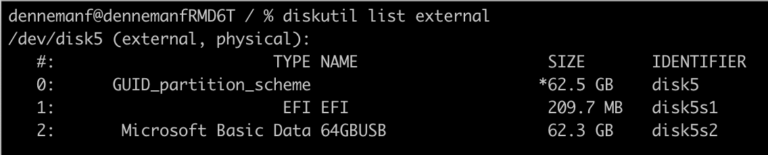
How to Create a Windows 11 Bootable USB on Mac OS Monterey
I need to install Windows 11 on a gaming PC, but I only have a MacBook in my house, as this...
Unexplored Territory Ep 34 – William Lam Talks Home Labs – Christmas Special
It’s the end of the year, and everybody is winding down from a hectic year, so we wanted to give you...
Unexplored Territory Podcast 32 – IT giving McLaren Racing the edge
Edward Green, Head of Commercial Technology at McLaren Racing, keynoted at the VMware Explore tech conference in Barcelona. I had the...ML Session at CTEX VMware Explore
Next week during VMware Explore, VMware is also organizing the Customer Technical Exchange. I’m presenting the session “vSphere Infrastructure for Machine...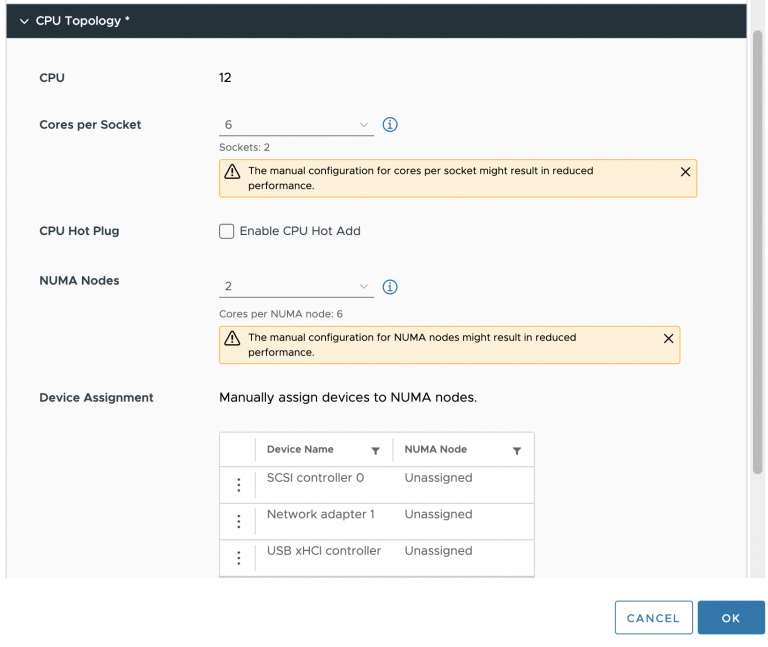
vSphere 8 CPU Topology for Large Memory Footprint VMs Exceeding NUMA Boundaries
By default, vSphere manages the vCPU configuration and vNUMA topology automatically. vSphere attempts to keep the VM within a NUMA node...
Unexplored Territory Podcast EP30 – Project Keswick with Alan Renouf
While preparing the podcast, I knew this episode would be good. Edge technology immensely excites me, and the way the project...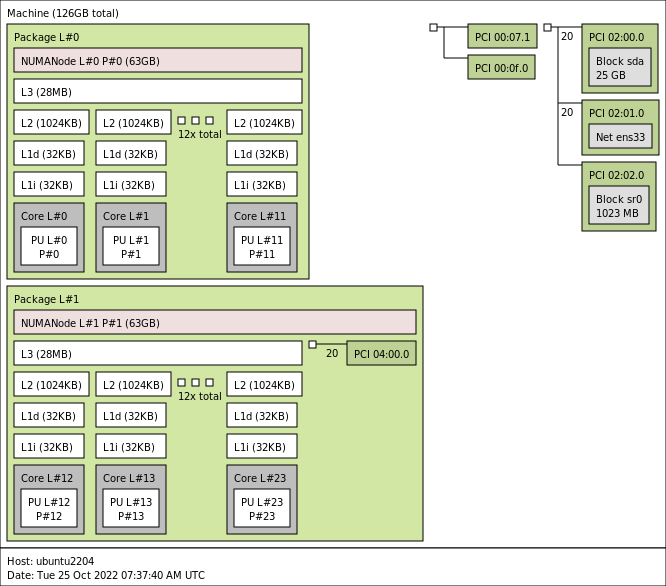
vSphere 8 CPU Topology Device Assignment
There seems to be some misunderstanding about the new vSphere 8 CPU Topology Device Assignment feature, and I hope this article...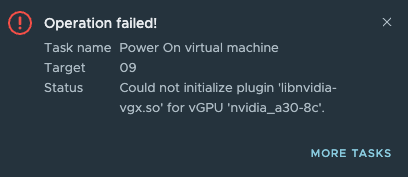
Could not initialize plugin ‘libnvidia-vgx.so – Check SR-IOV in the BIOS
I was building a new lab with some NVIDIA A30 GPUs in a few hosts, and after installing the NVIDIA driver...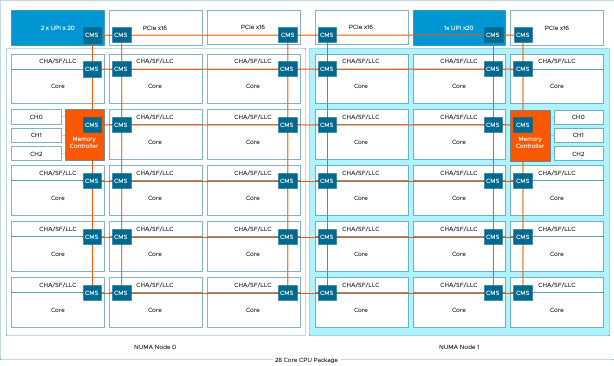
Sub-NUMA Clustering
I’m noticing a trend that more ESXi hosts have Sub-NUMA Clustering enabled. Typically this setting is used in the High-Performance Computing...